
TensorFlow Lite是专门针对移动和嵌入式设备的特性重新实现的TensorFlow版本。相比普通的TensorFlow,它的功能更加精简,不支持模型的训练,不支持分布式运行,也没有太多跨平台逻辑,支持的op也比较有限。但正因其精简性,因此比较适合用来探究一个机器学习框架的实现原理。不过准确讲,从TensorFlow Lite只能看到预测(inference)部分,无法看到训练(training)部分。
TensorFlow Lite的架构如下(图片来自官网)
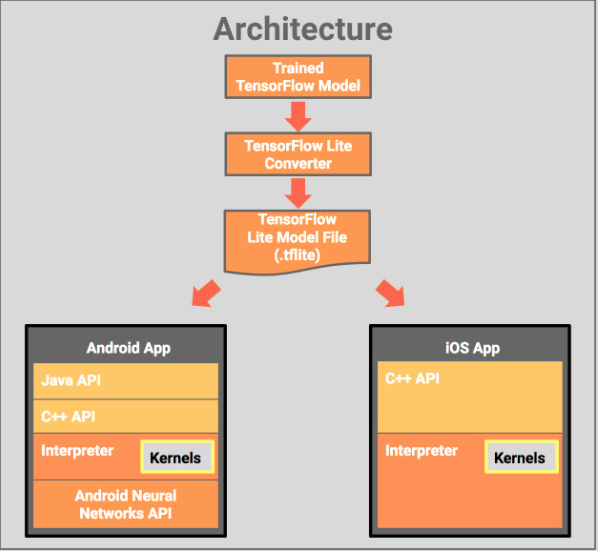
从架构图中,可以看到TensorFlow Lite主要功能可以分成几块:
- TensorFlow模型文件的格式转换。将普通的TensorFlow的pb文件转换成TensorFlow Lite需要的FlatBuffers文件。
- 模型文件的加载和解析。将文本的FlatBuffers文件解析成对应的op,用以执行。
- op的执行。具体op的实现本文暂不涉及。
TensorFlow Lite的源码结构
TensorFlow Lite源码位于tensorflow/contrib/lite,目录结构如下:
- lite - [d] c 一些基础数据结构定义,例如TfLiteContext, TfLiteStatus - [d] core 基础API定义 - [d] delegates 对eager和nnapi的代理封装 - [d] examples 使用例子,包括android和iOS的demo - [d] experimental - [d] g3doc - [d] java Java API - [d] kernels 内部实现的op,包括op的注册逻辑 - [d] lib_package - [d] models 内置的模型,例如智能回复功能 - [d] nnapi 对android平台硬件加速接口的调用 - [d] profiling 内部分析库,例如模型执行次数之类。可关掉 - [d] python Python API - [d] schema 对TensorFlow Lite的FlatBuffers文件格式的解析 - [d] testdata - [d] testing - [d] toco TensorFlow Lite Converter,将普通的TensorFlow的pb格式转换成TensorFlow Lite的FlatBuffers格式 - [d] tools - [d] tutorials - BUILD - README.md - allocation.cc - allocation.h - arena_planner.cc - arena_planner.h - arena_planner_test.cc - build_def.bzl - builtin_op_data.h - builtin_ops.h - context.h - context_util.h - error_reporter.h - graph_info.cc - graph_info.h - graph_info_test.cc - interpreter.cc - interpreter.h TensorFlow Lite解释器,C++的入口API - interpreter_test.cc - memory_planner.h - mmap_allocation.cc - mmap_allocation_disabled.cc - model.cc - model.h TensorFlow Lite的加载和解析 - model_test.cc - mutable_op_resolver.cc - mutable_op_resolver.h - mutable_op_resolver_test.cc - nnapi_delegate.cc - nnapi_delegate.h - nnapi_delegate_disabled.cc - op_resolver.h op的查找 - optional_debug_tools.cc - optional_debug_tools.h - simple_memory_arena.cc - simple_memory_arena.h - simple_memory_arena_test.cc - special_rules.bzl - stderr_reporter.cc - stderr_reporter.h - string.h - string_util.cc - string_util.h - string_util_test.cc - util.cc - util.h - util_test.cc - version.h我们主要看op_resolver.h,model.h,interpreter.h,schema/,java/,kernels/register.h等文件。
TensorFlow Lite执行过程分析
因为比较熟悉,我们从Java的API入手分析。Java API的核心类是Interpreter.java,其具体实现是在NativeInterpreterWrappter.java,而最终是调用到Native的nativeinterpreterwraptter_jni.h,自此就进入C++实现的逻辑。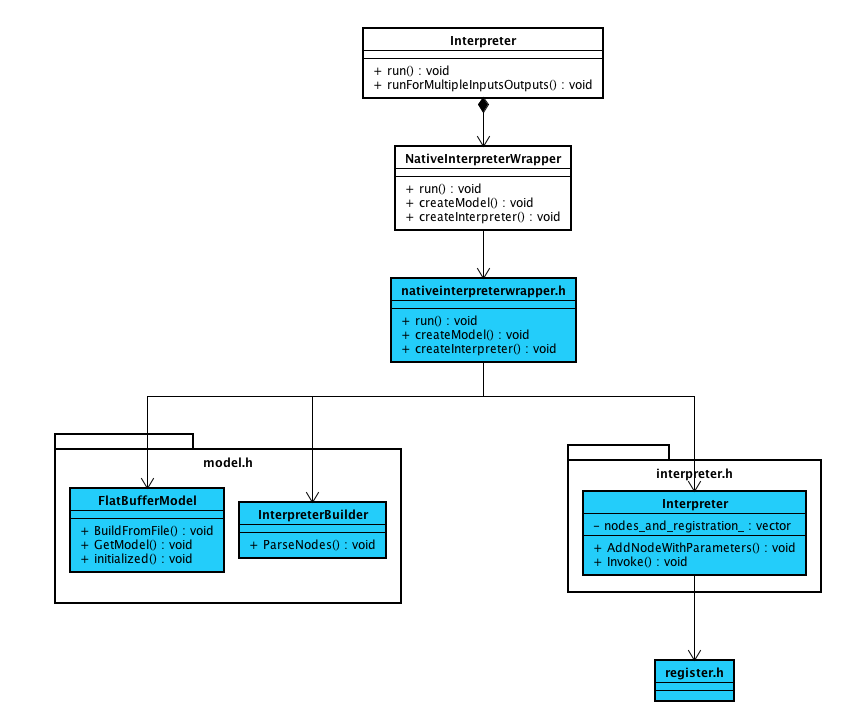
模型文件的加载和解析
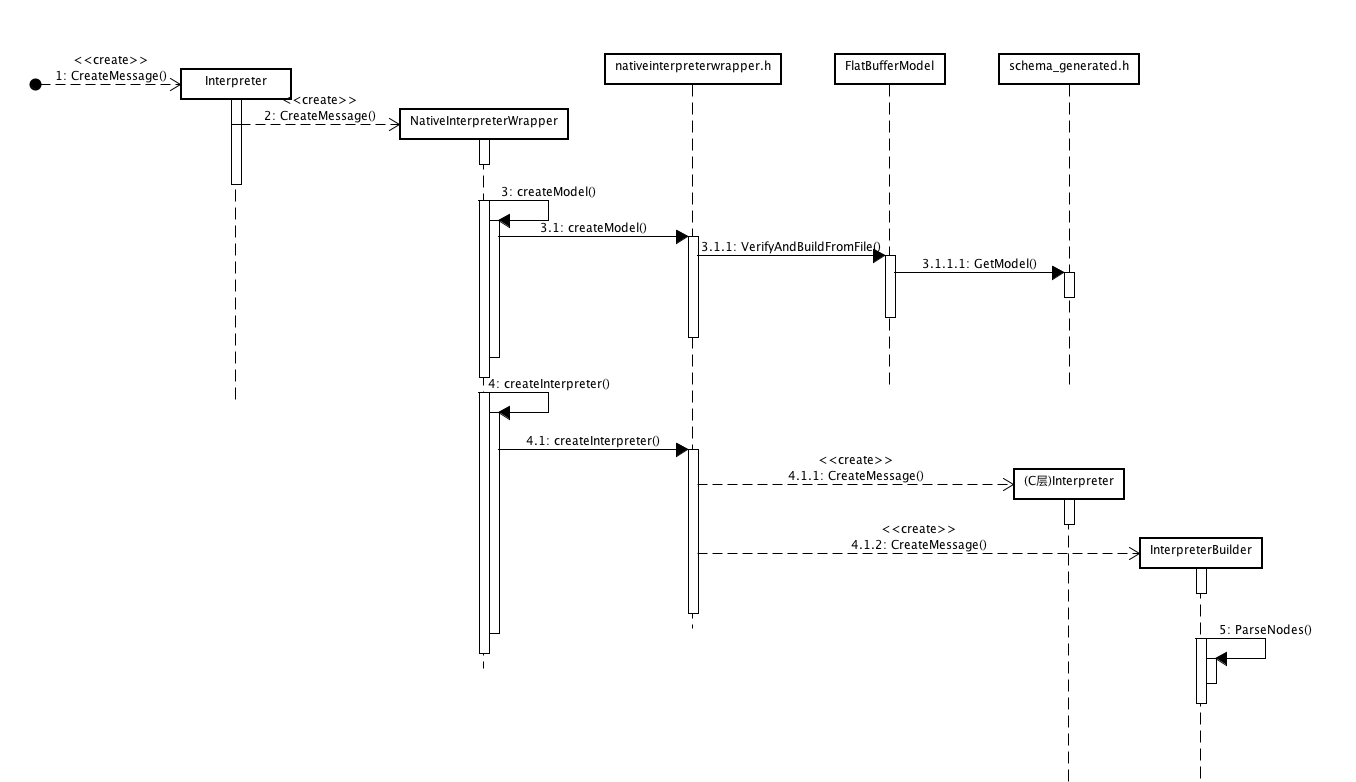
加载模型文件
//nativeinterpreter_jni.cc的createModel()函数是加载和解析文件的入口JNIEXPORT jlong JNICALLJava_org_tensorflow_lite_NativeInterpreterWrapper_createModel( JNIEnv* env, jclass clazz, jstring model_file, jlong error_handle) { BufferErrorReporter* error_reporter = convertLongToErrorReporter(env, error_handle); if (error_reporter == nullptr) return 0; const char* path = env->GetStringUTFChars(model_file, nullptr); std::unique_ptr<tflite::TfLiteVerifier> verifier; verifier.reset(new JNIFlatBufferVerifier()); //读取并解析文件关键代码 auto model = tflite::FlatBufferModel::VerifyAndBuildFromFile( path, verifier.get(), error_reporter); if (!model) { throwException(env, kIllegalArgumentException, "Contents of %s does not encode a valid " "TensorFlowLite model: %s", path, error_reporter->CachedErrorMessage()); env->ReleaseStringUTFChars(model_file, path); return 0; } env->ReleaseStringUTFChars(model_file, path); return reinterpret_cast<jlong>(model.release());}上述逻辑中,最关键之处在于
auto model = tflite::FlatBufferModel::VerifyAndBuildFromFile(path, verifier.get(), error_reporter);这行代码的作用是读取并解析文件看起具体实现。
