
ElasticJob各分布式调度服务器有两个角色:主服务器、从服务器。这里主从服务器与数据库的主从同步不一样,也不是传统意义上的主备,从执行调度任务这一视角来看ElasticJob主从服务器的地位是相同的,都是任务调度执行服务器(彼此之间共同组成一个集群平等的执行分配给自己的数据执行调度任务),主从服务器共同构成任务调度的分片节点。ElasticJob的主服务器的职责是根据当前存活的任务调度服务器生成分片信息,然后拉取属于该分片的任务数据执行任务。为了避免分片信息的不统一,ElasticJob必须从所有的调度服务器中选择一台为主服务器,由该台服务器统一计算分片信息,其他服务根据该分片信息进行任务调度。
ElasticJob选主实现由LeaderService实现,从上文可知,在Job调度服务器的启动流程中:
ListenerManager#startAllListeners 方法首先会启动ElectionListenerManager(主节点选举监听管理器),然后调用LeaderService.electLeader方法执行选主过程(SchedulerFacade#registerStartUpInfo)。
1、选主实现LeaderService.electLeader

- String jobName:任务名称。
- ServiceService serverService:作业服务器服务服务API。
- JobNodeStorage jobNodeStorage:job节点存储实现类,操作ZK api。
LeaderService#electLeader
/** * 选举主节点. */public void electLeader() { log.debug("Elect a new leader now."); jobNodeStorage.executeInLeader(LeaderNode.LATCH, new LeaderElectionExecutionCallback()); log.debug("Leader election completed.");}选主使用的分布式锁节点目录: {Namespace}/{JobName}/leader/election/latch,
LeaderService$LeaderElectionExecutionCallback,获取分布式锁后的回调逻辑。
/** * 在主节点执行操作. * * @param latchNode 分布式锁使用的作业节点名称 * @param callback 执行操作的回调 */ public void executeInLeader(final String latchNode, final LeaderExecutionCallback callback) { try (LeaderLatch latch = new LeaderLatch(getClient(), jobNodePath.getFullPath(latchNode))) { latch.start(); // @1 latch.await(); // @2 callback.execute(); //@3 //CHECKSTYLE:OFF } catch (final Exception ex) { //CHECKSTYLE:ON handleException(ex); } }选主直接使用cautor开源框架提供的实现类org.apache.curator. work.recipes.leader.LeaderLatch。
LeaderLatch需要传入两个参数:
Curator work client:curator框架客户端。
- latchPath:锁节点路径,elasticJob的latchPath为:${namespace}/${Jobname}/leader/election/latch。
代码@1、@2:启动 LeaderLatch,其主要过程就是去锁路径下创建一个临时排序节点,如果创建的节点序号最小,await 方法将返回,否则在前一个节点监听该节点事件,并阻塞,如何获得分布式锁后,执行callback回调方法。
LeaderService$LeaderElectionExecutionCallback
