
本文来自AI新媒体量子位(QbitAI)

去年11月,谷歌展示了几项有趣的机器学习实验,其中包括Quick, Draw!——在这款游戏中,你可以画一个东西,让图片识别系统猜测你画的究竟实是什么。

该公司现在又发布了玩家提交的海量图片,将其作为一个公开数据库,供人工智能开发者使用。目前,这个数据库包含5000万张图,谷歌还打算继续扩充它。
如果你觉得浏览5000万张潦草的绘画毫无乐趣,那也不要担心,因为关键不在这里。
关键在于元数据。这些元数据来自许多不同国家,内容也有很大差异,而且充满乐趣。
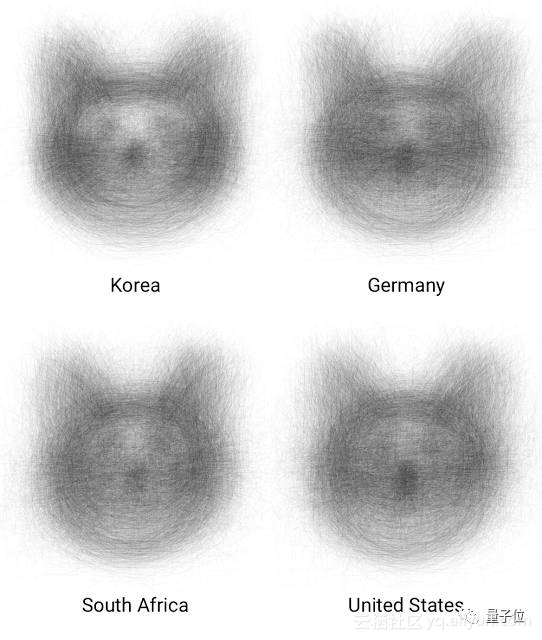
例如,你可以从中了解德国人和韩国人对猫或椅子有什么不同看法。

当然,其中的一些模式非常值得思考。很显然,韩国人和俄罗斯人更喜欢把椅子画在角落或侧面。为什么?你或许可以借助自己的机器学习系统找出背后的原因。
其中还有很多有趣的信息。谷歌在博文中指出,整个数据库里的运动鞋比例很大,以至于系统很难识别出高跟鞋和凉鞋。人们画猫的方法可能也存在一些特定模式。你画的猫是否跟别人有所不同?或许也可以开发一套机器学习算法找出答案。
谷歌建议你使用新的Facets工具对海量数据进行视觉化。当你拥有这么大的数据时,如何对其进行分类,以便人们找到值得思考的粗糙模式和想法?如何找到系统性偏见或改进的机会,或者其他类似的东西?
这5000万张图片只是个开始——谷歌今后还将发布另外大约7.5亿张图片,还有可能包括其他项目的有趣数据。
更多信息见Google Research Blog:https://research.googleblog.com/2017/08/exploring-and-visualizing-open-global.html
数据集:https://quickdraw.withgoogle.com/data
— 完 —
本文作者:李杉
原文发布时间:2017-08-26
继续阅读与本文标签相同的文章
-
有一种糖叫语法糖【4】IOT三连之设备之基本操作
2026-05-18栏目: 教程
-
每月更新两版 完善145个技术点 夸克无障碍版打造信息坦途
2026-05-18栏目: 教程
-
高危预警|RDP漏洞或引发大规模蠕虫爆发,用户可用阿里云免费检测服务自检,建议尽快修复
2026-05-18栏目: 教程
-
云上一指禅:大数据产品DataWorks每日问答
2026-05-18栏目: 教程
-
云数据库RDS是什么?
2026-05-18栏目: 教程