
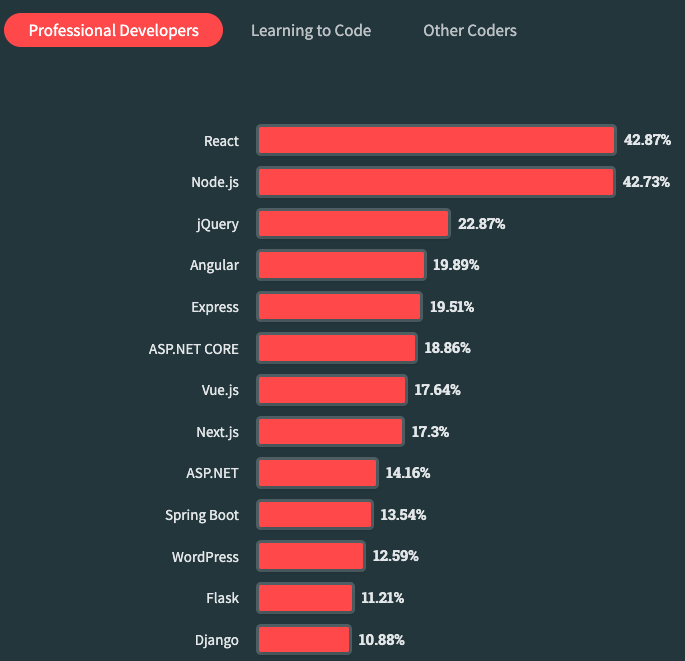
在前端三大主流框架 Angular、React 和 Vue 中,React 是一个非常流行的 库,主要用于构建用户界面,深受开发者喜爱。
根据 Stack Overflow 调查,React 拥有庞大的社区和丰富的生态系统,许多公司,无论大小,都在使用 React 开发前端应用程序。例如国外的 Netflix、Airbnb、Discord,以及 React 的诞生地 (包括 Facebook、Instagram 和 WhatsApp),国内的腾讯、阿里、字节跳动等也在使用。
今年早些时候, 的 React 开发团队宣布即将更新久未改动的版本号,让 2022 年 3 月发布的 React 18 迎来了后续版本 React 19。当下,React 19 RC 版(https://react.dev/blog/2024/04/25/react-19,是最终版之前的最后一个版本)已发布,引发了不少开发者的关注。
然而,随着开发者对新增功能以及改进细节的深挖,有一个小变化直到上周才被注意到,而这一改变可能会显著降低许多依赖 React 的网站性能。
有开发者 Henrique Yuji 表示,考虑到 React 用于创建数十亿人使用的用户界面,可以合理地假设互联网流量的一大部分是由 React 处理的。对此,他还分享了一篇《React 19 如何(几乎)让互联网变得更慢》的长文,揭露了最新的 React 19 存在的问题。
1、来自开发者的发现
当然,一切要从另一位软件工程师 Dominik 的一条推文谈起。
6 月 11 日,Dominik 发文称:
“是不是我出现幻觉了,还是说 React 18 和 React 19 在处理 Suspense 并行请求方面确实存在区别?
