
导读:
ACM CIKM 2017全称是The 26th ACM International Conference on Information and Knowledge Management,是国际计算机学会(ACM)主办的数据库、知识管理、信息检索领域的重要学术会议。
参会归来后,小编邀请了参会的同学与各位读者们第一时间分享了CIKM的参会感受。在接下来的CIKM系列分享中,你将会看到:CIKM最佳论文鉴赏,Network ding专题和Transfer Learning 专题。本篇文章是CIKM系列分享的二篇:CIKM Network ding专题分享。(CIKM最佳论文鉴赏请参考昨日的推送)

在CIKM 2017大会的171篇长论文中,有22篇Graph Mining相关,其中11篇为network representation learning(Network ding)。主会场共设置49场专题Session,Graph Representation/Graph Mining占到了其中的五分之一。Network ding太火热,沟通中发现,有部分数据库的研究人员也往这块涌进,同时,学术届也特别关注工业界在这个领域遇到的难题。定义新问题、并且融合更多信息,是推动后面新技术研究的核心。
Network ding概述
Network ding,即将网络节点、community投影到低维向量空间,用于node classification、 prediction、community detection、visualization等任务。
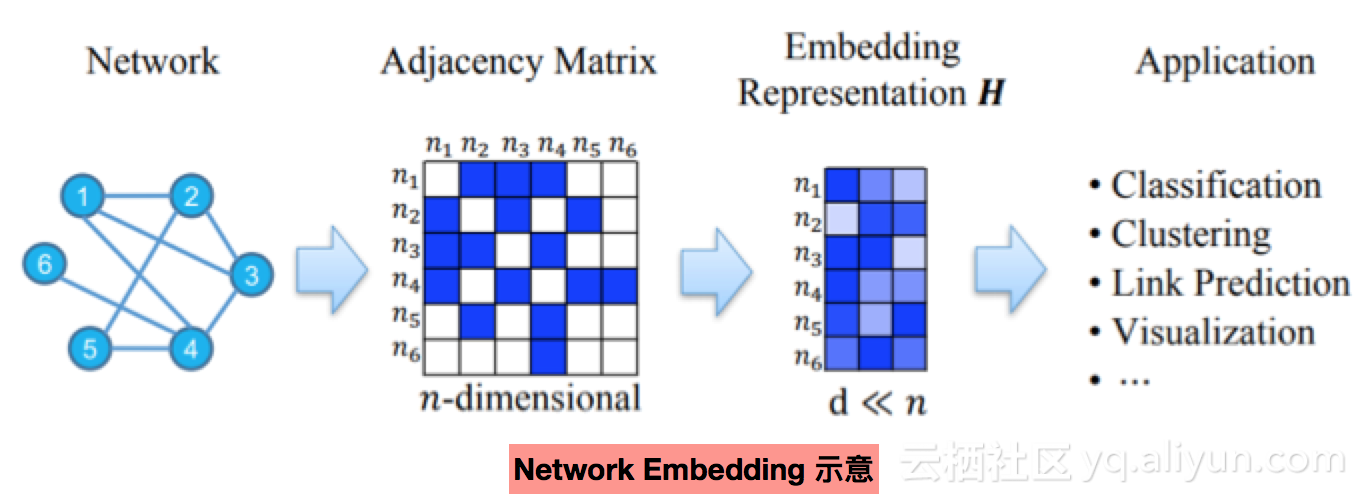
核心假设:节点间距离越近, ding向量越接近,定义LOSS为:
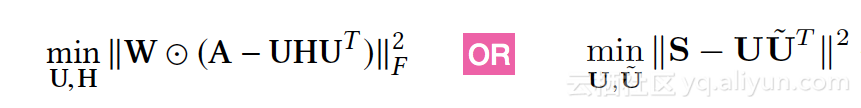
