
介绍
Jarvis是一款专门为手机端而设计研发的深度学习引擎,它比我们目前已知的所有开源产品都要快。在使用高通芯片的安卓手机上,其他产品在性能上甚至还没有接近于我们的。小小骄傲一下。在最开始的时候,Jarvis was heavily influenced by Caffe2 and borrowed quite a bit of code from it. 但是随着时间的推移以及业务的演进,Jarvis离Caffe2也越来越远,所以,我们最终决定发布独立的产品。
Jarvis由淘宝的 拍立淘 业务而生,已持续稳定服役一年。
性能
距离上次介绍Jarvis又过去了三个月的时间,现在的Jarvis相比之前又有了很多进步,在端上承载的拍立淘业务也逐渐增多。不知不觉间,Jarvis已经成为了最快的那一款。之前我们的CPU实现比ncnn要慢,现在已经超过了。而GPU的实现在之前的高起点上又有了更大的提高,之前GPU的性能大约是ncnn的两倍,现在已经到了4倍。
在下表中,我列出了几款常见的端上深度学习引擎的SqueezeNet耗时(毫秒)对比。
| Jarvis(GPU) | Jarivs(CPU) | Caffe2(Facebook) | ncnn(Tencent) | mdl(Baidu) | |
|---|---|---|---|---|---|
| Samsung S8 | 30 | 80 | 110 | 120 | 150 |
| Huawei P10 | - | 110 | 160 | 140 | 180 |
| iPad pro | 23 | 56 | 140 | 65 | - |
| iPhone 6sp | 35 | 58 | 160 | 80 | - |
在我们测试几款高中低端手机上,Jarvis的CPU实现的性能表现都是最好的。GPU就不用说了。
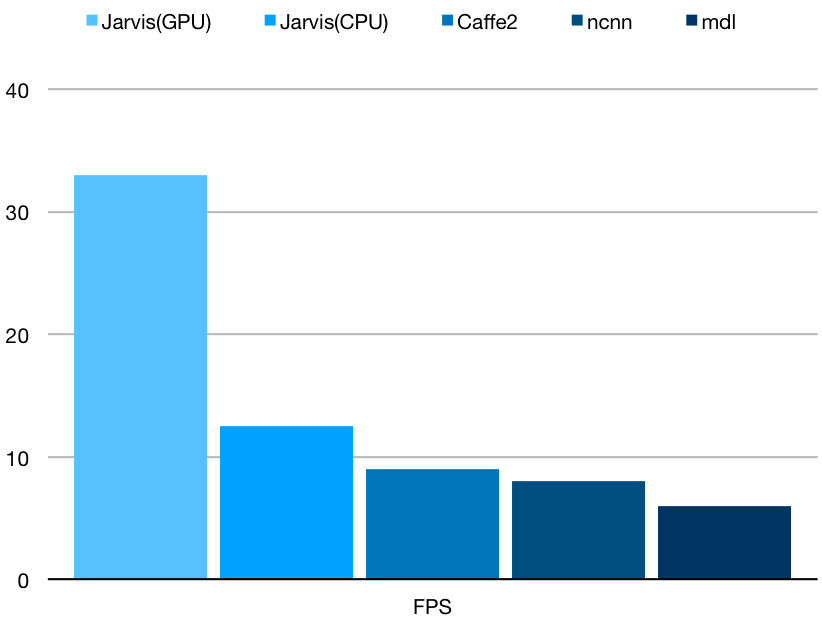
下面这幅图是在Samsung S8上,换算成FPS(每秒处理图片数)的对比结果。
使用
编译打包
已经随源码一起提供了预编译包,参考目录里面的android和iOS demo工程。也可以使用里面的工程自己编译打包。
模型生成
为了平衡性能、包大小以及便利程度,Jarvis采用flatbuffers作为模型文件格式。
示例里面带有SqueezeNet和MobileNet两个已经生成好的model,tools目录下面有转化caffe和caffe2模型的工具。
如果需要,你也可以可以使用C++,包含public目录下的schema_generated.h头文件通过代码动态生成模型。
当然,你也可以使用 ive-C++来包含这个文件。事实上,如果你想,你甚至可以根据schema.fbs文件生成Java类来做同样的事儿。
API
Jarvis提供了android(Java),iOS( ive-C)和C++三套API,都很简单。Jarvis在设计时已尽量屏蔽掉烦人的东西,而只提供给你极速的体验。
查看一下Java类, ive-C interface或者public目录里面的header file,即可知道Jarvis为数不多的API了。
android
// 构建网络,modelBuffer是包含jarvis模型文件的ByteBufferSession session = new Session(modelBuffer);// Where amazing happens, jarvis会根据网络配置的输入大小对testBitmap做缩放Tensor[] results = session.inference(testBitmap);// 得到结果float[] values = results[0].readFloats();// 更通用的调用方式Tensor input = session.input(0);float[] data = new float[input.size()];// put some values...input.write(data);// runsession.inference();// got resultTensor output = session.output(0);float[] results = output.readFloats();iOS
// model是包含模型的NSData *JVSSession *session = [[JVSSession alloc] initWithModel:model];NSArray<JVSTensor *> *results = [session inferenceWithImage:testImage];C++
std::unique_ptr<jarvis::Session> session(new jarvis::Session(model_buffer));auto results = session->inference_rgba(p_rgba, width, height, stride);目前我们在运行的业务
- 用户行为特征端上实时计算
- 拍立淘活动页面扫商品/logo抠图
- 拍立淘多主体拍照识别和智能识别
这一阶段我们所完成的工作
- 性能优化,iOS和Android都有较大提升
- 统一了iOS和Android的基础代码
- 完善了caffe model的转化工具
- 多数据类型支持,现在已经可以运行float32和float16网络
- 更多的线上业务
接下来的安排
- int8的支持,下一个必需攻克的难关。有了它,安卓低端机无忧
- Mali GPU优化,能达到和高通GPU同样的水平吗
继续阅读与本文标签相同的文章
-
每分钟进出车辆2.5台 智能立体车库解锁停车难
2026-05-19栏目: 教程
-
一文了解机器学习必学10大算法
2026-05-19栏目: 教程
-
开一家线上外卖门店选址要注意哪些因素?
2026-05-19栏目: 教程
-
信院人的APP,你get到了吗?
2026-05-19栏目: 教程
-
对话FILA姚伟雄:安踏赋予独立性,未来坚持做直营
2026-05-19栏目: 教程