
F X
1 什么是F X
- F X是基于f 的分布式离线数据同步框架,实现了多种异构数据源之间高效的数据迁移。
不同的数据源头被抽象成不同的Reader插件,不同的数据目标被抽象成不同的Writer插件。理论上,F X框架可以支持任意数据源类型的数据同步工作。作为一套生态系统,每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。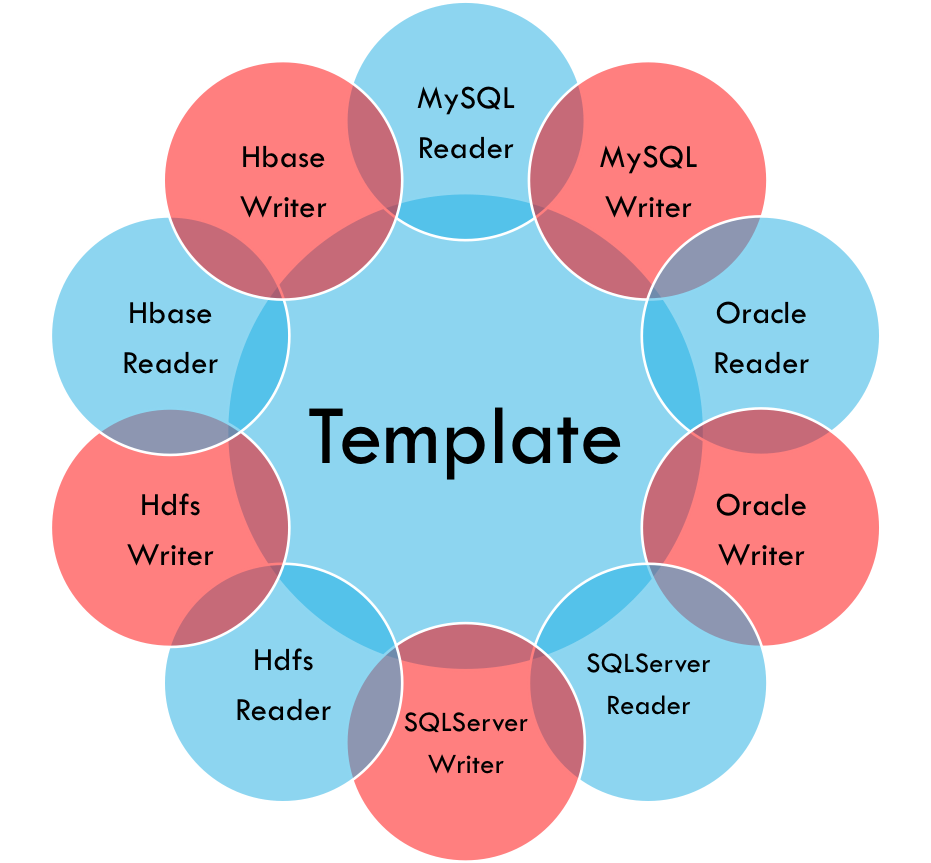
2 工作原理
在底层实现上,F X依赖F ,数据同步任务会被翻译成StreamGraph在F 上执行,工作原理如下图: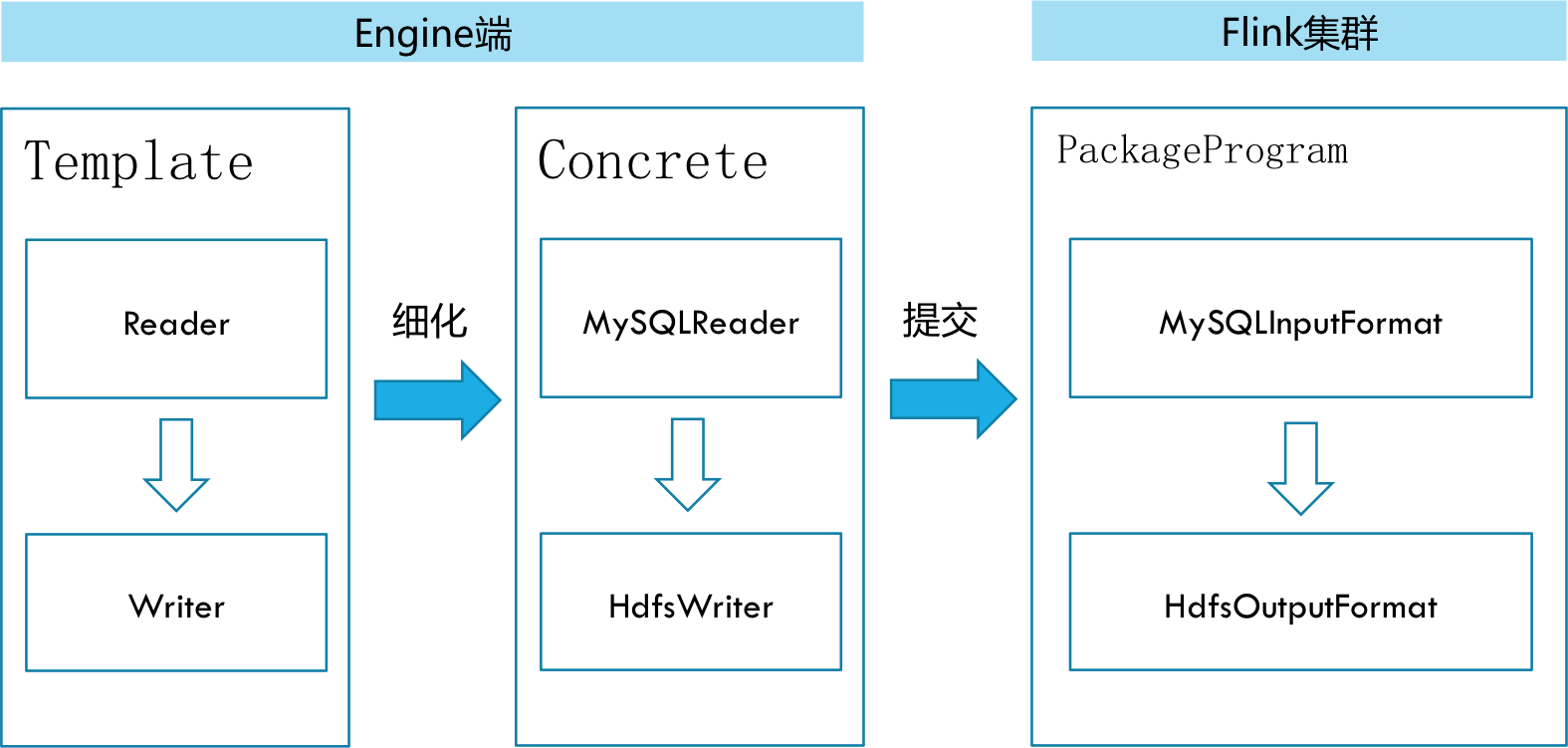
3 快速起步
3.1 运行模式
- 单机模式:对应F 集群的单机模式
- standalone模式:对应F 集群的分布式模式
- yarn模式:对应F 集群的yarn模式
3.2 执行环境
- Java: JDK8及以上
- F 集群: 1.4及以上(单机模式不需要安装F 集群)
- 操作系统:理论上不限,但是目前只编写了shell启动脚本,用户可以可以参考shell脚本编写适合特定操作系统的启动脚本。
3.3 打包
进入项目根目录,使用maven打包:
mvn clean package -Dmaven.test.skip打包结束后,项目根目录下会产生bin目录和plugins目录,其中bin目录包含F X的启动脚本,plugins目录下存放编译好的数据同步插件包
3.4 启动
3.4.1 命令行参数选项
model
描述:执行模式,也就是f 集群的工作模式
- local: 本地模式
- standalone: 独立部署模式的f 集群
- yarn: yarn模式的f 集群,需要提前在yarn上启动一个f session,使用默认名称"F session cluster"
- 必选:否
- 默认值:local
job
- 描述:数据同步任务描述文件的存放路径;该描述文件中使用json字符串存放任务信息。
- 必选:是
- 默认值:无
plugin
- 描述:插件根目录地址,也就是打包后产生的plugins目录。
- 必选:是
- 默认值:无
f conf
- 描述:f 配置文件所在的目录(单机模式下不需要),如/hadoop/f -1.4.0/conf
- 必选:否
- 默认值:无
yarnconf
- 描述:Hadoop配置文件(包括hdfs和yarn)所在的目录(单机模式下不需要),如/hadoop/etc/hadoop
- 必选:否
- 默认值:无
3.4.2 启动数据同步任务
- 以本地模式启动数据同步任务
bin/f x -mode local -job /Users/softfly/company/f -data-transfer/jobs/task_to_run.json -plugin /Users/softfly/company/f -data-transfer/plugins -confProp "{"f .checkpoint.interval":60000,"f .checkpoint.stateBackend":"/f _checkpoint/"}" -s /f _checkpoint/0481473685a8e7d22e7bd079d6e5c08c/chk-*- 以standalone模式启动数据同步任务