Network ding算法分类
- 基于矩阵特征向量计算(谱聚类)
目标是将相似性高的两个节点,映射到低维空间后依然保持距离相近,其损失函数定义为:

- 基于random walk框架计算(Deep Walk & Node2Vec)
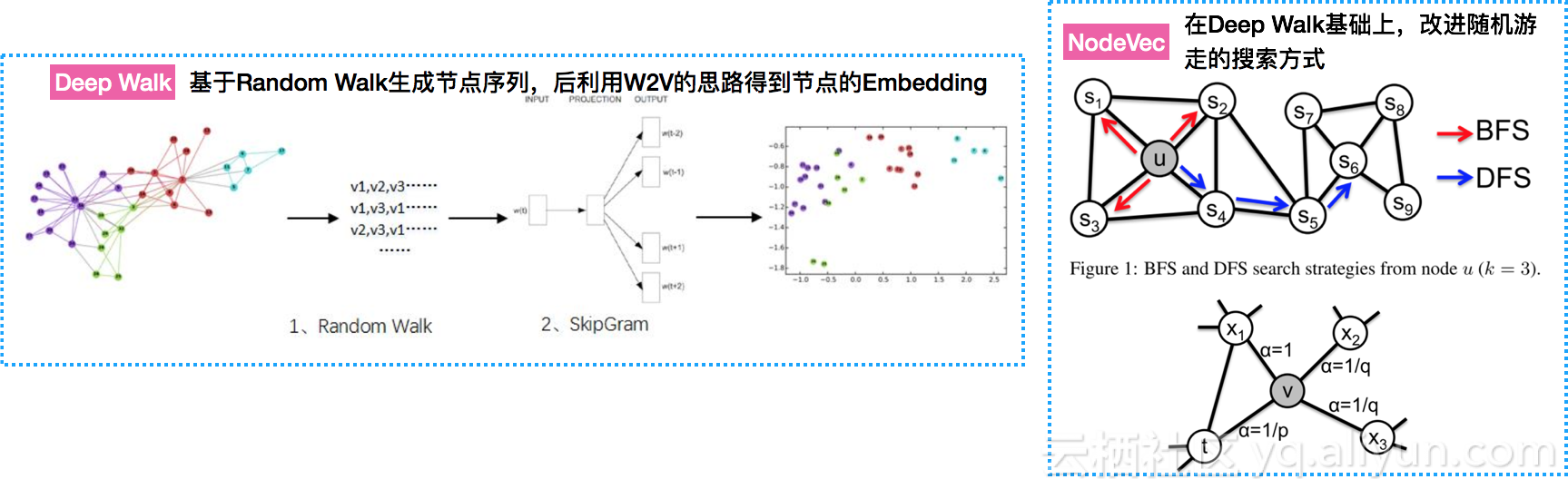
- 基于Deep Learning框架计算
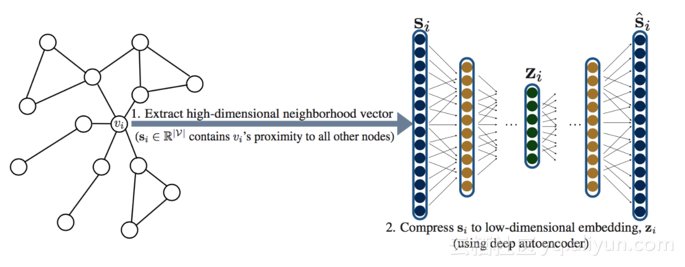
SDNE(Structural Deep Network dings)
主要思想:将节点的相似性向量 s~i~直接作为模型的输入,通过 Auto-encoder 对这个向量进行降维压缩,得到其向量化后的结果 z~i~。
其损失函数定义为:
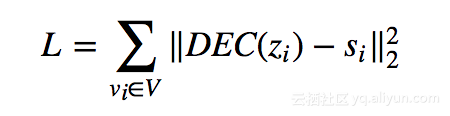
模型框架为:
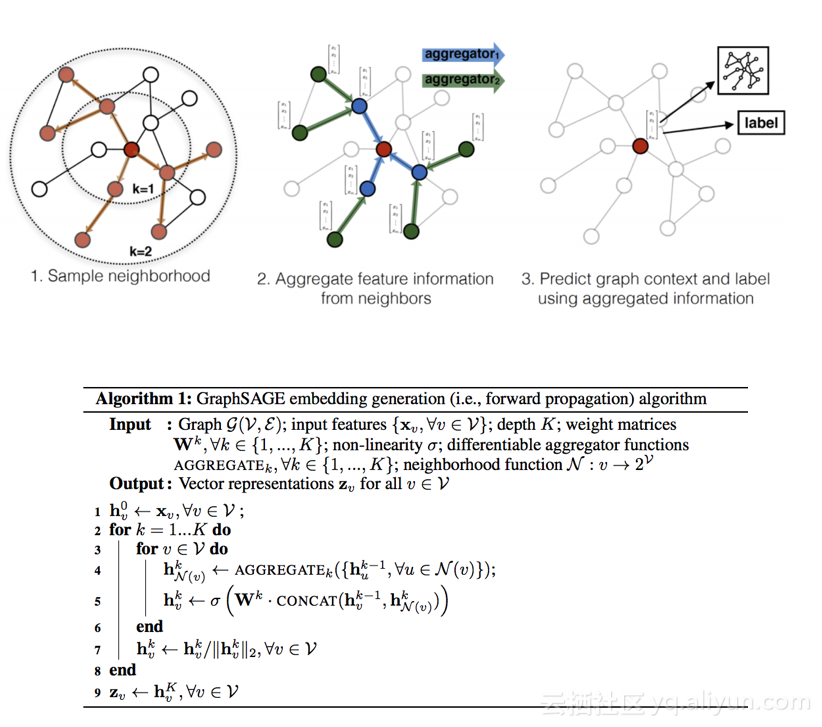
GCN(Graph Convolutional Networks)
主要思想:将节点本身及其邻居节点的属性(比如文本信息)或特征(比如统计信息)编码进向量中,引入了更多特征信息,并且在邻居节点间共享了一些特征或参数,基于最终的目标(如节点分类)做整体优化。
模型框架示意和计算流程:
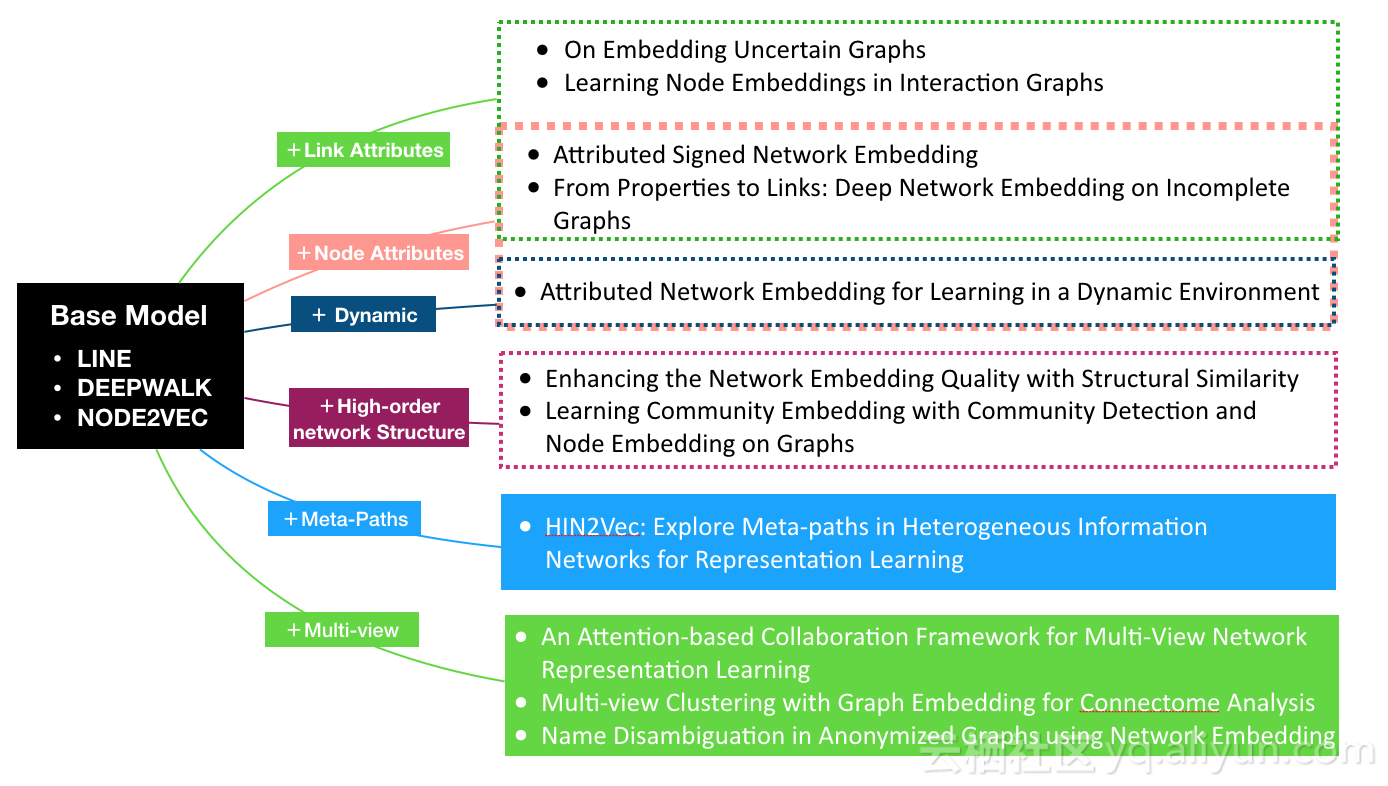
CIKM2017中Network ding的新研究方向
经典的DeepWalk、Node2Vec、LINE算法,主要基于浅层模型,但由于网络结构本身比较复杂,浅层模型往往收敛于局部最优解,无法表示更高级的非线性网络结构。而且,如何融合节点属性、边的权重、边的属性、高阶网络结构做整体 ding,以及动态网络的增量 ding/ -path/Multi-view/Attention等,提高节点分类/ 预测的精度,是当前学术研究的核心方向。