在 React 18 中,每个组件都是独立处理的,所以把两个需要请求数据的组件放入同一个 Suspense Boundary 中,它们的请求是同时发出的:
<Suspense fallback={<p>...</p>}><RepoData name="tanstack/query" /><RepoData name="tanstack/table" /></Suspense>
这样会同时发出两个请求,等到两个请求都完成后再显示整个子树。
而在 React 19 中,据我观察,请求变成了串行执行。我记得@rickhanlonii( React 团队工程师)提到过类似的事情,但现在找不到相关证据了。”
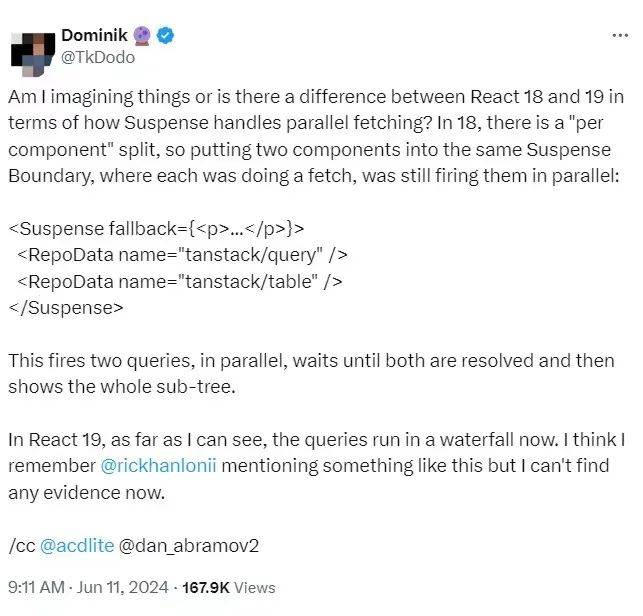
Dominik 对此进一步给出了证据,透露:“这是一个 React 18 的沙盒示例:https://stackblitz.com/edit/tanstack-query-4j1mbu?file=src%2Findex.jsx
这是一个 React 19 预发布版本的沙盒示例:https://stackblitz.com/edit/tanstack-query-5e5dav?file=src%2Findex.jsx
请看看日志输出。在 React 18 中,我们可以看到两个请求同时开始,但在 React 19 中(https://stackblitz.com/edit/tanstack-query-5e5dav?file=src%2Findex.jsx),这些请求是一个接一个地进行的。”
随之,不少使用了 React 的开发者参与了讨论。
高级 Web 工程师 Adam Rackis 转发 Dominik 的推文并评论道,“这个改动让人抓狂,无法理解。从评论来看,这似乎只影响客户端组件,但并行请求在服务器组件(RSC)中仍然有效。这毁了 react-query,这是管理 React 数据的一个好方法。我希望更冷静的人能阻止这个改动,但我不抱太大希望。”
另一位开发者 Tanner Linsley 同样表示,“是的,这感觉像是一个糟糕的举动,特别是因为它会应用到现有的应用程序和用例并自动使它们变得更糟。”
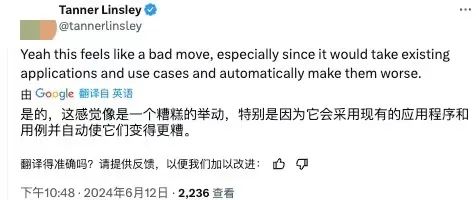
归根结底,导致这种改变的根源就是 React 官方团队在即将发布的 React 19 版本中禁用了同一 Suspense 边界内兄弟组件(siblings)的并行渲染功能。这意味着在这些兄弟组件内部进行的数据请求会变成一个接一个地进行,导致数据获取变慢,最终也会导致所有依赖 React 的网页变慢。
2、实测
为了验证这一改变将对网站带来什么样实质性的影响,有用户 matiasngf 直接在 React GitHub 仓库的 issue 上提交了自己的测试结果(https://github.com/facebook/react/pull/26380#issuecomment-2166178673)。
