
Python数据分析基础介绍
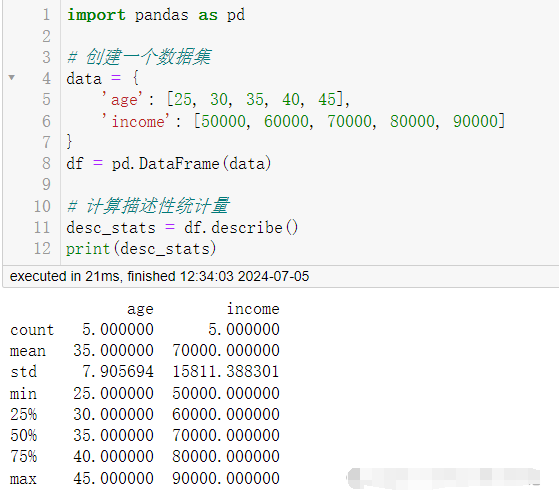
1. 描述性统计分析 (de ive statistics)描述性统计是理解数据集基本特征的第一步,它包括均值、中位数、标准差等统计量。
使用pandas库来计算数据集的描述性统计量。
importpandasaspd
# 创建一个数据集
data = {
'age': [25,30,35,40,45],
'income': [50000,60000,70000,80000,90000]
}
df = pd.data (data)
# 计算描述性统计量
desc_stats = df.describe()
print(desc_stats)
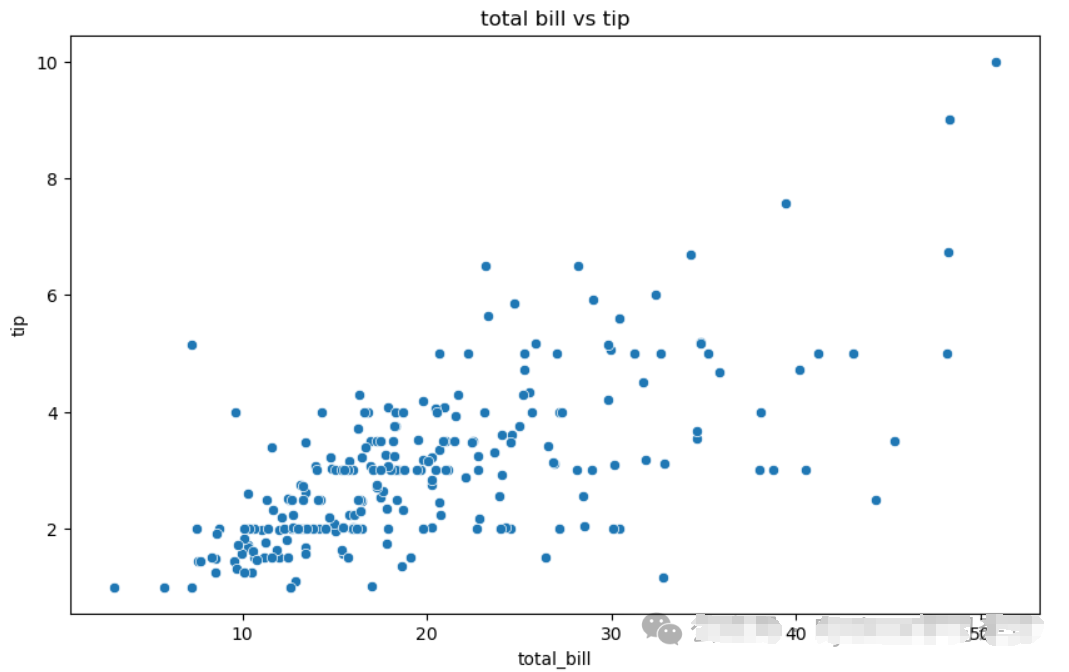
2. 数据可视化 (data visualization)
数据可视化是将数据以图形的方式展示出来,这有助于发现模式、趋势和异常。
使用matplotlib和seaborn库来创建图表。
importmatplotlib.pyplotasplt
importseabornassns
# 加载内置的数据集
tips = sns.load_dataset("tips")
# 创建散点图
plt.figure(figsize=(10,6))
sns.scatterplot(x="total_bill", y="tip", data=tips)
plt. ('total bill vs tip')
plt.show()

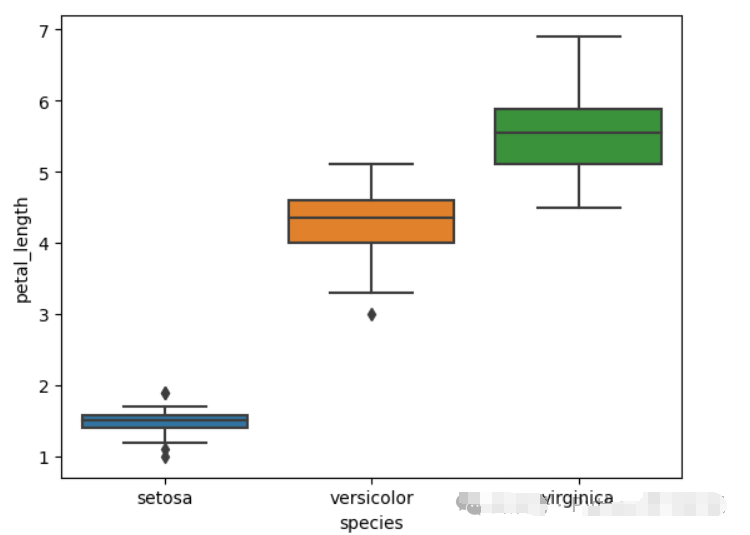
eda 是在没有明确假设的情况下使用图表和其他统计方法来了解数据的过程。
使用pandas和matplotlib进行探索性数据分析。
# 加载内置的数据集
iris = sns.load_dataset("iris")
# 使用 pandas 探查数据
print(iris.head())
print(iris.info())
print(iris.describe())
# 使用 seaborn 绘制箱线图来观察不同种类鸢尾花的花瓣长度分布
sns.boxplot(x='species', y='petal_length', data=iris)
plt.show()
输出
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
<class'pandas.core. .Data '>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length 150 non-null float64
1 sepal_width 150 non-null float64
2 petal_length 150 non-null float64
3 petal_width 150 non-null float64
4 species 150 non-null
dtypes: float64(4), (1)
memory usage: 6.0+ KB
None