- Learning Node dings in Interaction Graphs
(https://web.cs.wpi.edu/~xkong/publications/papers/cikm17.pdf 注:本文中出现的所有网址建议请直接复制至浏览器中打开查看,下同。)
解读:网络构成中,边上带了很丰富的交互信息,如何同时利用这部分信息进行节点 ding。比如“用户”-“股票“之间的交易网络,边上带有丰富的“时间、价格、数量”特征,如何结合这些信息和网络结构,得到“用户”、“股票”的 ding向量,进而用于预测“用户”后续会买哪只股票。
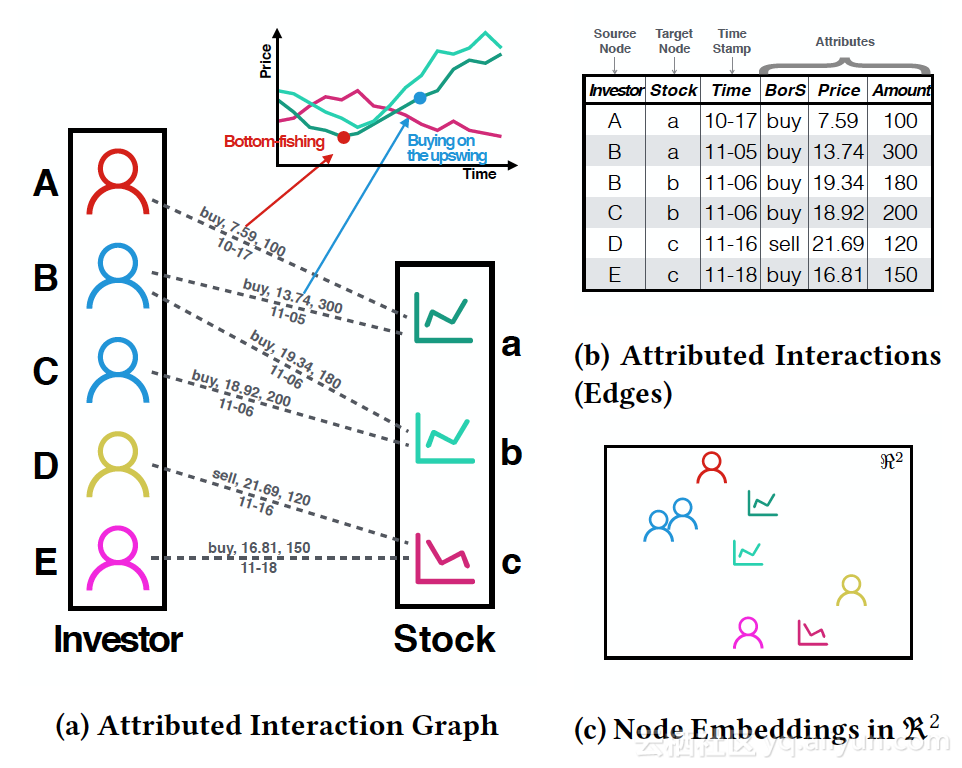
- 网络信息转换成Squence
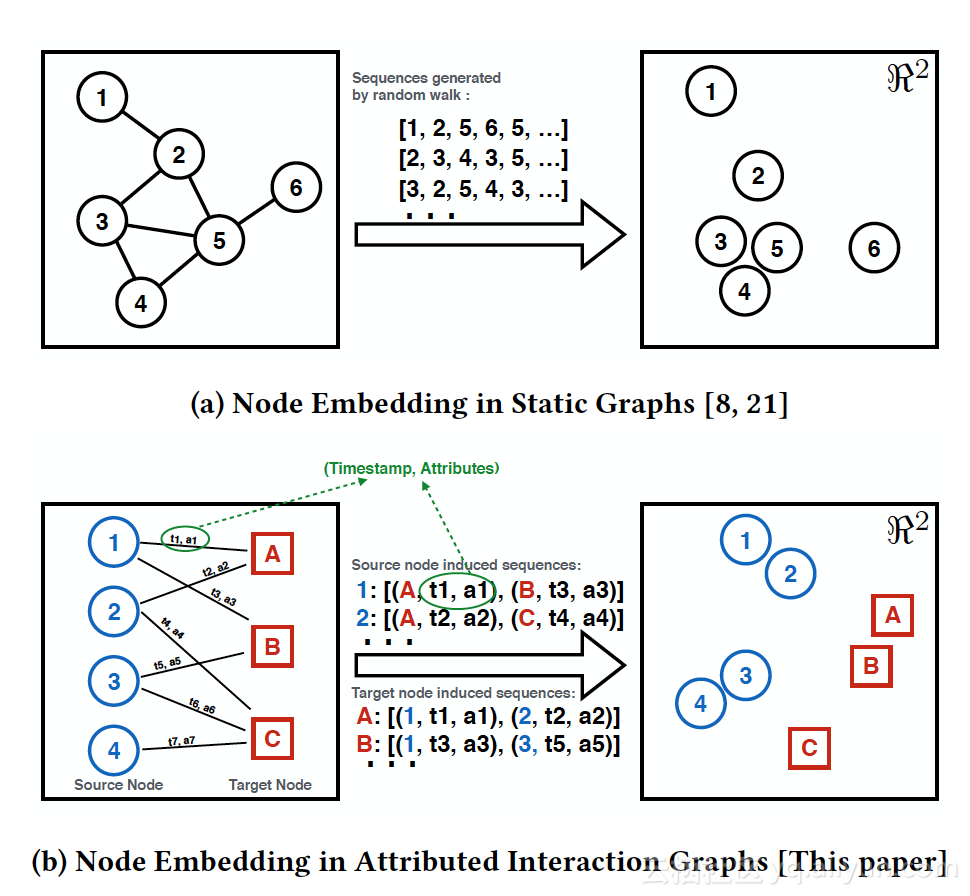
- 如何得到两种节点的 ding和预测模型(用户会买哪只股票)
1.目标定义
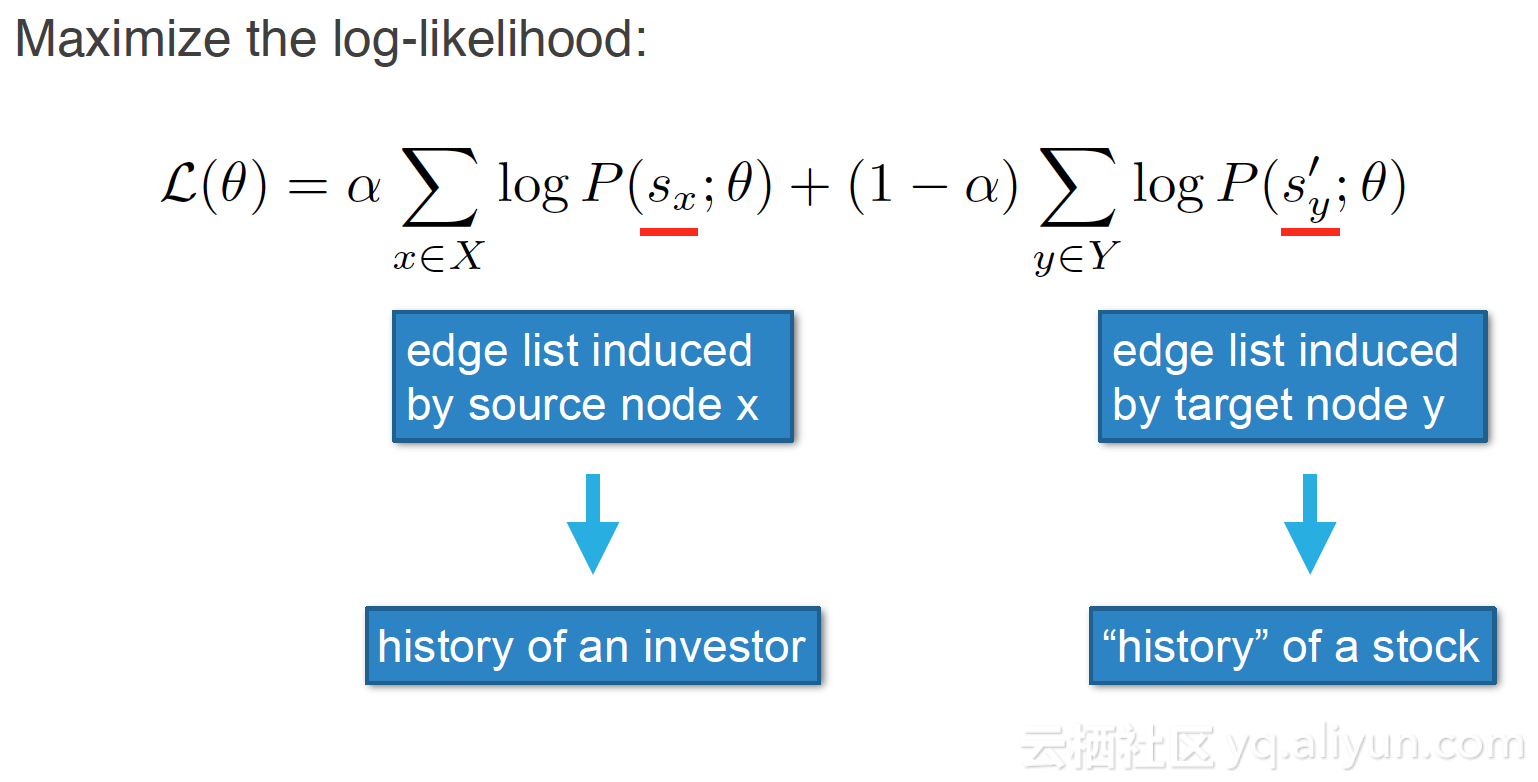
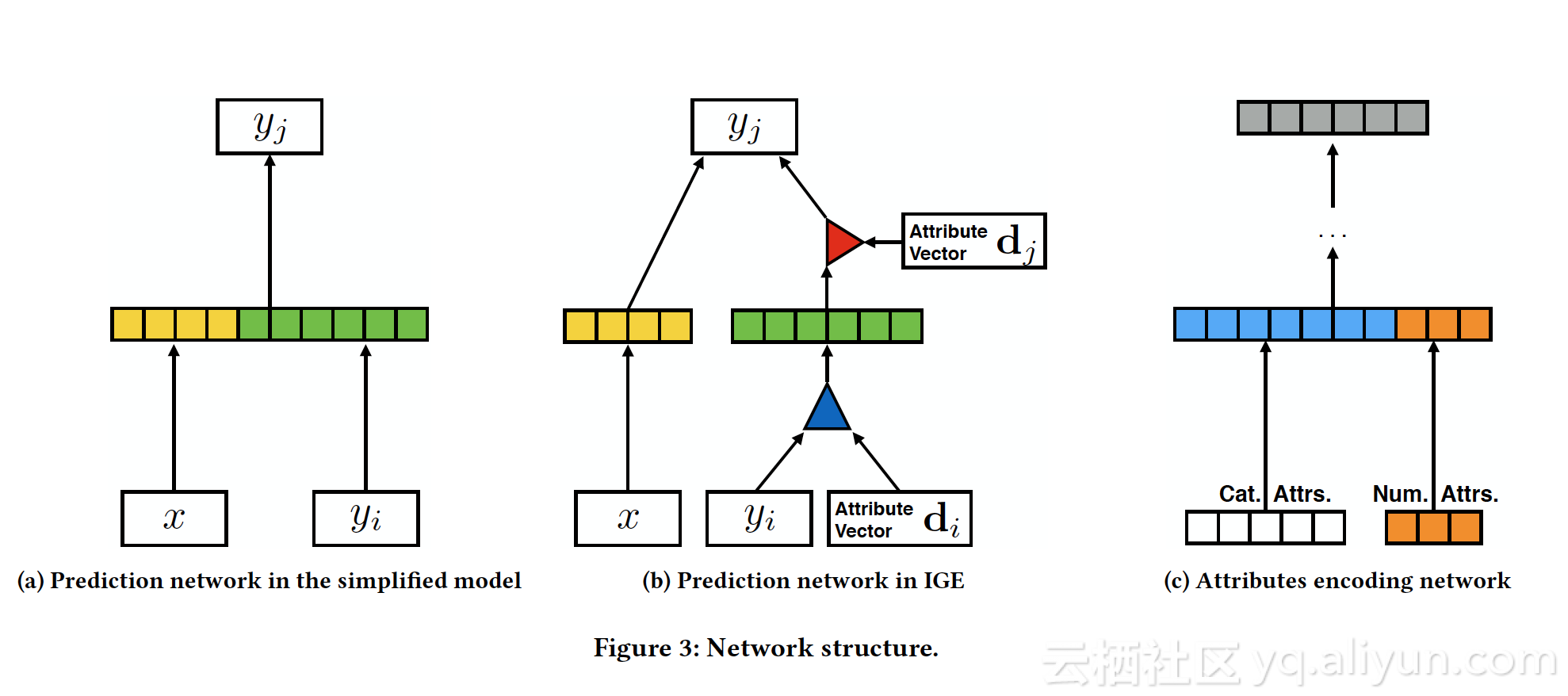
2.Model Structure
3.迭代计算,得到节点 ding(隐层)和model的参数
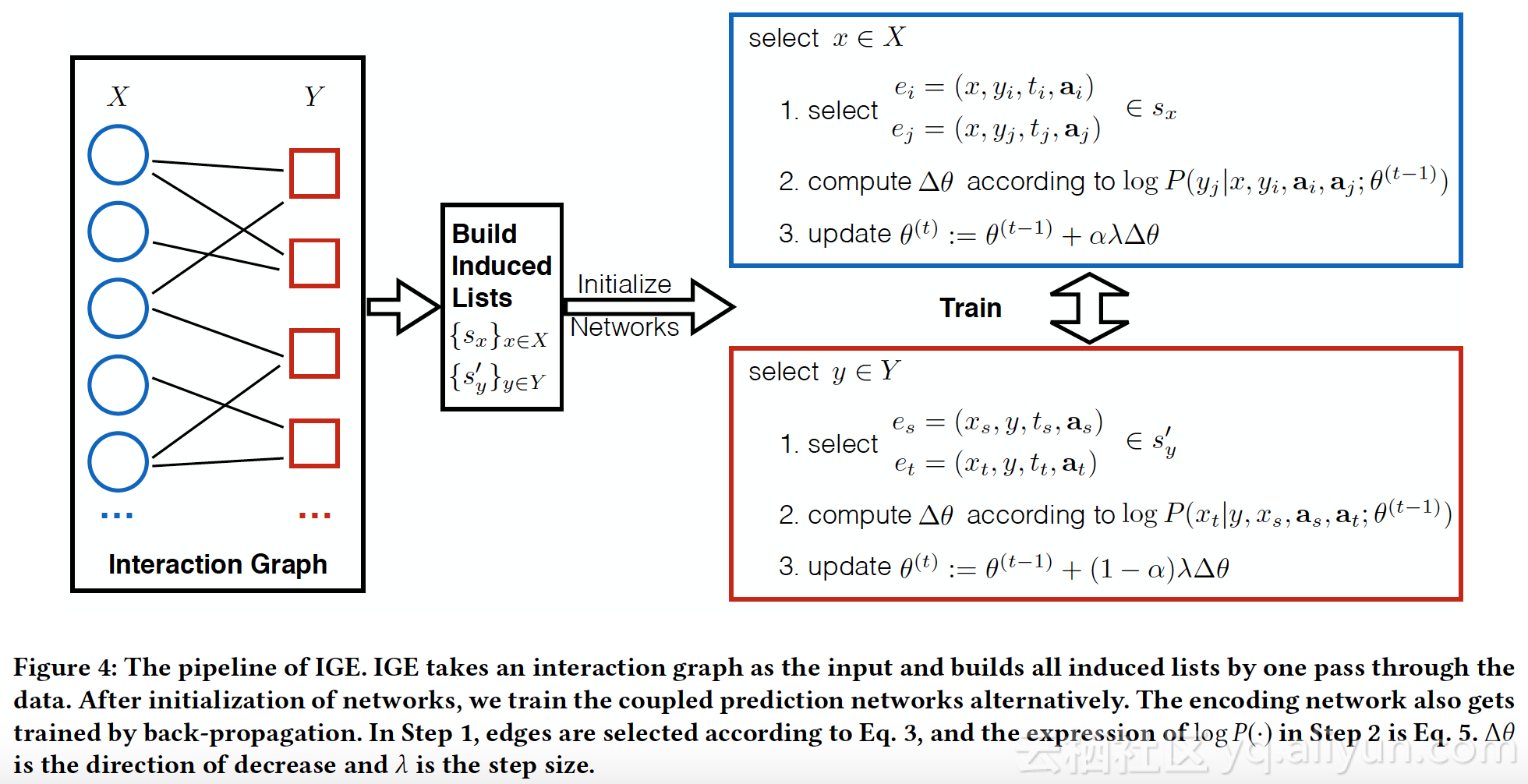
适用场景:二步图推荐
- Attributed Signed Network ding
(http://www.public.asu.edu/~swang187/publications/SNEA.pdf)