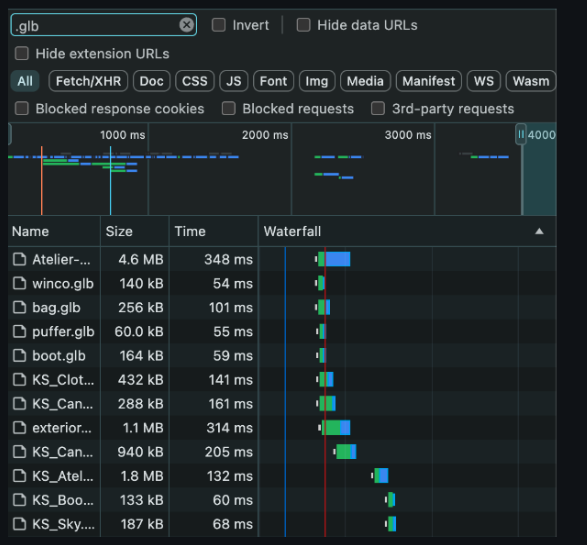
他表示,在 https://kidsuper.world/ 的一个分支上将 React 和 Next 更新为 Canary(React 19 版本),该网站使用了许多模型和纹理。
首先,matiasngf记录了当前的方法,发现加载 .glb 模型大约需要 2.5 秒:
然后,他安装了 Canary 版本的 React,发现相同的.glb 模型,加载时间约为 3.5 秒:
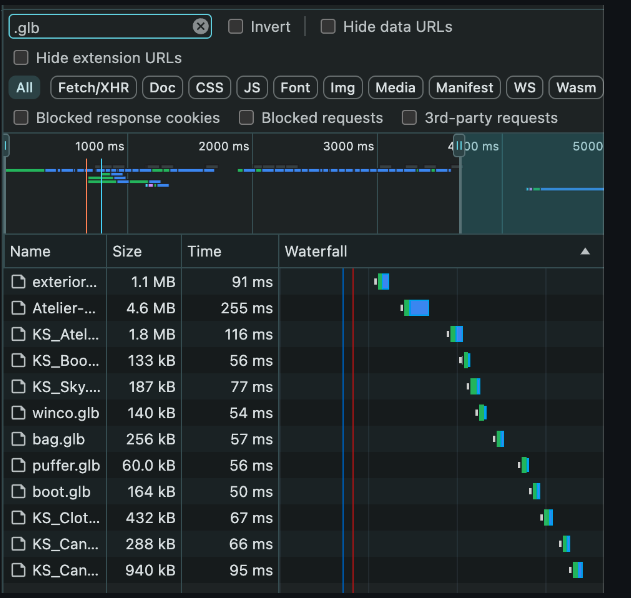
所有这一切中最糟糕的是,React 官方的这一改变对于性能方面是一个非常重大的变化,将会影响很多依赖这种模式的人,但是他们在发布这项变化时,只用了一行简短的话来介绍。要是稍微不注意,这项不起眼的变化可能也不会引起过多的讨论。

3、Suspense 究竟是什么?
要理解这到底是怎么回事,我们首先需要快速回顾一下 React 的 Suspense。
在 React 中,Suspense 是一个用来处理异步操作的组件,这个组件的作用是在其子组件完成加载之前,显示一个备用内容(例如加载动画)。这种情况通常发生在以下几种情况下:
懒加载(Lazy Loading):当子组件(模块)是懒加载的时候,也就是说它们在需要的时候才会被加载进来。在子组件加载完成之前,Suspense 可以显示一个加载指示器或者其他的备用内容。
数据获取中的等待(Data Fetching with Suspense):当子组件正在使用 Suspense 启用的数据获取机制时,Suspense 也可以用来在数据加载完成之前展示备用内容。这意味着当子组件需要从服务器获取数据时,可以使用 Suspense 来管理数据的加载状态,直到数据加载完成,然后显示实际的子组件内容。
总之,Suspense 是 React 中用来优化用户体验的一种机制,它通过在必要时显示备用内容,让页面看起来更加流畅和响应。
它的使用方式如下:
<Suspense fallback={<Loading />}><ComponentThatFetchesDataOrIsLazyLoaded /></Suspense>
尽管 Suspense 成为 React API 的一部分已经有一段时间了,但在很长一段时间里,官方只承认了一种使用方式,那就是通过 React.lazy 来懒加载组件。这在应用中进行代码分割(code-splitting)非常有用,可以在需要时才加载拆分的部分。
当使用 React.lazy 加载组件时,首次尝试渲染这个懒加载组件之前(即在延迟加载之前),会触发 Suspense 边界(Suspense Boundary)。Suspense 边界是指用 Suspense 组件包裹起来的部分 UI,它会渲染一个备用内容(fallback),直到组件的代码加载完成。然后,才会渲染实际的组件内容。