bin/f x -mode standalone -job /Users/softfly/company/f -data-transfer/jobs/oracle_to_oracle.json -plugin /Users/softfly/company/f -data-transfer/plugins -f conf /hadoop/f -1.4.0/conf -confProp "{"f .checkpoint.interval":60000,"f .checkpoint.stateBackend":"/f _checkpoint/"}" -s /f _checkpoint/0481473685a8e7d22e7bd079d6e5c08c/chk-*- 以yarn模式启动数据同步任务
bin/f x -mode yarn -job /Users/softfly/company/f x/jobs/mysql_to_mysql.json -plugin /opt/dtstack/f plugin/syncplugin -f conf /opt/dtstack/myconf/conf -yarnconf /opt/dtstack/myconf/hadoop -confProp "{"f .checkpoint.interval":60000,"f .checkpoint.stateBackend":"/f _checkpoint/"}" -s /f _checkpoint/0481473685a8e7d22e7bd079d6e5c08c/chk-*4 数据同步任务模版
从最高空俯视,一个数据同步的构成很简单,如下:
{ "job": { "setting": {...}, "content": [...] }}数据同步任务包括一个job元素,而这个元素包括setting和content两部分。
- setting: 用于配置限速、错误控制和脏数据管理
- content: 用于配置具体任务信息,包括从哪里来(Reader插件信息),到哪里去(Writer插件信息)
4.1 setting
"setting": { "speed": {...}, "errorLimit": {...}, "dirty": {...} }setting包括speed、errorLimit和dirty三部分,分别描述限速、错误控制和脏数据管理的配置信息
4.1.1 speed
"speed": { "channel": 3, "bytes": 0 }- channel: 任务并发数
- bytes: 每秒字节数,默认为 Long.MAX_VALUE
4.1.2 errorLimit
"errorLimit": { "record": 10000, "percentage": 100 }- record: 出错记录数超过record设置的条数时,任务标记为失败