解读:融合节点属性的signed(边有Positive&Negative)网络的 ding,例如:社交网络,用户有基本属性,Positive关系有关注、点赞等,Negative关系有取消关注、不支持等。论文中的核心假设:1)从网络结构角度,“有Positive- 节点间距离” < “无直接 节点间距离” < “有negative- 节点间距离”;2)从属性相似性角度,“有Positive- 节点间距离” < “有negative- 节点间距离” < “无直接 节点间距离” 。如下图:

定义LOSS,由“网络结构+结构扩展限制+属性限制+属性扩展限制”4个模块组成,迭代求解。
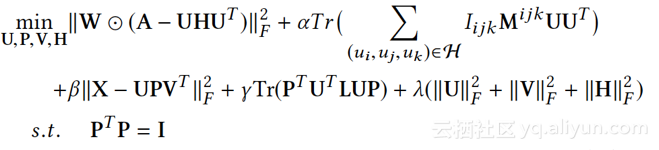
- Attributed Network ding for Learning in a Dynamic Environment
(https://arxiv.org/abs/1706.01860)
解读:动态网络 ding,节点属性和网络结构(边)随时间动态变化,如何:A)去除网络关联和节点属性中的noisy and incomplete,得到综合“属性+网络边”的representation;B) ding需要根据网络动态变化快速更新。论文算法DANE,提出同时融合节点属性和网络结构信息的无监督 ding算法,且能够快速动态更新,核心2步走:
1.离线模型得到初始consensus ding(网络结构和节点属性的 ding最大程度一致)。
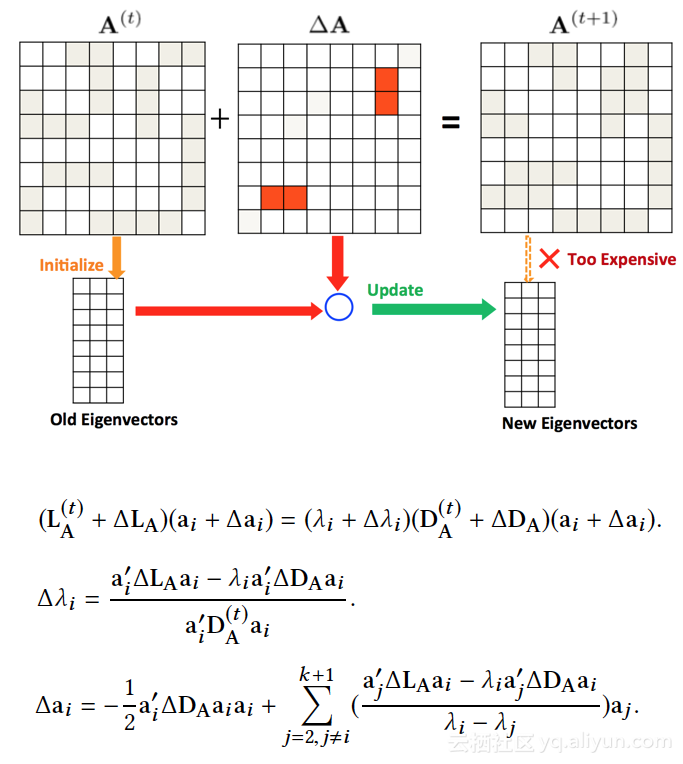
2.利用矩阵摄动理论(matrix perturbation theory)增量在线更新 ding results。
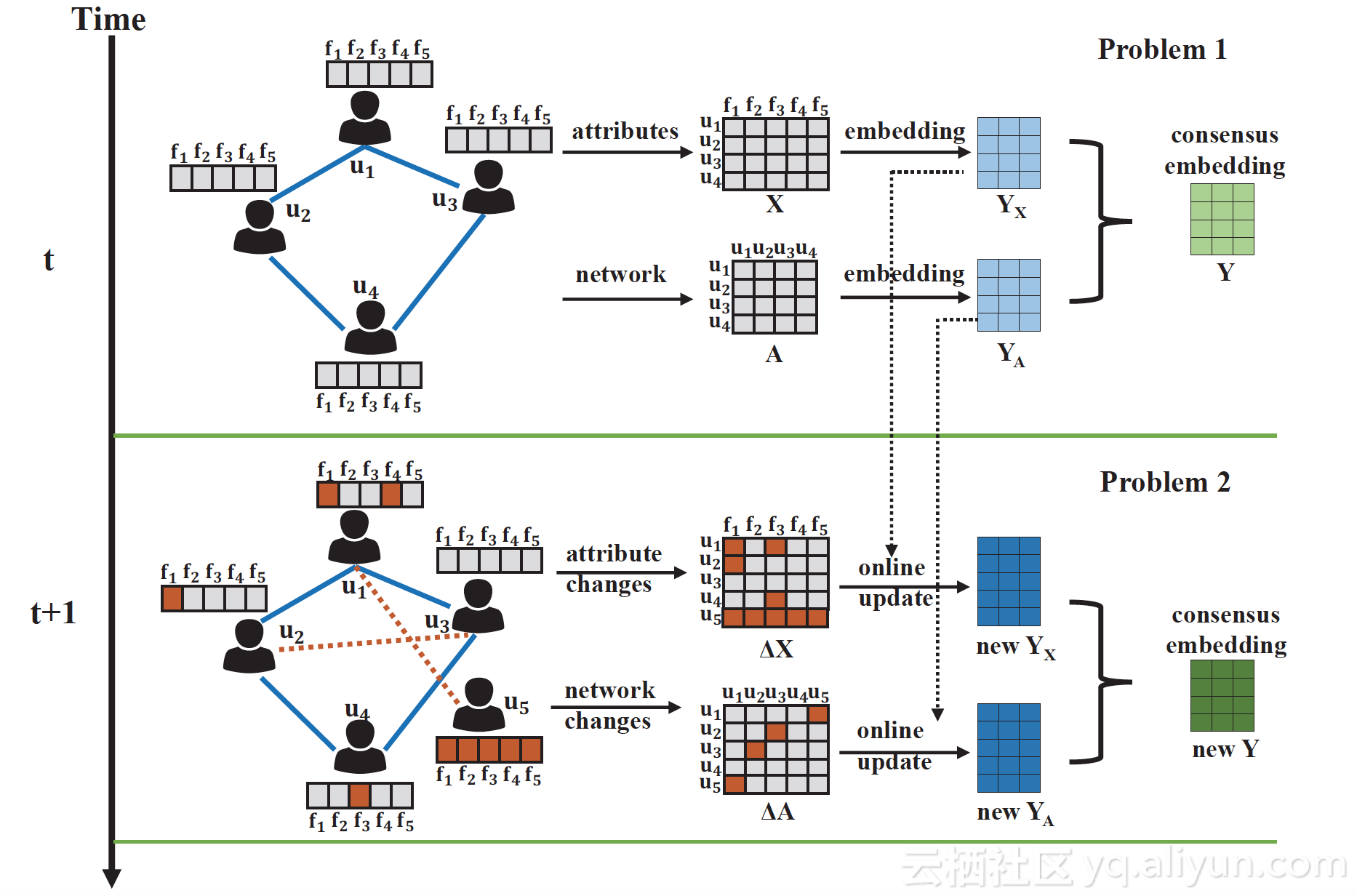
3.离线模型得到初始consensus ding
(备注:去噪的思路值得参考,用于无监督 ding优化)
基本假设:两节点存在连边,则属性一致性越高。
