
本文来自2019杭州云栖大会大数据生态专场中的分享《Spark Relational Cache实现亚秒级响应的交互式分析》
作者:王道远,花名健身,阿里云EMR技术专家,Apache Spark活跃贡献者,主要关注大数据计算优化相关工作。
视频链接:https://tianchi.aliyun.com/course/video?spm=5176.12282027.0.0.369a379cZrDREc&liveId=41101

分四部分介绍阿里云EMR团队在Spark Relational Cache上的工作。
项目介绍
EMR为用户提供了丰富的应用,可以进行各种数据分析。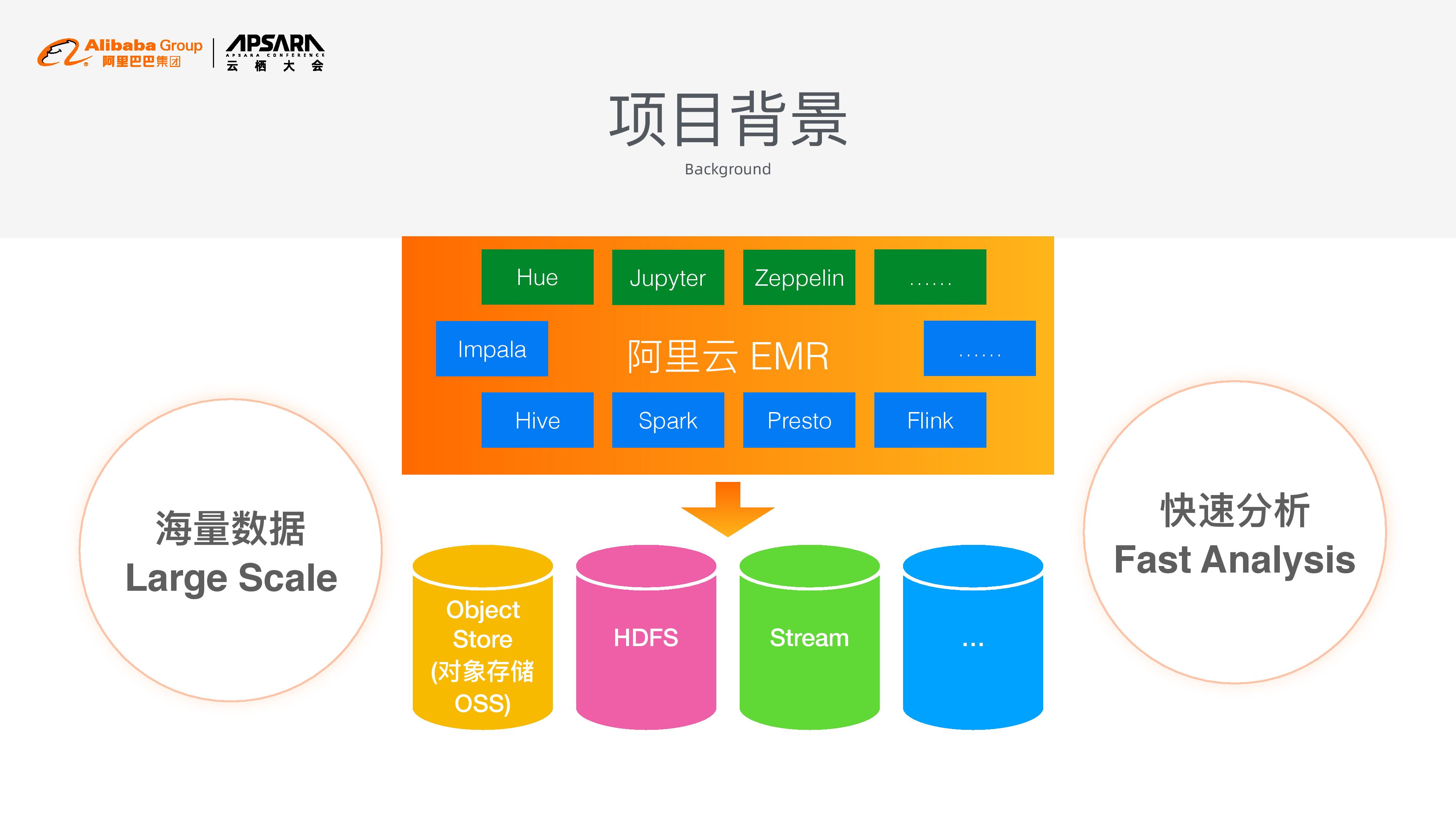
在云上进行数据分析时,需要在支持大规模数据的同时,实现快速的分析。Spark目前用户数量庞大,然而Spark目前的数据缓存机制,不支持缓存在跨会话共享,也需要使用
继续阅读与本文标签相同的文章
上一篇 :
Dremio扩展达梦数据库连接
下一篇 :
JavaScript基本数据类型分析
-
夯实Java基础系列15:Java注解简介和最佳实践
2026-05-17栏目: 教程
-
Linux系统:常用Linux系统管理命令总结
2026-05-17栏目: 教程
-
Linux系统:Centos7环境搭建Redis单台和集群环境
2026-05-17栏目: 教程
-
Linux系统:centos7下搭建Rocketmq4.3中间件,配置监控台
2026-05-17栏目: 教程
-
MySQL数据以全量和增量方式,同步到ES搜索引擎
2026-05-17栏目: 教程