- percentage: 当出错记录数超过percentage百分数时,任务标记为失败
4.1.3 dirty
"dirty": { "path": "/tmp", "hadoopConfig": { "fs.default.name": "hdfs://ns1", "dfs.nameservices": "ns1", "dfs.ha.namenodes.ns1": "nn1,nn2", "dfs.namenode.rpc-address.ns1.nn1": "node02:9000", "dfs.namenode.rpc-address.ns1.nn2": "node03:9000", "dfs.ha.automatic-failover.enabled": "true", "dfs.client.failover.proxy.provider.ns1": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider", "fs.hdfs.impl.disable.cache": "true" } }- path: 脏数据存放路径
- hadoopConfig: 脏数据存放路径对应hdfs的配置信息(hdfs高可用配置)
4.1.4 restore
"restore": { "isRestore": false, "restoreColumnName": "", "restoreColumnIndex": 0 }restore配置请参考断点续传
4.2 content
"content": [ { "reader": { "name": "...", "parameter": { ... } }, "writer": { "name": "...", "parameter": { ... } } } ]- reader: 用于读取数据的插件的信息
- writer: 用于写入数据的插件的信息
reader和writer包括name和parameter,分别表示插件名称和插件参数
4.3 数据同步任务例子
详见f x-examples子工程
5. 数据同步插件
5.1 读取插件
- 关系数据库读取插件
- 分库分表读取插件
- HDFS读取插件
- H 读取插件
- Elasticsearch读取插件
- Ftp读取插件
- Odps读取插件
- MongoDB读取插件
- Stream读取插件
- Carbondata读取插件
- MySQL binlog读取插件
- KafKa读取插件
5.2 写入插件
继续阅读与本文标签相同的文章
下一篇 :
MySQL8.0之窗口函数
-
如何避免新代码变包袱?阿里通用方法来了!
2026-05-17栏目: 教程
-
【2019 杭州·云栖大会】Alibaba Cloud Linux 2-阿里云Linux操作系统全面解析
2026-05-17栏目: 教程
-
关于容器迁移、运维、查错与监控,你想知道的都在这里了
2026-05-17栏目: 教程
-
AIoT设备上云最佳实践集锦【持续更新,建议收藏】
2026-05-17栏目: 教程
-
Aliyun Linux 2 CIS benchmark正式发布
2026-05-17栏目: 教程