步骤:
1.网络结构 ding , 网络拉普拉斯矩阵的TOP-K特征向量(不包含0特征值对应的单位向量)。
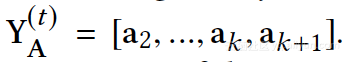
2.节点属性 ding,节点属性相似矩阵的TOPK特征向量。
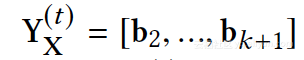
3.去除noisy,通过LOSS,使得属性 ding和网络结构具有强一致性。
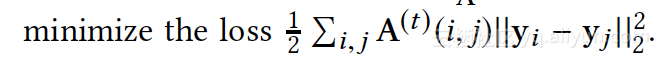
各种推导,最终的一致表达为:
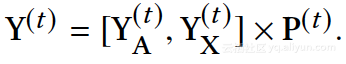
实时在线增量更新计算
该方法有两个隐含限制:1)节点的属性和网络的形成相关,比如“兴趣社交网络,有共同爱好的节点更容易连接”、“黑产网络,节点的异常属性和网络结构相关”;2)动态更新,要求不同STEP,网络节点属性或者 变化很小(文中实验数据变化<0.5%)。
适用场景:实时风险识别,快速更新高维信息的向量表达。
- Learning Community ding with Community Detection and Node ding on Graphs
(http://sentic.net/community- ding.pdf)
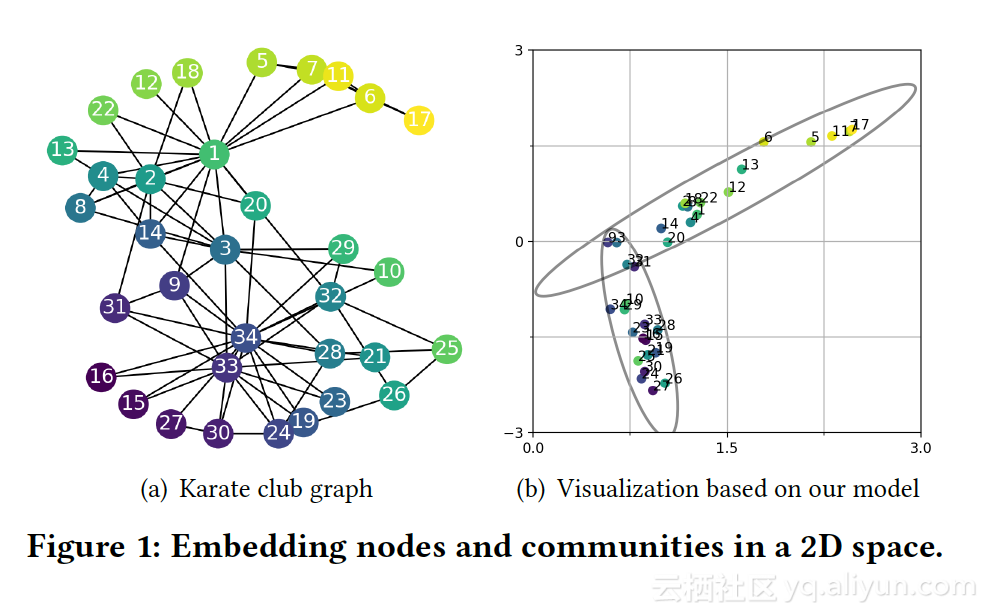
解读:community ding,网络社区结构的向量表达,通常是其节点集合的向量分布(多元高斯分布)。基本假设:节点 ding,与其所在社区的中心节点相似度高,这个假设约束有助于Node ding更好的引入网络高阶信息,进而更好的支持community detection。当前,community ding, community detection and node ding这3大任务通常都作为独立的问题去解,本文提出一个闭环算法结构,算法的输出同时包含节点向量、社区向量以及最优社区结构划分。
