
向量化计算
软件优化的原理与实践系列之一
前言
用过MATLAB仿真语言的同学,都有这样的经验。要尽量多用向量化运算,而不要自己手写循环语句,否则代码的执行效率会相当低下。如果你熟悉python,涉及到数值计算的时候,也要尽量的调用成熟的数值计算的库,比如numpy,而不是自己用循环去实现。一个众所周知的理由是,别人成熟的库已经经过了高度的优化,我们没有必要重复造轮子。
事实上,还有另外一个根本性的原因是,向量化计算,就即使没有经过任何优化的代码,也会比非向量化运算要快。本篇博文将试图解释其根本性原因。
背景
现代计算机大都采用了分层的存储器结构:寄存器,cache,主存,磁盘。CPU的计算单元直接和寄存器交换信息,计算时需要把数据逐级传递到寄存器,计算得到的结果也要将结果逐级放回存储器。基于这种存储体系结构,程序员在编制软件的时候,要尽量的减少和cache,主存,磁盘这些存储器交换数据。我们把整个软件的执行实行划分为两部分,CPU真正执行运算的时间和寄存器与存储器交换数据的时间,即:

常见线性代数运算操作的q值
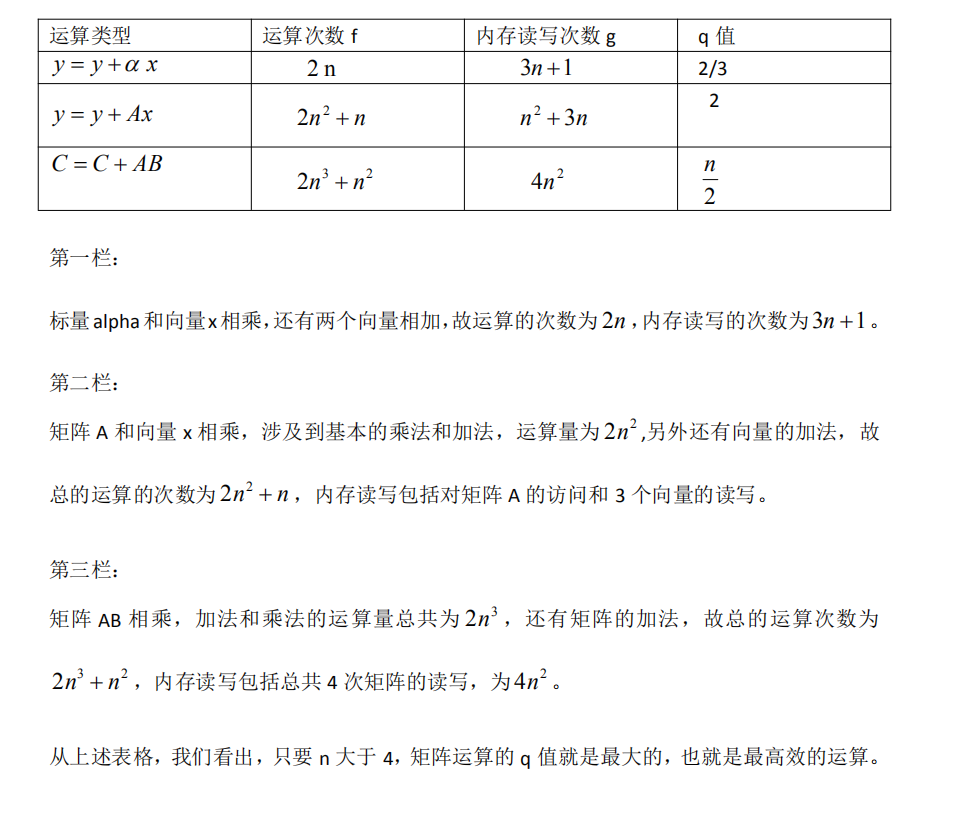
小结
把计算流程用向量,矩阵的数学语言重新描述,在此基础上实施的计算,总是比标量计算的效率高,即使代码没有经过任何优化。
继续阅读与本文标签相同的文章
上一篇 :
Vue中的$set的使用实例代码
下一篇 :
6种查看Linux进程占用端口号的方法详解
-
第三讲,Ceph内部构件
2026-05-18栏目: 教程
-
日本发明AI女友,中国却发明AI主持人,这就是差距!
2026-05-18栏目: 教程
-
《华西通信》行业深度:Wi-Fi6同步5G启航,共享万物互
2026-05-18栏目: 教程
-
不用纠结NSA与SA网络!对于5G手机来说,体验基本一致
2026-05-18栏目: 教程
-
你对自己的网站拥有所有权吗?
2026-05-18栏目: 教程