
大家好,今天要讲的内容是,基于ChatGPT的智能爬虫工具。
在本节课中,我们将使用python语言,基于openai提供的大语言模型,实现一个智能化的爬虫工具。

这个爬虫工具,实际上就是模拟GPT4官方提供的搜索与chatgpt分析相结合的功能。
具体来说,该爬虫工具会先进行Bing搜索,获取搜索结果。
然后获取搜索结果中的连接,下载对应的网页,提取网页中的文本。
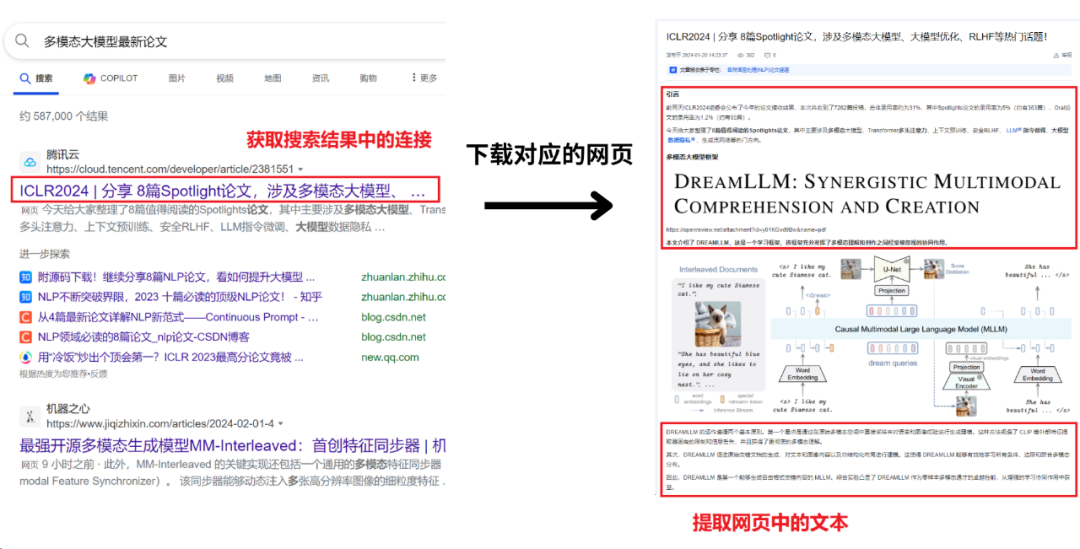
接着会使用两种不同的chat-gpt模型,
gpt-3.5和gpt4,对搜索出的内容进行分析、总结和整理,实现智能的爬虫工具。
1.获取Bing搜索结果
获取Bing的搜索结果,包括了两个步骤:
第1个步骤,根据搜索关键词,获得Bing搜索结果页面中的URL。
第2个步骤,根据搜索结果URL,获取URL对应的网页。
然后将网页中的文本提取出来,保存到文件。
这些文本后续会输入至gpt模型,进行分析与整理。
先来看第1个步骤。