community ding 示意:
闭环 ding框架
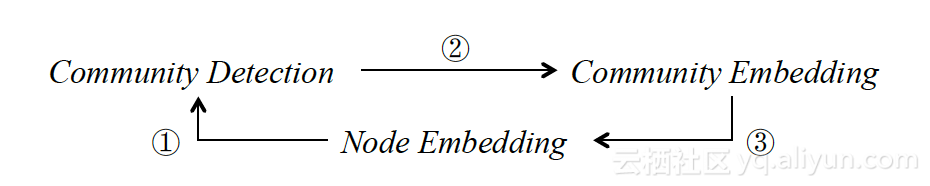
一般解法,每个步骤独立计算,信息之间没有得到有效互补
1.基于谱聚类、LPA等得到社区划分结果。
2.基于DeepWalk、Node2Vec等得到节点的 ding。
3.融合社区所有节点的 ding信息,得到Community的分布(多元高斯模型)。
论文的“一站式”解法,定义LOSS,梯度求解,复杂度linear to the graph size(|V|+|E|)
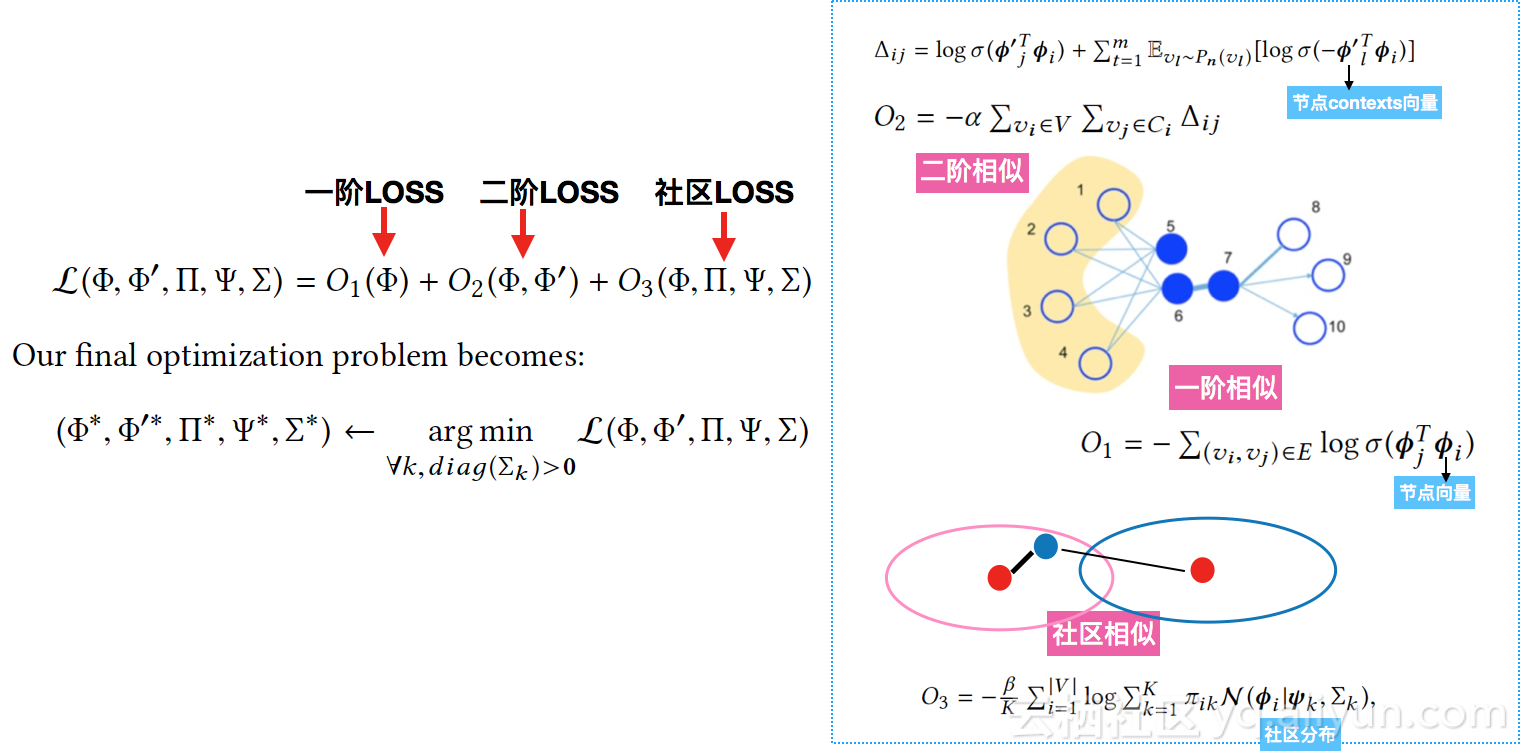
应用场景:通过节点增量 ding,实现实时团伙识别。
- HIN2Vec: Explore -paths in Heterogeneous Information Networks for Representation Learning
解读:提出异构网络中,如何融合网络结构和不同关系( -path)信息框架,得到节点的 ding,核心创新点:通过将边的信息转化成 -path,整个模型目标是预测 -path,从而达到融合异构网络边类型信息的效果。整个方案框架分2个步骤:
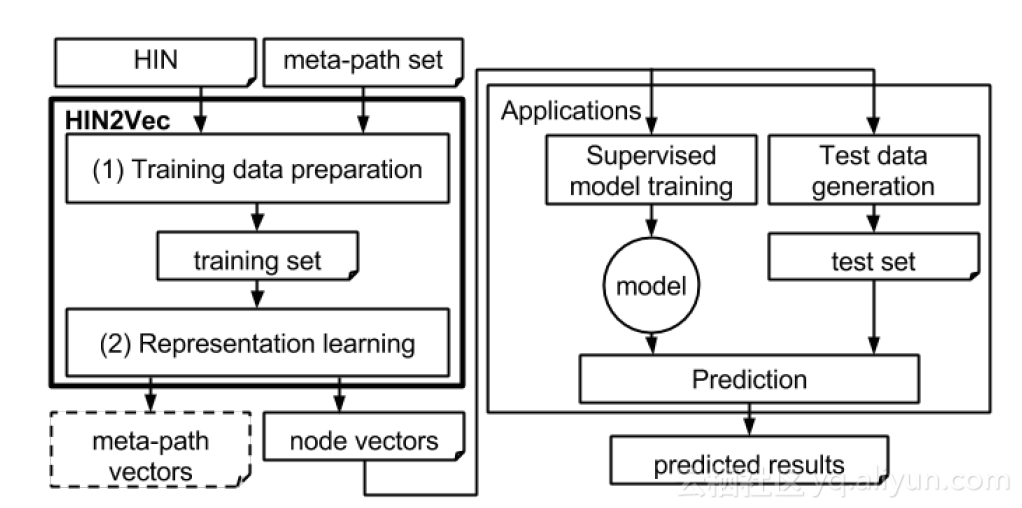
1.训练数据准备
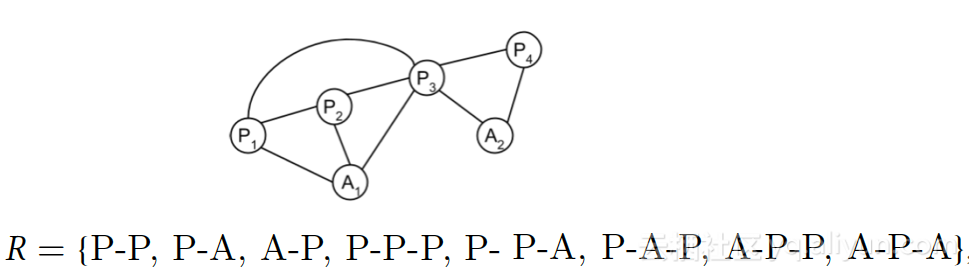
基于randwalk将网络转化成节点序列,并定义 -path。
节点做onehot编码,选定2个节点X、Y作为输入,对应的输出为可能的 -path。