//代码再model.cc文件中std::unique_ptr<FlatBufferModel> FlatBufferModel::VerifyAndBuildFromFile( const char* filename, TfLiteVerifier* verifier, ErrorReporter* error_reporter) { error_reporter = ValidateErrorReporter(error_reporter); std::unique_ptr<FlatBufferModel> model; //读取文件 auto allocation = GetAllocationFromFile(filename, /*mmap_file=*/true, error_reporter, /*use_nnapi=*/true); if (verifier && !verifier->Verify(static_cast<const char*>(allocation-> ()), allocation->bytes(), error_reporter)) { return model; } //用FlatBuffers库解析文件 model.reset(new FlatBufferModel(allocation.release(), error_reporter)); if (!model->initialized()) model.reset(); return model;}这段逻辑中GetAllocationFromFile()函数获取了文件内容的地址,FlatBufferModel()构造函数中则利用FlatBuffers库读取文件内容。
解析模型文件
上面的流程将模型文件读到FlatBuffers的Model数据结构中,具体数据结构定义可以见schema.fbs。接下去,需要文件中的数据映射成对应可以执行的op数据结构。这个工作主要由InterpreterBuilder完成。
//nativeinterpreter_jni.cc的createInterpreter()函数是将模型文件映射成可以执行的op的入口函数。JNIEXPORT jlong JNICALLJava_org_tensorflow_lite_NativeInterpreterWrapper_createInterpreter( JNIEnv* env, jclass clazz, jlong model_handle, jlong error_handle, jint num_threads) { tflite::FlatBufferModel* model = convertLongToModel(env, model_handle); if (model == nullptr) return 0; BufferErrorReporter* error_reporter = convertLongToErrorReporter(env, error_handle); if (error_reporter == nullptr) return 0; //先注册op,将op的实现和FlatBuffers中的index关联起来。 auto resolver = ::tflite::CreateOpResolver(); std::unique_ptr<tflite::Interpreter> interpreter; //解析FlatBuffers,将配置文件中的内容映射成可以执行的op实例。 TfLiteStatus status = tflite::InterpreterBuilder(*model, *(resolver.get()))( &interpreter, static_cast<int>(num_threads)); if (status != kTfLiteOk) { throwException(env, kIllegalArgumentException, "Internal error: Cannot create interpreter: %s", error_reporter->CachedErrorMessage()); return 0; } // allocates memory status = interpreter->AllocateTensors(); if (status != kTfLiteOk) { throwException( env, kIllegalStateException, "Internal error: Unexpected