长期以来,很多开发者都在期待 React 官方在客户端支持 Suspense 进行数据获取(在使用服务器组件 RSCs 时,它已经支持)。
但直到现在,官方并没有真正提供这样的支持。
尽管如此,很多库(比如 TanStack Query)通过研究 React 的内部机制实现了这个功能。因此,目前有很多生产中的应用正在使用 Suspense 来在客户端进行数据获取。
4、了解这次的变化
截至目前(React 18.3.1),无论是使用启用了 Suspense 的数据获取,还是使用延迟加载这些位于同一个 Suspense 边界内的组件,React 在放弃渲染之前会尝试渲染所有的兄弟组件,即使第一个兄弟组件发生了暂停。
实际上,这意味着在这些兄弟组件中进行的数据获取或懒加载都会同时启动。即使第一个组件开始了数据获取或懒加载并因此暂停,React 仍然会尝试继续渲染后续的兄弟组件,而不会等待第一个组件的数据加载完成再继续。
举个例子:
function App() {return (<><Suspense fallback={"Loading..."}><ComponentThatFetchesData val={1} /><ComponentThatFetchesData val={2} /><ComponentThatFetchesData val={3} /></Suspense></>);}const ComponentThatFetchesData = ({ val }) => {const result = fetchSomethingSuspense(val);return <div>{result}</div>;};
Demo:https://stackblitz.com/edit/vitejs-vite-x3nv7r?file=src%2FApp.jsx
在这个示例中(在 React 18 版本),即使 `fetchSomethingSuspense` 导致第一个需要获取数据的组件(ComponentThatFetchesData)暂停(即等待数据加载),React 仍然会尝试渲染它的兄弟组件。这会触发每个兄弟组件的数据获取操作,这些操作会并行进行。
我们可以通过查看控制台日志来验证这一点,日志记录了每个数据获取操作启动的时间点。

所有数据获取几乎同时启动。
现在让我们看看当我们在 React 19(canary)中运行完全相同的代码时会发生什么:
Demo:https://stackblitz.com/edit/vitejs-vite-55rddj?file=src%2FApp.jsx

当我们再次查看控制台时,我们注意到出现一个“瀑布流”的效果,因为每次数据获取操作只有在前一个完成后才会开始。
发生这种情况的原因是以下 PR的引入:https://github.com/facebook/react/pull/26380