例如:节点P1、A1,可能的 -path为P-A、P-P-A ,模型的目标为[0,1,0,0,1,0,0,0]
2.node ding学习
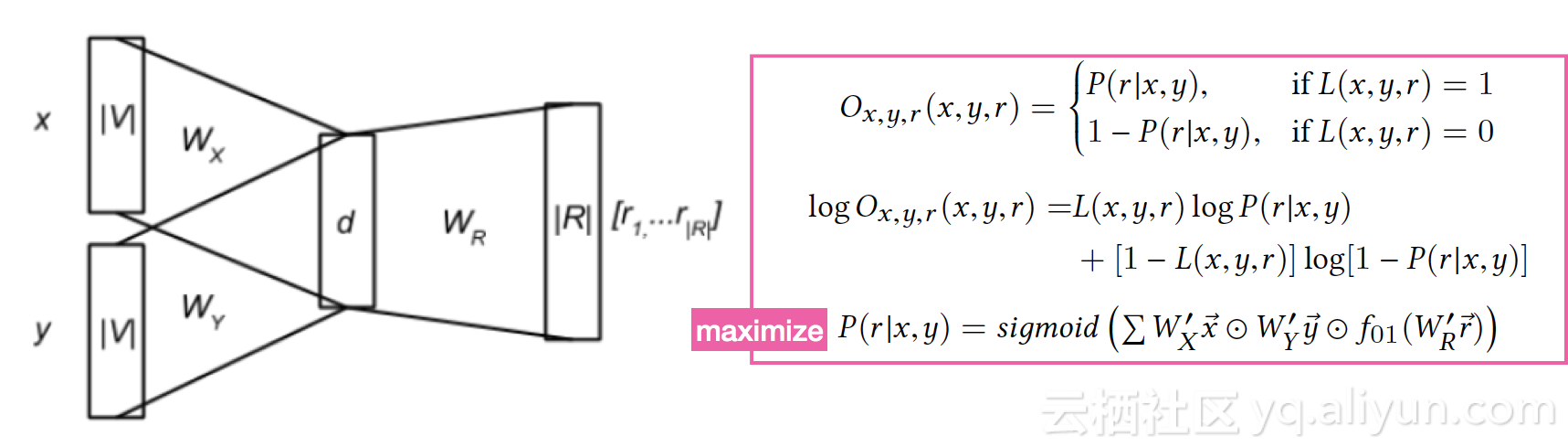
隐层的d维向量即节点的 ding信息。
应用场景:异构网络中,提取异构路径信息的新思路。
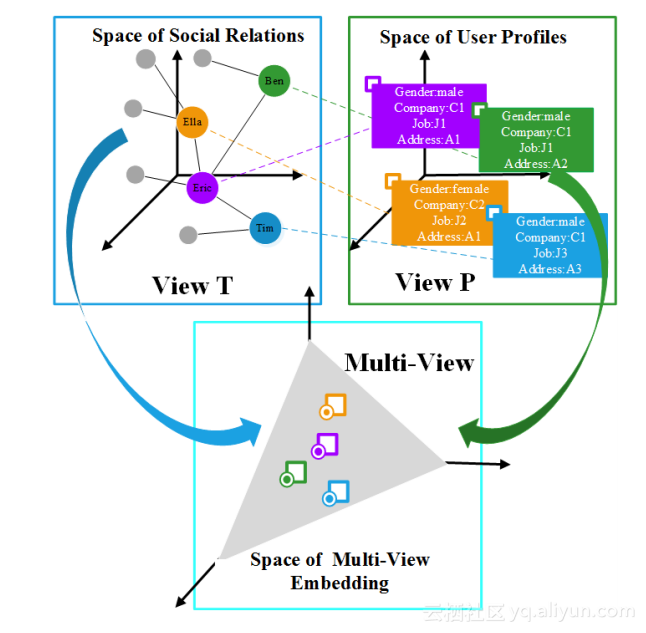
- An Attention- d Collaboration work for Multi-View Network Representation Learning
解读:区分网络多种构成方式,比如:社交关联、资金转账网、属性相似性网等,从不同的视角分别做节点 ding,再基于Attention机制融合不同的 ding结果。整体框架如下图:
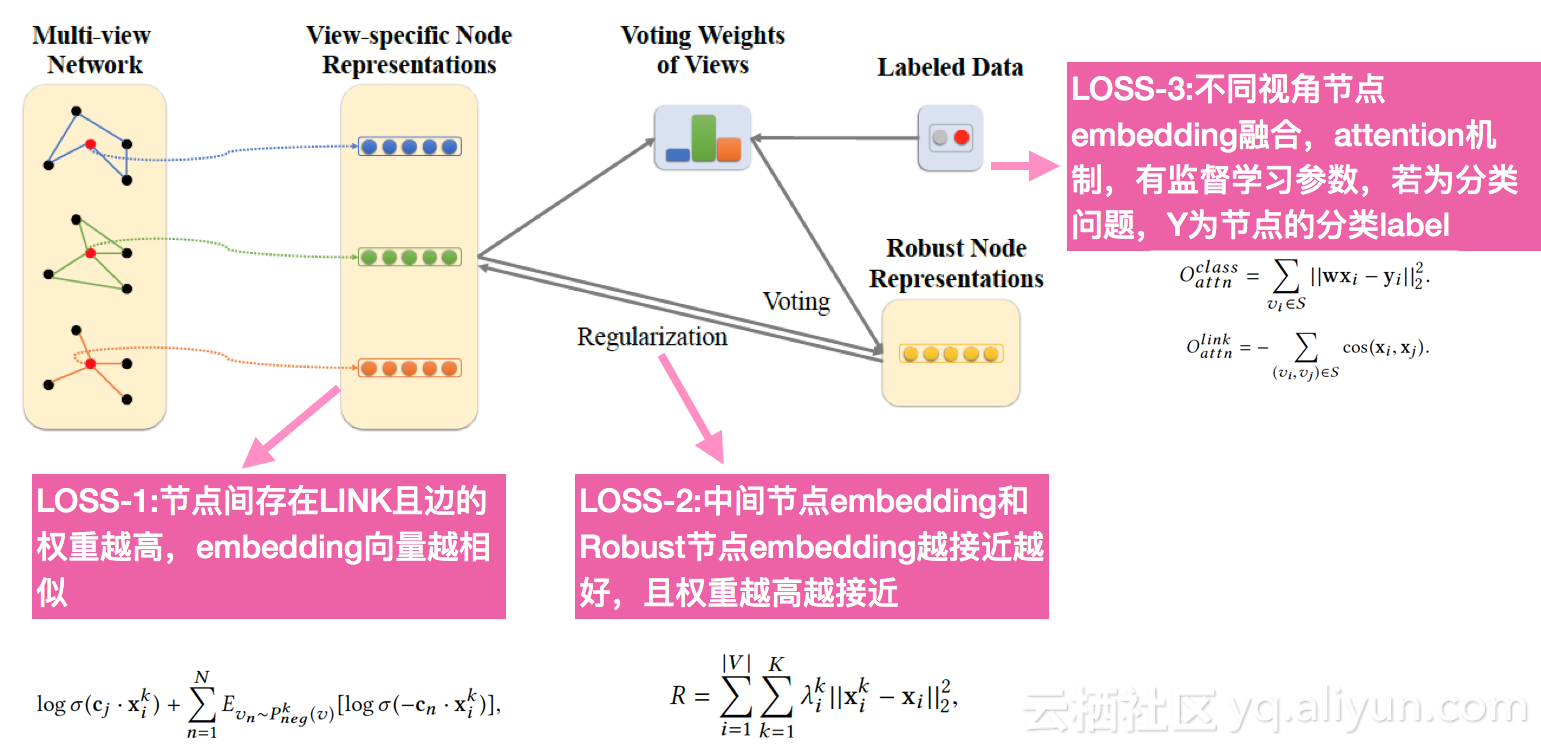
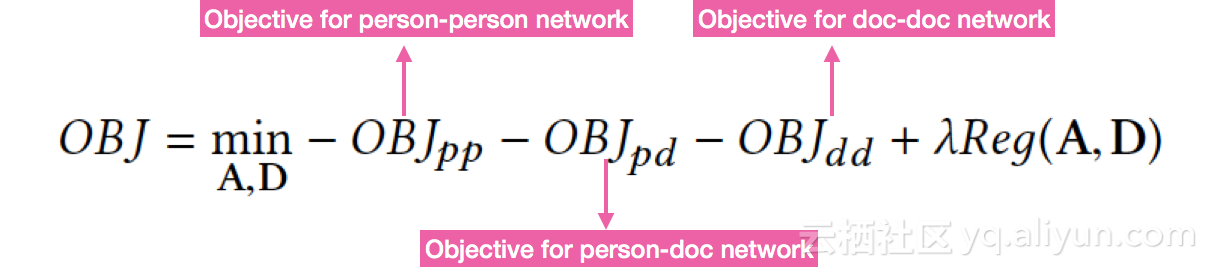
整体优化目标LOSS:
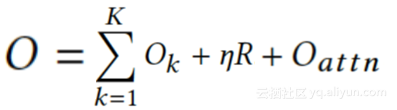
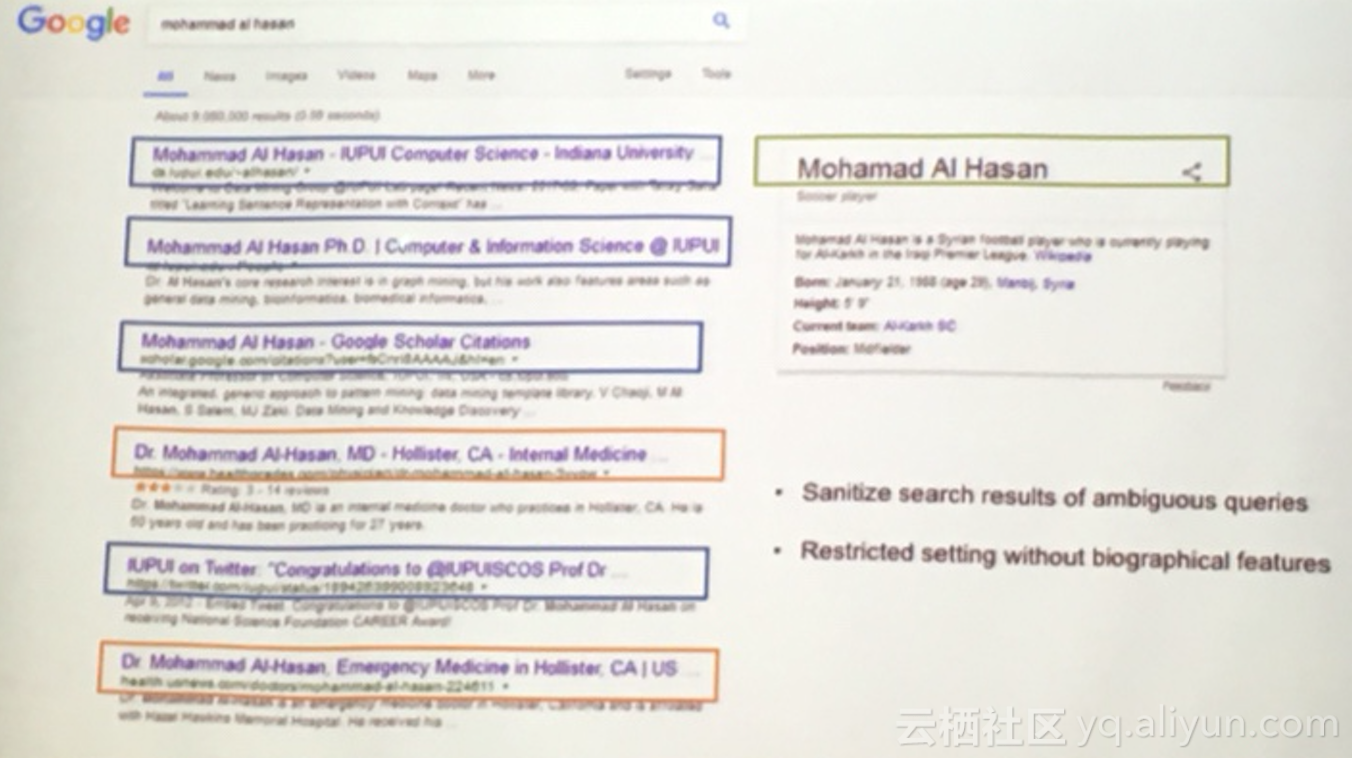
- Name Disambiguation in Anonymized Graphs using Network ding
解读:重名的人很多,而独一无二的指纹/DNA信息通常很难获取或因涉及用户隐私不能使用,如何正确区分同名不同人。论文中提出仅依赖关系网 ding的方法,能够将同名不同人的聚类区分。例如:在GOOGLE搜索人名,希望同一自然人的文章能够一起顺序展示,如下图,不同的颜色代表不同的自然人:
针对上述问题,论文先构建“用户-用户”、“用户-论文”、“论文-论文”组成的异构网络,如下图:
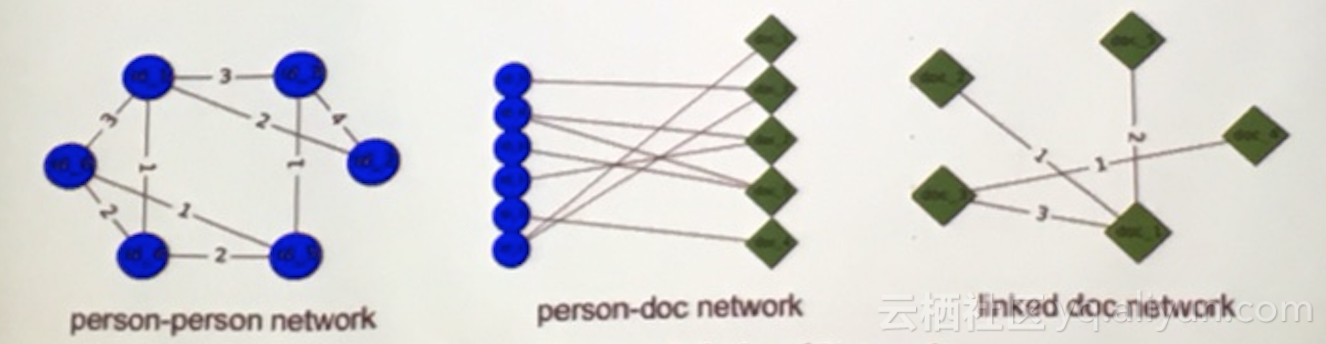