sepal_length sepal_width petal_length petal_width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.057333 3.758000 1.199333
std 0.828066 0.435866 1.765298 0.762238
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
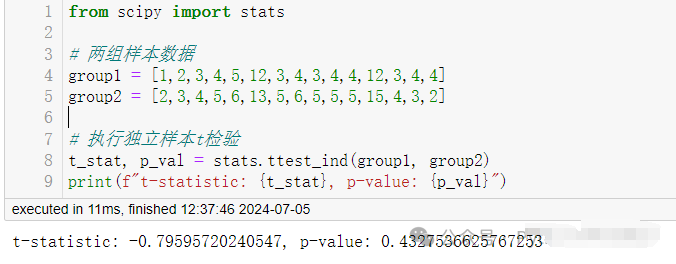
4. 假设检验 (hypothesis testing)
假设检验是确定数据中的模式是由随机变异还是实际效应引起的统计过程。
使用scipy来进行t检验。
fromscipyimportstats
# 两组样本数据
group1 = [1,2,3,4,5,12,3,4,3,4,4,12,3,4,4]
group2 = [2,3,4,5,6,13,5,6,5,5,5,15,4,3,2]
# 执行独立样本t检验
t_stat, p_val = stats.ttest_ind(group1, group2)
print(f"t-statistic:{t_stat}, p-value:{p_val}")
Python深度学习-意力机制、Transformer模型、生成式模型、目标检测算法、图神经网络、强化学习与可视化方法
Python数据分析实用技巧
importpandas as pd# Create a sample Datadata = {'old_name_1': [1,2,3],'old_name_2': [4,5,6]}df = pd.Data (data)# Rename columnsdf.rename(columns={'old_name_1':'new_name_1','old_name_2':'new_name_2'}, inplace=True)
有时,你需要处理列名不具有描述性的数据集。你可以使用重命名方法轻松重命名列。
# Filter rows where a condition is metfiltered_df = df[df['column_name'] >3]
根据条件筛选行是一种常见操作,它允许你只选择符合特定条件的行。
# Drop rows with missing valuesdf.dropna()# Fill missing values with a specific valuedf.fillna(0)
处理缺失数据是数据分析的重要组成部分。你可以删除缺失值的行,或者用默认值来填充。
# Group by a columnandcalculate meanforeach groupgrouped = df.groupby('group_column')['value_column'].mean()
分组和汇总数据对于汇总数据集中的信息至关重要。你可以使用Pandas的groupby方法计算每个组的统计数据。
# Create a pivot tablepivot_table = df.pivot_table(values='value_column', index='row_column', columns='column_column', aggfunc='mean')
数据透视表有助于重塑数据,并以表格形式进行汇总。它们对创建汇总报告尤其有用。