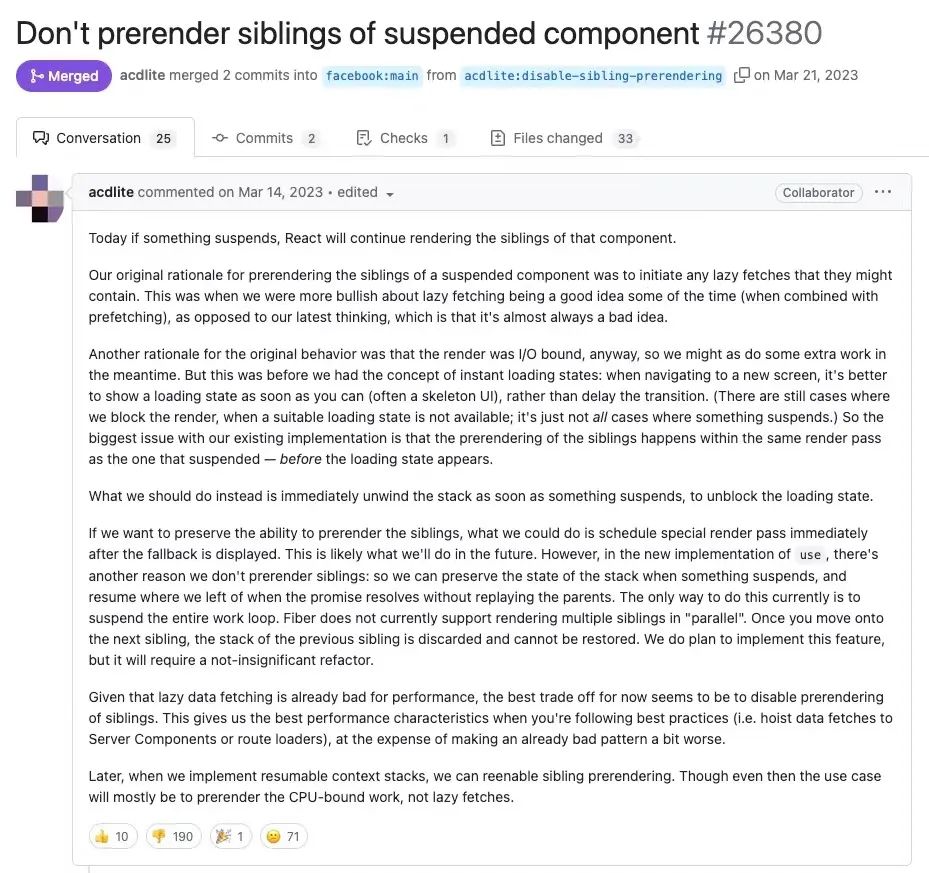
在这个 PR 引入的更改之后,React 不会尝试在同一个 Suspense 边界内渲染所有的兄弟组件,相反,它会在第一个暂停(即等待数据加载)的组件处中止渲染。
在这种情况下,你会先尝试渲染第一个组件,然后它会挂起,只有在它的数据加载完成并可以渲染后,才会继续处理下一个兄弟组件。而每个兄弟组件都可能会因为数据加载而暂停,依此类推。
这种新的行为不仅影响了使用 Suspense 进行数据获取的情况,还会影响到 React.lazy 的使用方式。React.lazy 是一种官方支持的、广泛使用的懒加载模式,它也受到了这种改变的影响。
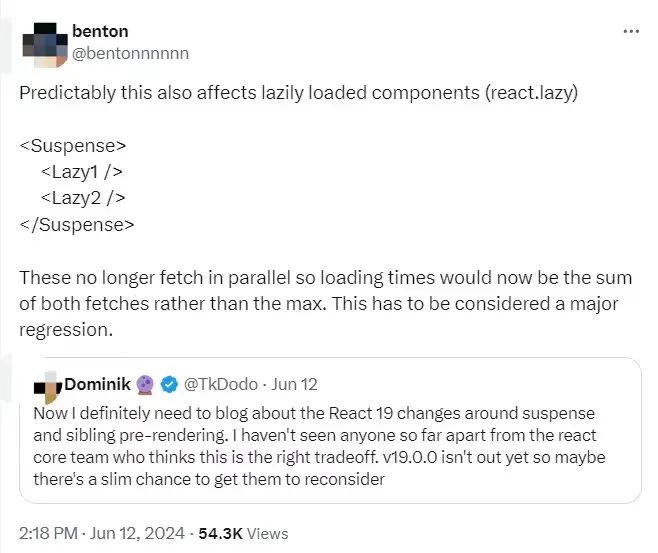
开发者 benton(https://x.com/bentonnnnnn/status/1800940807618171270)指出:“可以预见,这也会影响延迟加载的组件(react.lazy)
<Suspense><Lazy1 /><Lazy2 /></Suspense>
这些不再并行获取,因此加载时间现在是两次获取的总和,而不是最大值。这必须被视为一次重大倒退。”
5、基本原理和对开发者体验的影响
React 官方之所以做出这样的更改(在前面提到的 PR 中已写明),主要是因为在真正暂停渲染之前尝试渲染所有兄弟组件并不是无成本的,这实际上会延迟显示备用内容。此外,这一变化与 React 团队自 React 18 之前引入 Suspense 以来一直在推动的“边渲边获取”方法密切相关。
理想情况下,我们应该尽早启动数据获取,而不是在使用数据的同一组件渲染时才开始获取数据。
尽管从性能角度来看,这无疑是最佳的方法,但它也带来了显著的 DX 问题,因为它使得将组件和它们的数据要求放在一起变得不可行。
虽然 React 官方团队成员 Ricky 出面回复称,「这种做法使得组合更加容易,因为将一个组件从兄弟级别(sibling)重构为子级别(child)时,不会突然引发数据获取的“瀑布效应”(waterfall)。
换句话说,无论是兄弟组件还是子组件,在开始时都会出现数据获取的“瀑布效应”,不会因为组件之间的关系改变而有所不同。你可以通过提升数据请求(request)到更高的组件层级来解决兄弟组件和子组件的相同问题。」
然而,对于这样的回应,开发者并不买账。应用程序开发者 Teemu Ta
继续阅读与本文标签相同的文章
-
五大网络威胁应对挑战
2026-05-14栏目: 教程
-
能“生”的机器人,这不是玩笑!这只是机器拟人化的一小步
2026-05-14栏目: 教程
-
辉煌的背后,华为何时补齐短板?任正非给出新目标
2026-05-14栏目: 教程
-
全球首条“5G自动微公交”示范线路乌镇开通
2026-05-14栏目: 教程
-
未来十年,最为吃香的4个大学专业,毕业后就是香饽饽!
2026-05-14栏目: 教程