基本假设:存在 的节点间 ding距离 < 无 的节点间 ding距离,定义异构网络的LOSS,计算梯度迭代求解,得到“Document”的 ding后聚类。
- From Properties to s: Deep Network ding on Incomplete Graphs
这篇论文主要想解决的问题是:图上的节点以及改节点上的属性改如何总体起来去提取对应的graph ding,其基本方法是通过组合multi-view和SDNE两个概念而产生的:
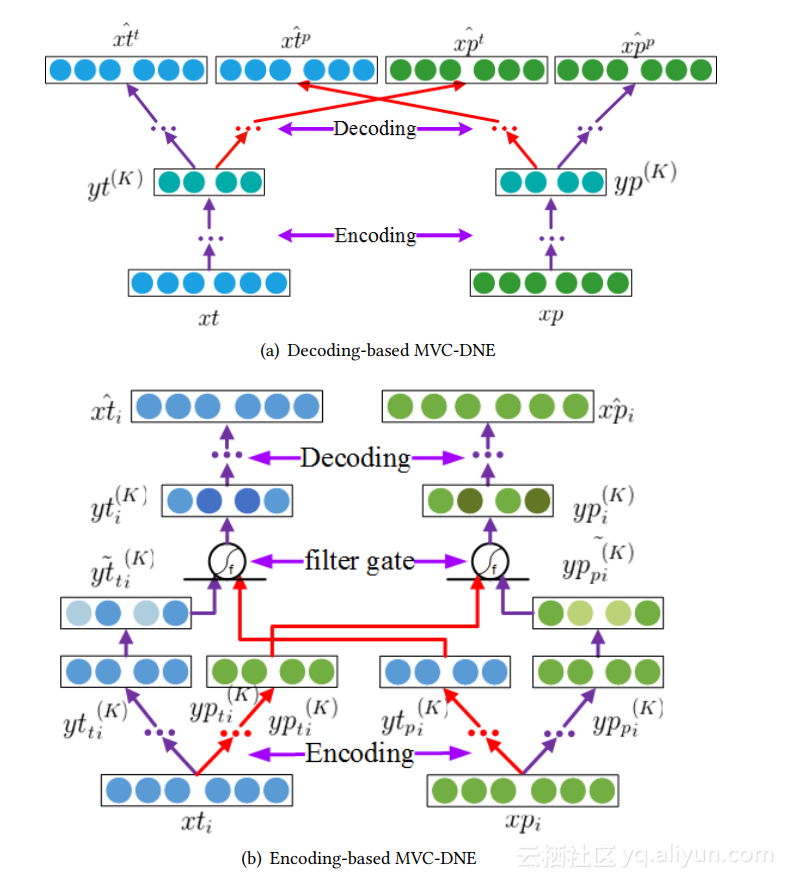
其中一路是该节点的邻居结构,一路是该节点的属性数据。两路数据分别使用autoencoder进行学习,但在学习过程中会将两路数据在中间过程中进行合并,从而达到作者所说的节点和其属性的合并学习。
同时,使用基于autoencoder的方式来获得图的 ding有一个潜在的好处,可以很快的获得之前在学习的时候还没有的节点对应的 ding,当然这也是有一定限制的,即新加入的点的邻居只能限定在已有的图中。
同时这种方法的一个问题在于训练的时间复杂度会很高,在处理较大的图的时候可能会面临训练时间过长的问题。
继续阅读与本文标签相同的文章
Delphi7与数据库应用
自定义组件的v-model
-
越来越“聪明”的人工智能可能会取代人类!是否属实?
2026-05-18栏目: 教程
-
全球重磅数据周来袭,这些大事将影响本周市场
2026-05-18栏目: 教程
-
阿里云Hi拼团优惠活动全新升级,活动变化亮点总结
2026-05-18栏目: 教程
-
CNC加工中心G41/G42指令是什么意思?怎么使用?
2026-05-18栏目: 教程
-
百度:公立机构官网保护计划已引入超10万家公立机构官网
2026-05-18栏目: 教程