failure when preparing tensor allocations:" " %s", error_reporter->CachedErrorMessage()); return 0; } return reinterpret_cast<jlong>(interpreter.release());}这里首先调用::tflite::CreateOpResolver()完成op的注册,将op实例和FlatBuffers中的索引对应起来,具体索引见schema_generated.h里面的BuiltinOperator枚举。
//builtin_ops_jni.ccstd::unique_ptr<OpResolver> CreateOpResolver() { // NOLINT return std::unique_ptr<tflite::ops::builtin::BuiltinOpResolver>( new tflite::ops::builtin::BuiltinOpResolver());}//register.ccBuiltinOpResolver::BuiltinOpResolver() { AddBuiltin(BuiltinOperator_RELU, Register_RELU()); AddBuiltin(BuiltinOperator_RELU_N1_TO_1, Register_RELU_N1_TO_1()); AddBuiltin(BuiltinOperator_RELU6, Register_RELU6()); AddBuiltin(BuiltinOperator_TANH, Register_TANH()); AddBuiltin(BuiltinOperator_LOGISTIC, Register_LOGISTIC()); AddBuiltin(BuiltinOperator_AVERAGE_POOL_2D, Register_AVERAGE_POOL_2D()); AddBuiltin(BuiltinOperator_MAX_POOL_2D, Register_MAX_POOL_2D()); AddBuiltin(BuiltinOperator_L2_POOL_2D, Register_L2_POOL_2D()); AddBuiltin(BuiltinOperator_CONV_2D, Register_CONV_2D()); AddBuiltin(BuiltinOperator_DEPTHWISE_CONV_2D, Register_DEPTHWISE_CONV_2D() ...}InterpreterBuilder则负责根据FlatBuffers内容,构建Interpreter对象。
TfLiteStatus InterpreterBuilder::operator()( std::unique_ptr<Interpreter>* interpreter, int num_threads) { ..... // Flatbuffer model schemas define a list of opcodes independent of the graph. // We first map those to registrations. This reduces string lookups for custom // ops since we only do it once per custom op rather than once per custom op // invocation in the model graph. // Construct interpreter with correct number of tensors and operators. auto* subgraphs = model_->subgraphs(); auto* buffers = model_->buffers(); if (subgraphs->size() != 1) { error_reporter_->Report("Only 1 subgraph is currently supported.
