
第2章 网络爬虫基础
网络爬虫实现的思想是模拟用户使用浏览器向网站发送请求,网站响应请求后,将HTML文档发送过来,爬虫再对网页做信息提取和存储。因此,了解浏览器与网站服务器之间的通信方式和交互过程,理解HTML页面的组织和结构,掌握页面信息的提取和存储技术,能进一步加深对网络爬虫原理的理解。
2.1 HTTP基本原理
下面来看一下用户从浏览器输入某个网址到获取网站内容的整个过程。该过程主要分为4个步骤,如图2-1所示。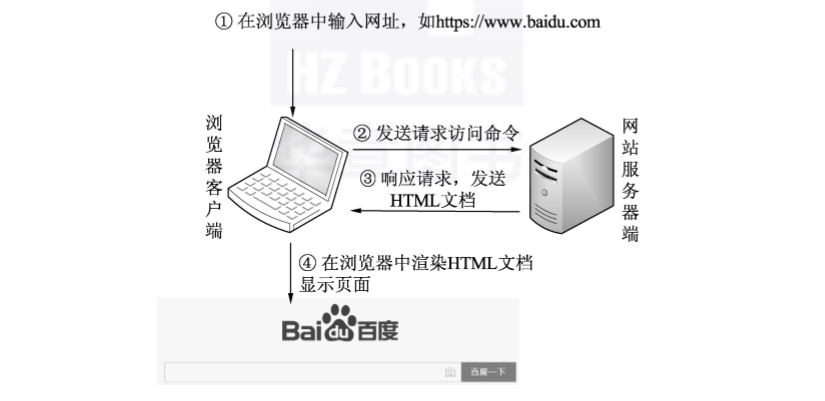
图2-1 访问网站的过程
(1)在浏览器中输入URL地址(如百度地址https://www.baidu.com),然后回车。
(2)在浏览器中向网站服务器发送请求访问的命令。
(3)网站服务器响应请求后,向浏览器发送HTML文档(也可以是图片、视频和JSON数据等其他资源)
继续阅读与本文标签相同的文章
-
对比开源cms三巨头Joomla wordpress drupal哪个才是真正的王者
2026-05-16栏目: 教程
-
Linux 知识地图
2026-05-16栏目: 教程
-
如何快速定位Android端GPU问题之工具介绍
2026-05-16栏目: 教程
-
蚂蚁金服有哪些金融特色的机器学习技术?
2026-05-16栏目: 教程
-
2019双11阿里云拼团服务器比空间还便宜
2026-05-16栏目: 教程