例如,在Bing搜索中,搜索“多模态大模型最新论文”:
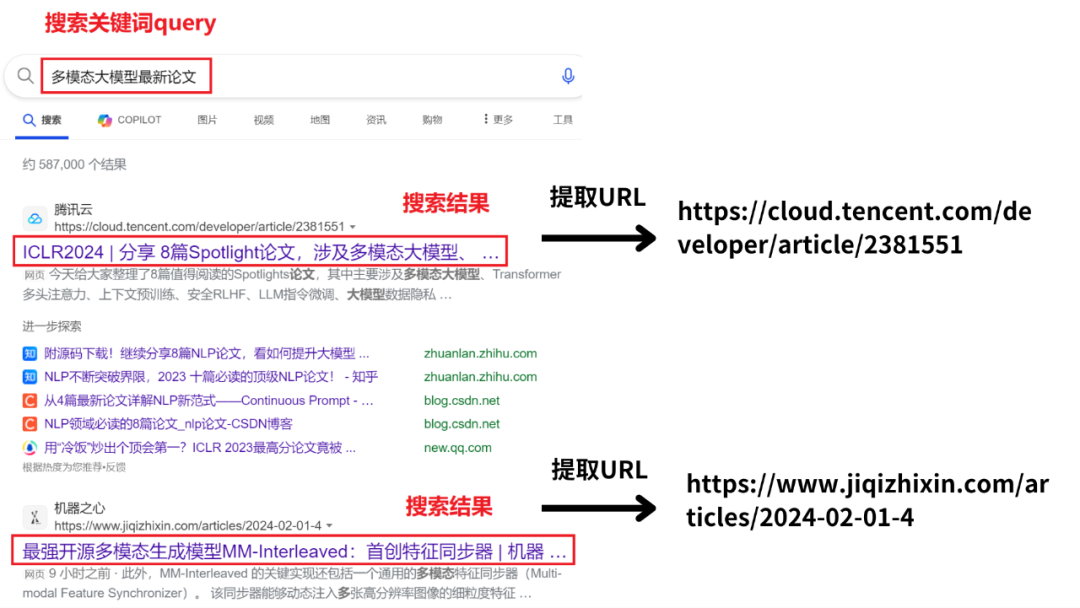
可以看到一条条的搜索结果。
其中“ICLR2024 分享8篇论文”是第1个结果。
“最强开源多模态生成模型”,是第2个结果等等。
我们需要将这些结果对应的URL链接,提取出来。
提取bing搜索结果中的URL链接,有很多种方法:

我们可以直接调用bing_search_api,也可以通过beautifulsoup,自行解析bing的搜索结果。
由于申请bing_search_api有些麻烦,也会产生一定的费用。
我们将采用直接解析HTML页面的方法,对搜索结果URL,进行提取。
首先通过bing.search.q+query的方式,构造bing搜索页的url。
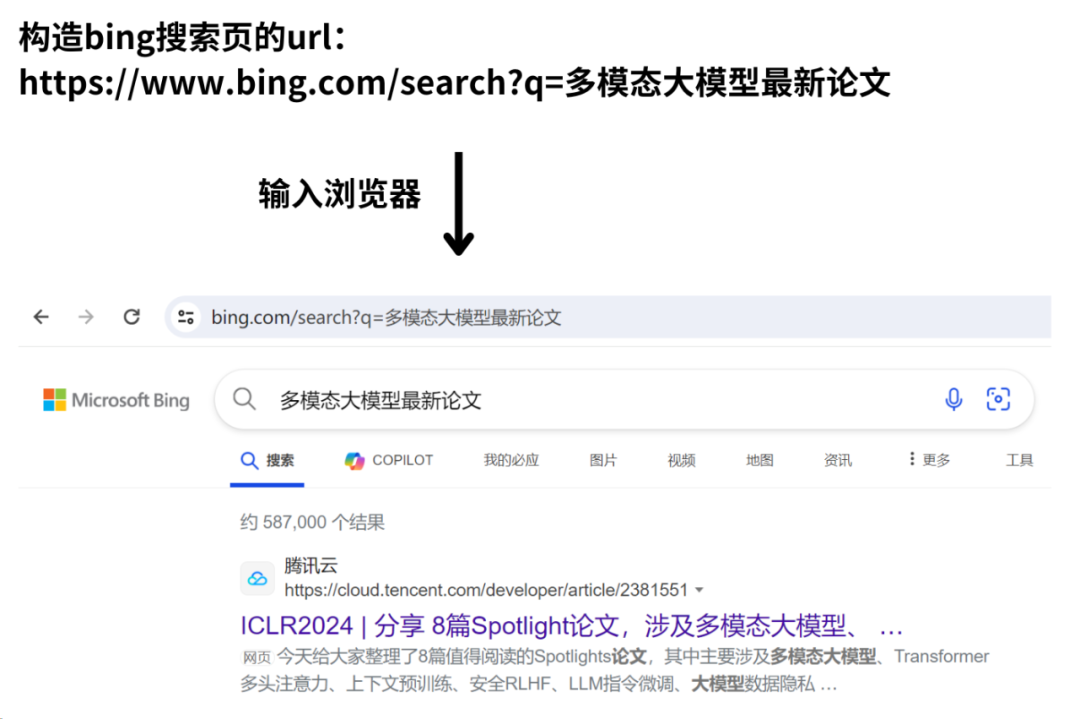
例如,构造“多模态大模型最新论文”的搜索URL,将该URL输入到浏览器,可以看到搜索结果页。