@RequiredArgsConstructorclass LeaderElectionExecutionCallback implements LeaderExecutionCallback { @Override public void execute() { if (!hasLeader()) { jobNodeStorage.fillEphemeralJobNode(LeaderNode.INSTANCE, JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId()); } } }成功获取选主的分布式锁后,如果{namespace}/{jobname}/leader/election/instance节点不存在,则创建该临时节点,节点存储的内容为IP地址@-@进程ID,其代码为:jobInstanceId = IpUtils.getIp() + "@-@"+ ManagementFactory.getRuntimeMXBean().getName().split("@")[0];
选主流程如图所示: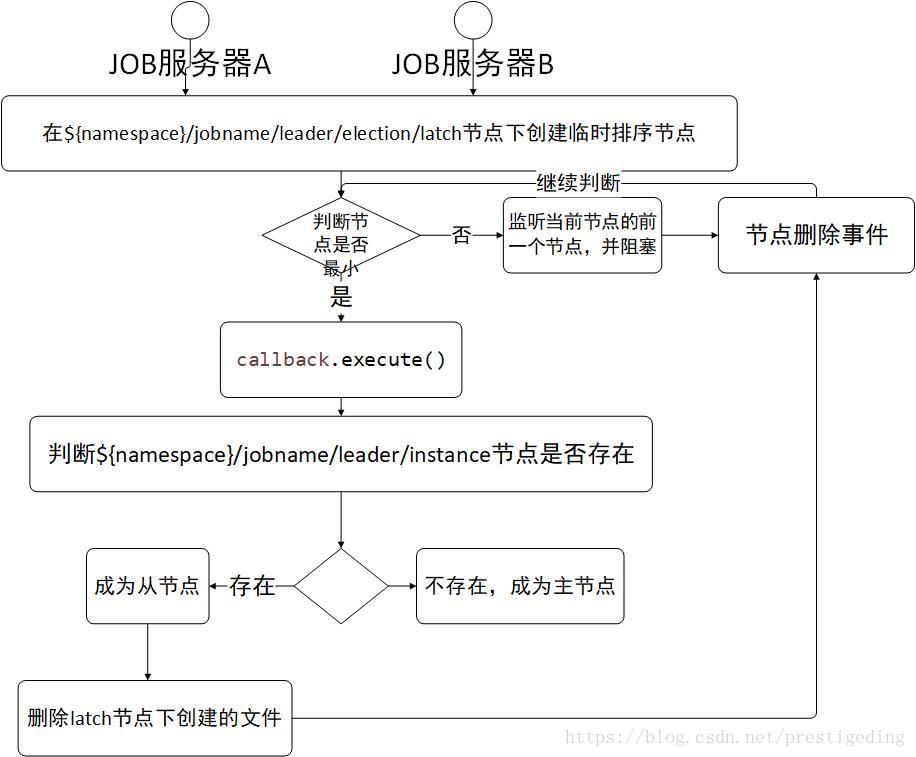
上面完成一次选主过程,如果主服务器宕机怎么办?从节点如何接管主服务器的角色呢?基于ZK的开发模式一般是监听节点的变化事件,做成相应的处理。
2、ElectionListenerManager主节点选举监听管理器

- String jobName:job名称。
- LeaderNode leaderNode:主节点信息,封装主节点在zk中存储节点信息。
- ServerNode serverNode:服务器节点信息。
- LeaderService leaderService:选主服务实现类。
- ServerService serverService:作业服务器服务类。
LeaderNode、ServerNode 代表存储在 zk 服务器上的路径, LeaderNode 的类图如图所示: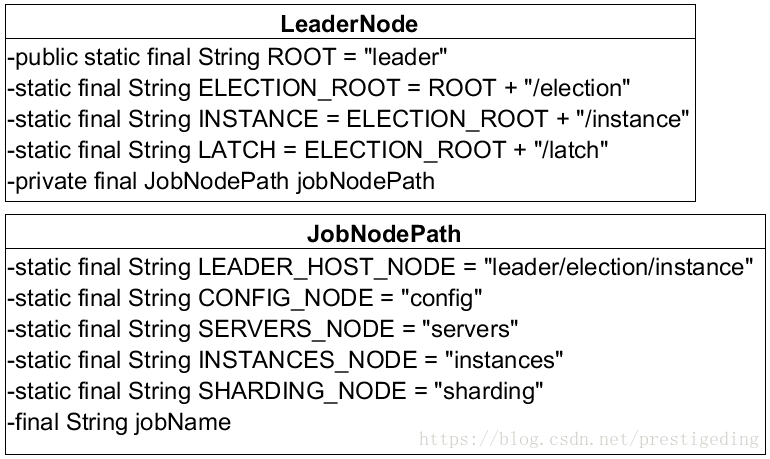
其中 JobNamePath 定义了每一个 Job 在 zk 服务器的存储组织目录,根据器代码显示,例如数据同步项目(MyProject)下定义了两个定时任务(SyncUserJob、SyncRoleJob)。
注册中心命名空间取名为项目名:MyProject,在zk的节点存储节点类似如下目录结构,节点存放内容在具体用到时再分析。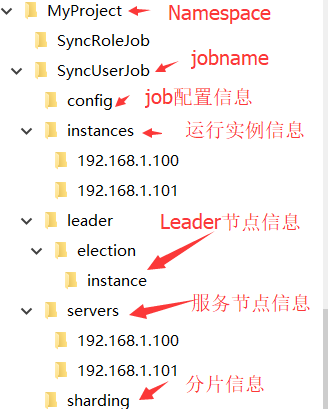
2.1 ElectionListenerManager#start
public void start() {addDataListener(new LeaderElectionJobListener()); addDataListener(new LeaderAbdicationJobListener());}首先关注一下使用ZK如何添加自定义监听器。
JobNodeStorage#addDataListener
/** * 注册数据监听器. * * @param listener 数据监听器 */ public void addDataListener(final TreeCacheListener listener) { TreeCache cache = (TreeCache) regCenter.getRawCache("/" + jobName); cache.getListenable().addListener(listener); }首先获取 TreeCache,然后获取 cahce.getListenable().addListener(TreeCacheListener)。
根据节点路径创建TreeCache的方法如下:
ZookeeperRegistryCenter#addCacheData
public void addCacheData(final String cachePath) { TreeCache cache = new TreeCache(client, cachePath); try { cache.start(); //CHECKSTYLE:OFF } catch (final Exception ex) { //CHECKSTYLE:ON RegExceptionHandler.handleException(ex); } caches.put(cachePath + "/", cache); }2.2 LeaderElectionJobListener
选主事件监听器,监听节点主节点 LeaderNode.INSTANCE{namespace}/{jobname}/leader/election/instance。
如果主节点失去与 zk 的连接,由于 LeaderNode.INSTANCE 为临时节点,当节点被 zk 删除后,会触发其他从节点的选主,但由于任务调度服务器重新建立与zk的连接后,并不能直接参与选主,所以当LeaderNode.INSTANCE 每发送一次变化后,尝试发起一次选主,调用 LeaderService.electLeader 方法。
