
1、应用场景
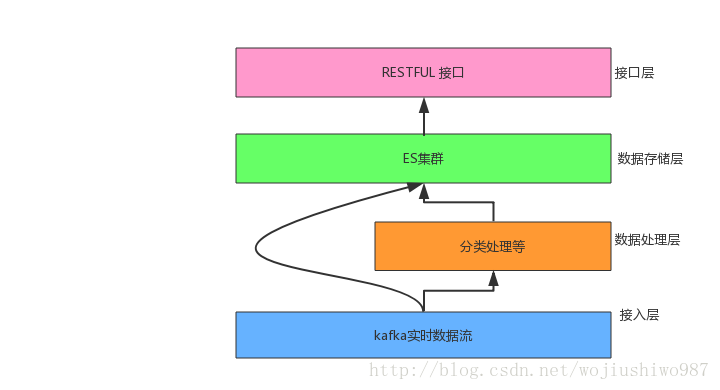
实时数据流通过kafka后,根据业务需求,一部分直接借助kafka-connector入Elasticsearch不同的索引中。
另外一部分,则需要先做聚类、分类处理,将聚合出的分类结果存入ES集群的聚类索引中。如下图所示:
业务系统的分层结构可分为:接入层、数据处理层、数据存储层、接口层。
那么问题来了?
我们需要基于聚合(数据处理层)的结果实现检索和聚合分析操作,如何实现更快的检索和更高效的聚合分析效果呢?
2、方案选型
方案一:
只建立一个索引,aggs_index。
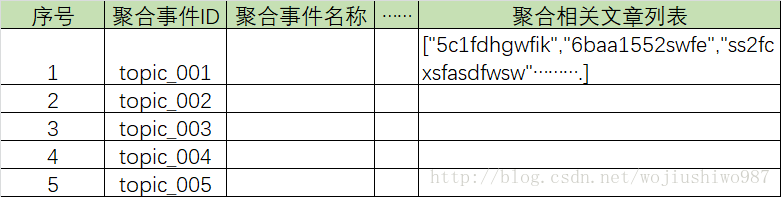
数据处理层的聚合结果存入ES中的指定索引,同时将每个聚合主题相关的数据存入每个document下面的某个field下。如下示意图所示:
方案二:
新建两个索引:aggs_index以及aggs_detail_index。
其中:
1)aggs_ind
继续阅读与本文标签相同的文章
上一篇 :
轻松可视化实现设备监控大屏效果
-
你的你的Elasticsearch在“裸奔”吗?在“裸奔”吗?
2026-05-24栏目: 教程
-
可解释的机器学习
2026-05-24栏目: 教程
-
全面布局物联网,少海汇打造两大AIoT独角兽
2026-05-24栏目: 教程
-
干货 | Elasticsearch索引管理利器——Curator深入详解
2026-05-24栏目: 教程
-
阿里云代金券阿云优惠券领取方法和使用规则介绍
2026-05-24栏目: 教程