接着使用浏览器,审查网页的结构:
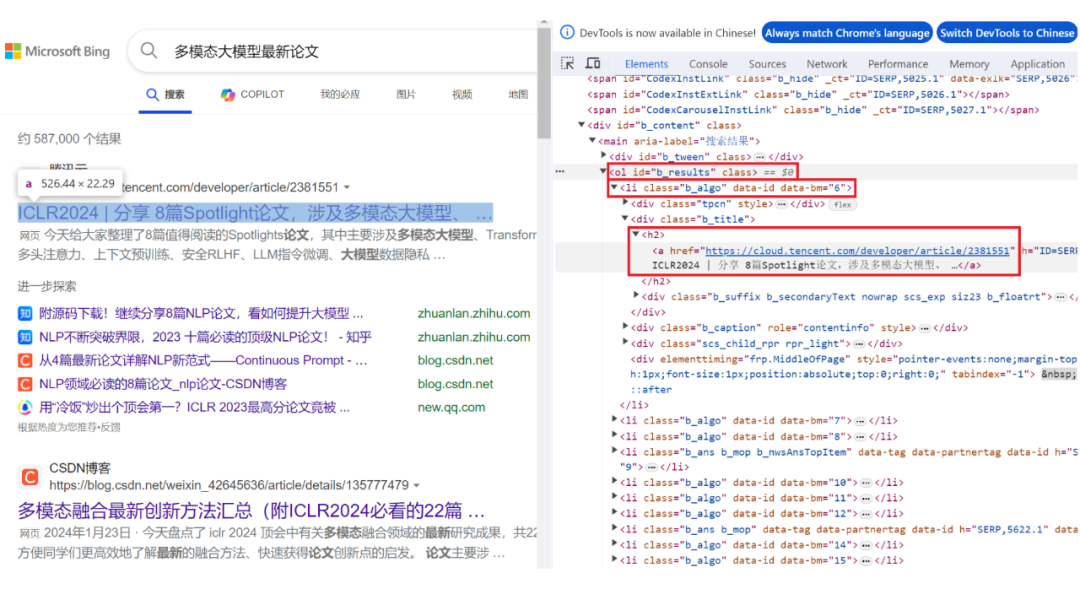
可以看到“ICLR”这条搜索结果,对应的URL链接,在名为b_results的ol标签下的li标签中。
然后,进一步审查li标签中的h2标签。
该标签下的a标签中的href属性,就是“ICLR”这条搜索结果的URL链接,我要将它提取出来。
其余搜索结果的URL获取也是同样的道理,它们都在ol标签下的li标签中。
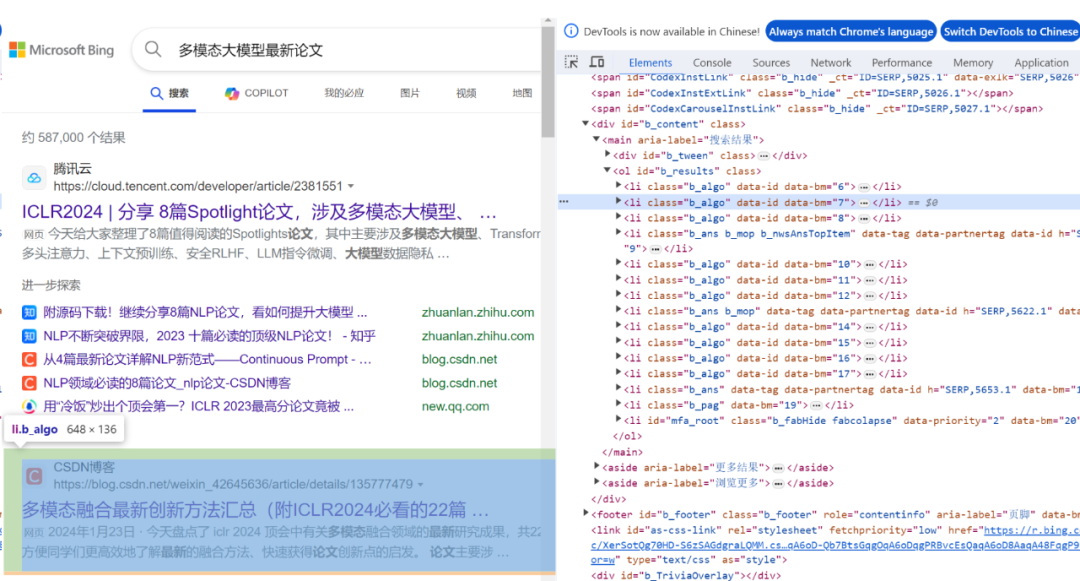
对于bing搜索的每个搜索结果页,都可以找到10条搜索结果。
另外要注意的是,如果bing搜索进行升级,可能会导致刚刚总结的提取规则失效,这种方式大规模访问Bing搜索,也可能造成ip封禁。
因此,如果需要对大规模的数据进行分析,最好还是使用bing搜索的api,并支付相关的费用获取数据。
上述过程的代码如下:
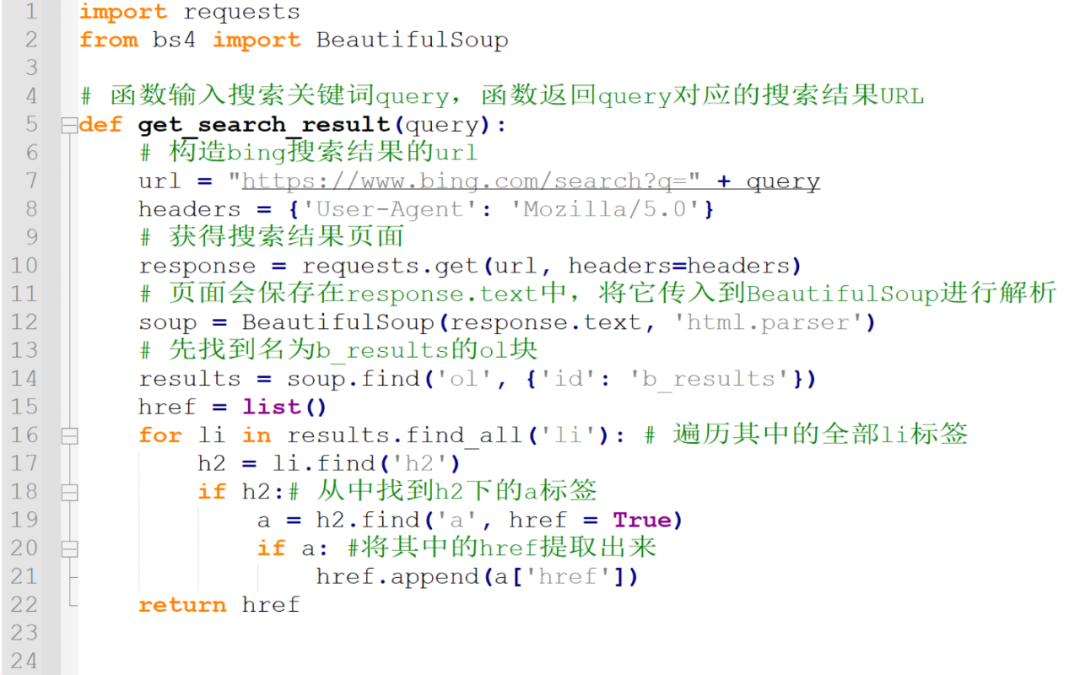
实现函数get_search_result,函数输入搜索关键词query,函数返回query对应的搜索结果URL。
在函数中,首先构造bing搜索结果的url。
然后通过requests.get,获得搜索结果页面。
页面会保存在response.text中,将它传入到BeautifulSoup进行解析。
解析方法如刚刚所说,先找到名为b_results的ol块。
然后遍历其中的全部li标签,从中找到h2下的a标签,将其中的href提取出来就可以了。
接着要根据href中的URL,获取URL对应的网页,并将这些网页中的文本保存到文件:
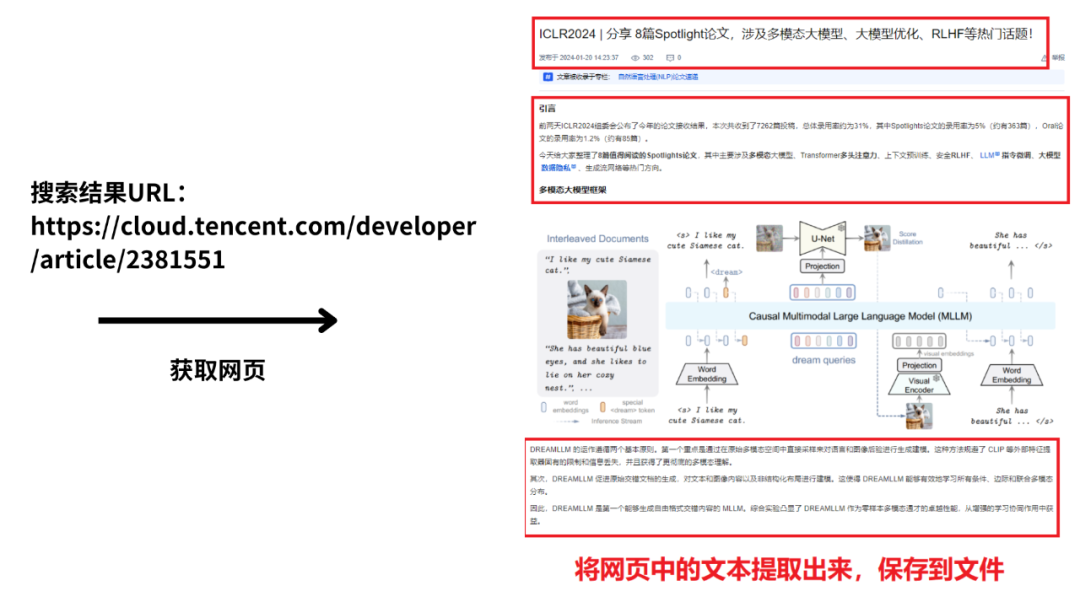
这些文本后续会输入至gpt模型,进行整理和分析。
这个过程就比较简单了,实现函数extract_content:
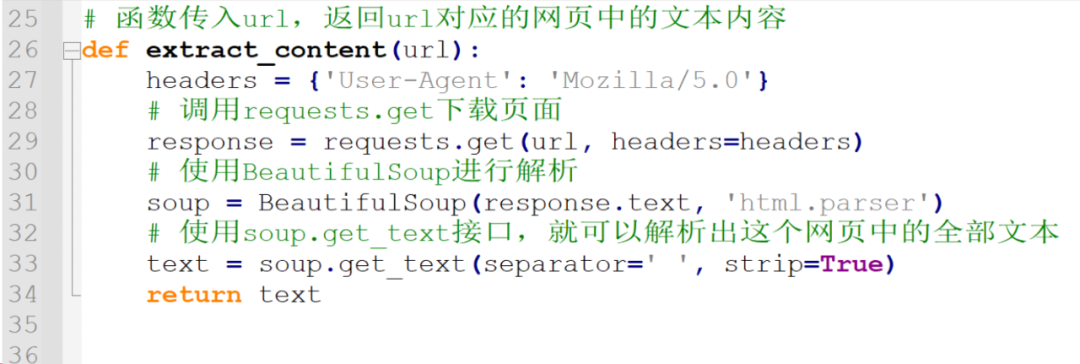