# Merge two Data smerged_df = pd.merge(df1, df2, on='common_column', how='inner')
当你有多个数据集时,你可以根据共同的列使用Pandas的merge功能来合并它们。
#Apply a custom function to a columndefcustom_function(x):returnx * 2df['new_column']= df['old_column'].apply(custom_function)
你可以将自定义函数应用于列,这在需要执行复杂转换时尤其有用。
# Resample time series datadf['date_column'] = pd.to_datetime(df['date_column'])df.resample('D', on='date_column').mean()
在处理时间序列数据时,Pandas允许你将数据重新采样到不同的时间频率,如每日、每月或每年。
# Convert categorical data to numericalusingone-hot encodingdf = pd.get_dummies(df, columns=['categorical_column'])
分类数据通常需要转换成数字形式,以用于机器学习模型。其中一种常用的方法是One-hot编码。
# Export Data to CSVdf.to_csv('output.csv', index=False)
定义某种列表时,写For 循环过于麻烦,幸运的是,Python有一种内置的方法可以在一行代码中解决这个问题。下面是使用For循环创建列表和用一行代码创建列表的对比。
x = [1,2,3,4]
out = []
foriteminx:
out.append(item**2)
print(out)
[1,4,9,16]
# vs.
x = [1,2,3,4]
out = [item**2foriteminx]
print(out)
[1,4,9,16]
厌倦了定义用不了几次的函数?Lambda表达式是你的救星!Lambda表达式用于在Python中创建小型,一次性和匿名函数对象, 它能替你创建一个函数。
lambda表达式的基本语法是:
lambdaarguments:
lambda arguments:
注意!只要有一个lambda表达式,就可以完成常规函数可以执行的任何操作。
你可以从下面的例子中,感受lambda表达式的强大功能:
double =lambdax: x *2
print(double(5))
10
继续阅读与本文标签相同的文章
15个Python数据分析实用技巧
10个可以快速用Python进行数据分析的小技巧
-
乌镇“互联网之光”博览会上的5G元素
2026-05-14栏目: 教程
-
华为高管彭博:正与美国公司就授权5G平台展开初期谈判
2026-05-14栏目: 教程
-
微信曝光新功能,超好用,再也不用担心被刷屏
2026-05-14栏目: 教程
-
Verizon为美国多座大型体育场馆提供了5G网络覆盖
2026-05-14栏目: 教程
-
别人加薪你加班,偷偷告诉你 6 个Word小技巧,比加薪都管用!
2026-05-14栏目: 教程