LeaderElectionJobListener #dataChanged
protected void dataChanged(final String path, final Type eventType, final String data) { if (!JobRegistry.getInstance().isShutdown(jobName) && (isActiveElection(path, data) || isPassiveElection(path, eventType))) { leaderService.electLeader(); } }如果该job未停止,并且可以进行选主或LeaderNode.INSTANCE节点被删除时,触发一次选主。
LeaderElectionJobListener #isActiveElection
private boolean isActiveElection(final String path, final String data) { return !leaderService.hasLeader() && isLocalServerEnabled(path, data);}如果当前节点不是主节点,并且当前服务器运行正常,运行正常的依据是存在{namespace}/{jobname}/servers/server-ip,并且节点内容不为DISABLED。
LeaderElectionJobListener #isPassiveElection
private boolean isPassiveElection(final String path, final Type eventType) { return isLeaderCrashed(path, eventType) && serverService.isAvailableServer(JobRegistry.getInstance().getJobInstance(jobName).getIp());}如果当前事件节点为 LeaderNode.INSTANCE 并且事件类型为删除,并且该 job 的当前对应的实例({namespace}/{jobname}/instances/ip)存在并且状态不为DISABLED。
2.3 LeaderAbdicationJobListener
主退位监听器,其目的就是删除 LeaderNode.INSTANCE 节点。
class LeaderAbdicationJobListener extends AbstractJobListener { @Override protected void dataChanged(final String path, final Type eventType, final String data) { if (leaderService.isLeader() && isLocalServerDisabled(path, data)) { leaderService.removeLeader(); } } private boolean isLocalServerDisabled(final String path, final String data) { return serverNode.isLocalServerPath(path) && ServerStatus.DISABLED.name().equals(data); } }本文选主机制就分析到这里,基于 ZK 来开发的常规讨论,就是创建节点、监听节点事件。这个监听器的目的:如果设置了某个节点的服务为 disable,当前节点正好是leader的话,则这个监听器执行leaderService.removeLeader() ;操作退位。
原文发布时间为:2018-12-01
本文作者:丁威,《RocketMQ技术内幕》作者。
本文来自中间件兴趣圈,了解相关信息可以关注中间件兴趣圈。
继续阅读与本文标签相同的文章
dom4j解析xml文件简单版
-
“小程序,大生态”:云栖大会阿里巴巴小程序生态联盟成立
2026-05-17栏目: 教程
-
阿里云代码管理平台 Teambition Codeup(行云)亮相,为企业代码安全护航
2026-05-17栏目: 教程
-
广发银行×蚂蚁金服mPaaS:打造下一代移动金融中心
2026-05-17栏目: 教程
-
中国人保健康×蚂蚁金服 联手打造保险服务新标杆
2026-05-17栏目: 教程
-
运维编排场景系列---更新镜像后自动更新伸缩配置镜像
2026-05-17栏目: 教程