函数传入url,返回url对应的网页中的文本内容。
按照同样的方法,调用requests.get下载页面,使用BeautifulSoup进行解析。
然后使用soup.get_text接口,就可以解析出这个网页中的全部文本。
由于解析出的文本是网页中的全部文本,因此会包括很多和主题不相关的内容。
后续我们使用gpt进行整理和分析,就可以将这些杂质过滤掉。
最后实现bing搜索工具的main函数,这里为了更容易的说明,工具写的尽量简单:

首先,定义搜索关键词query。
通过get_search_result,获取全部的搜索结果URL链接。
接着要将这些链接和对应网页中的文本内容,保存到search_result.txt中。
遍历href中的全部url,使用extract_content提取url对应的网页内容。
这里会做一些必要的过滤,例如过滤掉pdf页面,和过大的网页。
最后将url、query和内容content,写到文件中。
打开文件,可以看到对于“多模态大模型最新论文”这个搜索query的9条搜索结果:

2.使用GPT分析搜索结果
为了使用GPT模型的api,我们需要注册platform.openai.com,得到API-key。
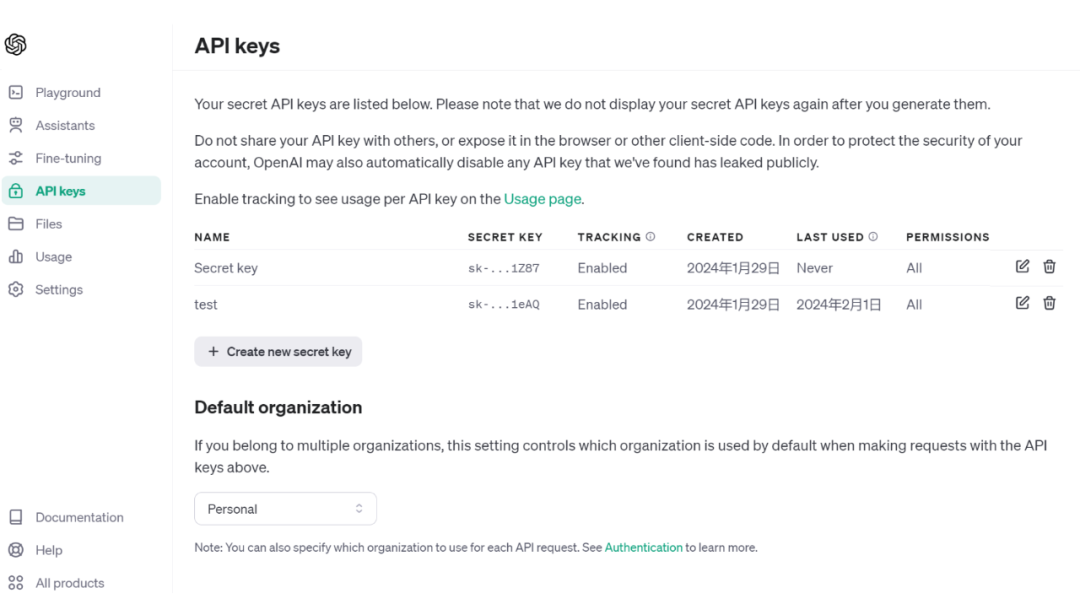
每个免费账号有5美元的使用额度,足够用来实验。
如果想使用最新的gpt4或者对大量数据进行分析,还需要绑定信用卡,充值后使用。
实际上,调用GPT模型,分析搜索结果的过程非常简单:
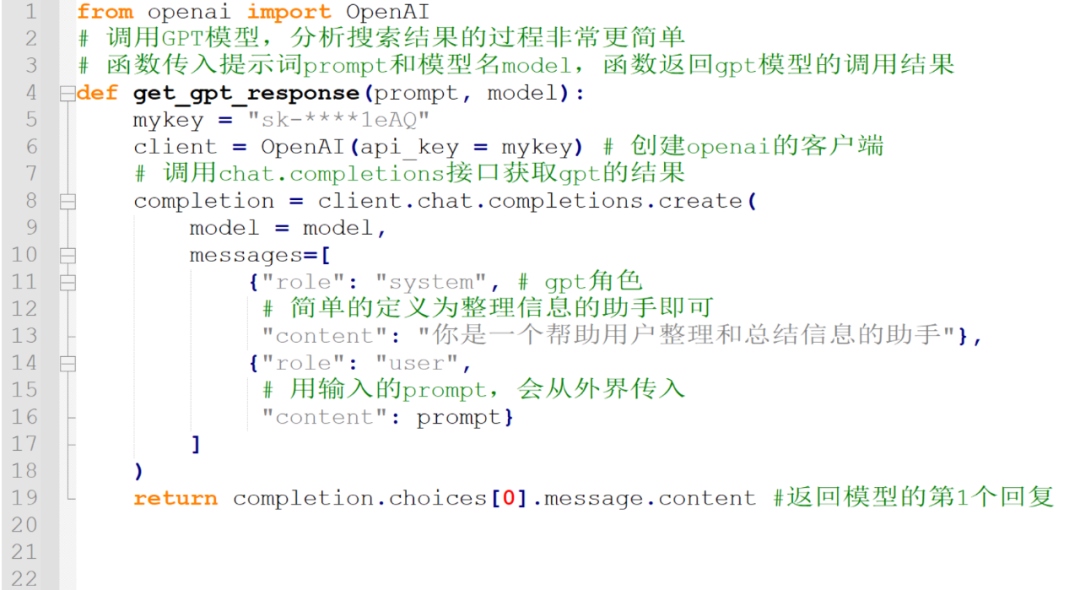
首先,我们要实现get_gpt_response函数。
函数传入提示词prompt和模型名model,函数返回gpt模型的调用结果。
在函数中,创建openai的客户端client。
调用chat.completions接口获取gpt的结果。
关于message中的gpt角色,简单的定义为整理信息的助手就可以了。
用户的content对应输入的prompt,会从外界传入。
函数返回模型的第1个回复,choices[0].message就可以了。
接着实现函数get_main_content:

函数会定义提示词prompt。
该提示词会让模型根据搜索词query,提取文本content中的主要内容。
这里定义的prompt比较简单,大家可以根据自己的需求,进一步细化提示词。
继续阅读与本文标签相同的文章
推荐3款自动爬虫神器,再也不用手撸代码了
-
1.98亿滴滴用户添加了紧急联系人 每天百万个订单行程分享给亲友
2026-05-14栏目: 教程
-
工程院院士刘韵洁:5G前景很大,但主要是行业应用
2026-05-14栏目: 教程
-
陆奇:看好5G技术,但应用好5G还需要时间
2026-05-14栏目: 教程
-
在Visual Studio中使用clang-tidy进行代码分析
2026-05-14栏目: 教程
-
甘薇贾跃亭曝出离婚消息,贾跃亭破产前转账51万美元,作为“家庭费用”
2026-05-14栏目: 教程