"); return cleanup_and_error(); } const tflite::SubGraph* subgraph = (*subgraphs)[0]; auto operators = subgraph->operators(); auto tensors = subgraph->tensors(); if (!operators || !tensors || !buffers) { error_reporter_->Report( "Did not get operators, tensors, or buffers in input flat buffer.
"); return cleanup_and_error(); } interpreter->reset(new Interpreter(error_reporter_)); if ((**interpreter).AddTensors(tensors->Length()) != kTfLiteOk) { return cleanup_and_error(); } // Set num threads (**interpreter).SetNumThreads(num_threads); // Parse inputs/outputs (**interpreter).SetInputs(FlatBufferIntArrayToVector(subgraph->inputs())); (**interpreter).SetOutputs(FlatBufferIntArrayToVector(subgraph->outputs())); // Finally setup nodes and tensors if (ParseNodes(operators, interpreter->get()) != kTfLiteOk) return cleanup_and_error(); if (ParseTensors(buffers, tensors, interpreter->get()) != kTfLiteOk) return cleanup_and_error(); std::vector<int> variables; for (int i = 0; i < (*interpreter)->tensors_size(); ++i) { auto* tensor = (*interpreter)->tensor(i); if (tensor->is_variable) { variables.push_back(i); } } (**interpreter).SetVariables(std::move(variables)); return kTfLiteOk;}模型的执行
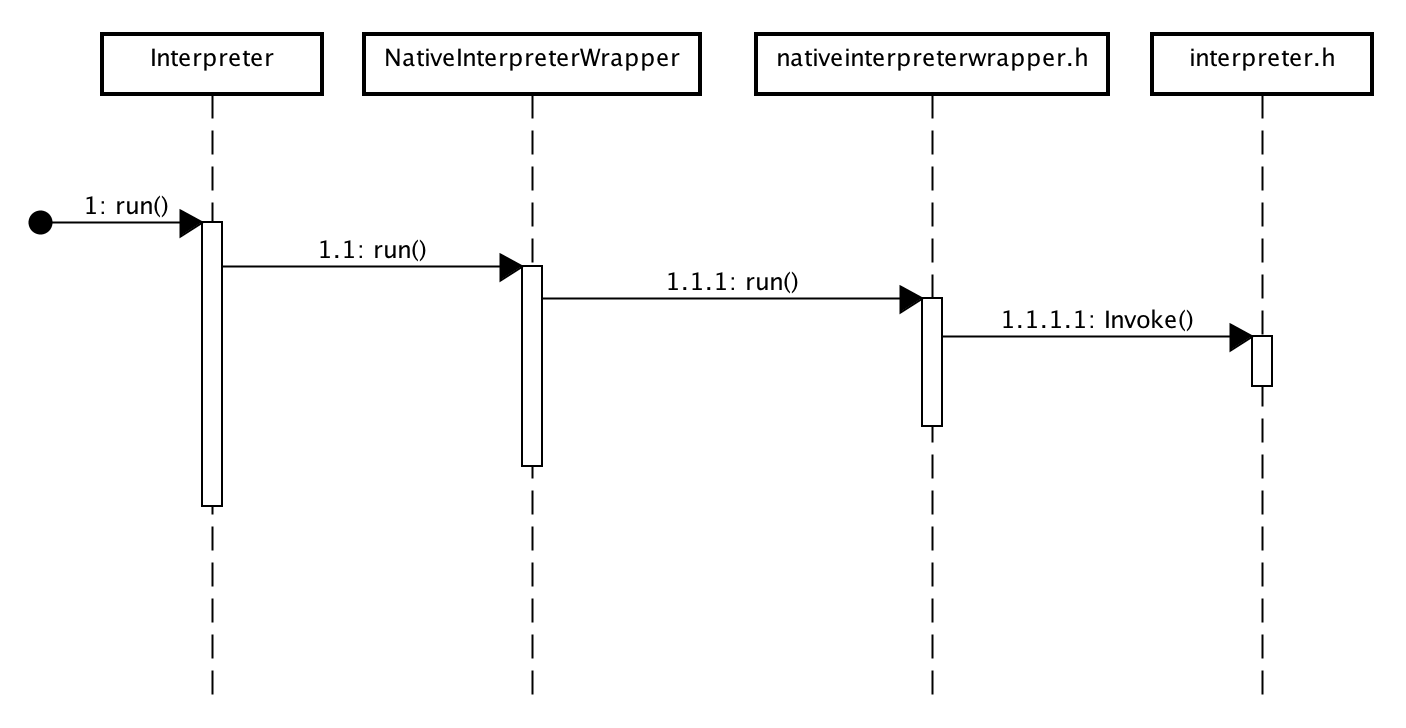
经过InterpreterBuilder的工作,模型文件的内容已经解析成可执行的op,存储在interpreter.cc的nodes_and_registration_列表中。剩下的工作就是循环遍历调用每个op的invoke接口。
//interpreter.ccTfLiteStatus Interpreter::Invoke() {..... // Invocations are always done in node order. // Note that calling Invoke repeatedly will cause the original memory plan to // be reused, unless either ResizeInputTensor() or AllocateTensors() has been // called. // TODO(b/71913981): we should force recalculation in the presence of dynamic // tensors, because they may have new value which in turn may affect shapes // and allocations. for (int execution_plan_index = 0; execution_plan_index < execution_plan_.size(); execution_plan_index++) { if (execution_plan_index == next_execution_plan_index_to_prepare_) { TF_LITE_ENSURE_STATUS(PrepareOpsAndTensors()); TF_LITE_ENSURE(&context_, next_execution_plan_index_to_prepare_ >= execution_plan_index); } int node_index = execution_plan_[execution_plan_index]; TfLiteNode& node = nodes_and_registration_[node_index].first; const TfLiteRegistration& registration = nodes_and_registration_[node_index].second; SCOPED_OPERATOR_PROFILE(profiler_, node_index); // TODO(ycling): This is an extra loop through inputs to check if the data // need to be copied from Delegate buffer to raw memory, which is often not // needed. We may want to cache this in prepare to know if this needs to be // done for a node or not. for (int i = 0; i < node.inputs->size; ++i) { int tensor_index = node.inputs->data[i]; if (tensor_index == kOptionalTensor) { continue; } TfLiteTensor* tensor = &tensors_[tensor_index]; if (tensor->delegate && tensor->delegate != node.delegate && tensor->data_is_stale) { EnsureTensorDataIsReadable(tensor_index); } } EnsureTensorsVectorCapacity(); tensor_resized_since_op_invoke_ = false; //逐个op调用 if (OpInvoke(registration, &node) == kTfLiteError) { status = ReportOpError(&context_, node, registration, node_index, "failed to invoke"); } // Force execution prep for downstream ops if the latest op triggered the // resize of a dynamic tensor. if (tensor_resized_since_op_invoke_ && HasDynamicTensor(context_, node.outputs)) { next_execution_plan_index_to_prepare_ = execution_plan_index + 1; } } if (!allow_buffer_handle_output_) { for (int tensor_index : outputs_) { EnsureTensorDataIsReadable(tensor_index); } } return status;}参考文章
继续阅读与本文标签相同的文章
-
加速5G商业成功,华为5G设备全球发货超40万
2026-05-18栏目: 教程
-
如何看清新媒体行业过去和未来的红利?
2026-05-18栏目: 教程
-
阿里云独门绝技之无代理混合云数据库实时增量备份
2026-05-18栏目: 教程
-
外国网友惊叹中国5G公交:中国早已比我们想象的更好
2026-05-18栏目: 教程
-
Aliyun Serverless VSCode Extension v1.8.0 发布
2026-05-18栏目: 教程