
大数据处理的挑战
随着企业数据的逐渐积累增多,数据架构从单节点的关系型数据库,演进到分库分表,再演进到NoSQL及hadoop生态。hadoop生态百花齐放,没有统一的架构标准,目前用的比较多的是Lambda架构,该架构主要特点为流计算、批处理、在线存储独立的,通过pipline来连接。
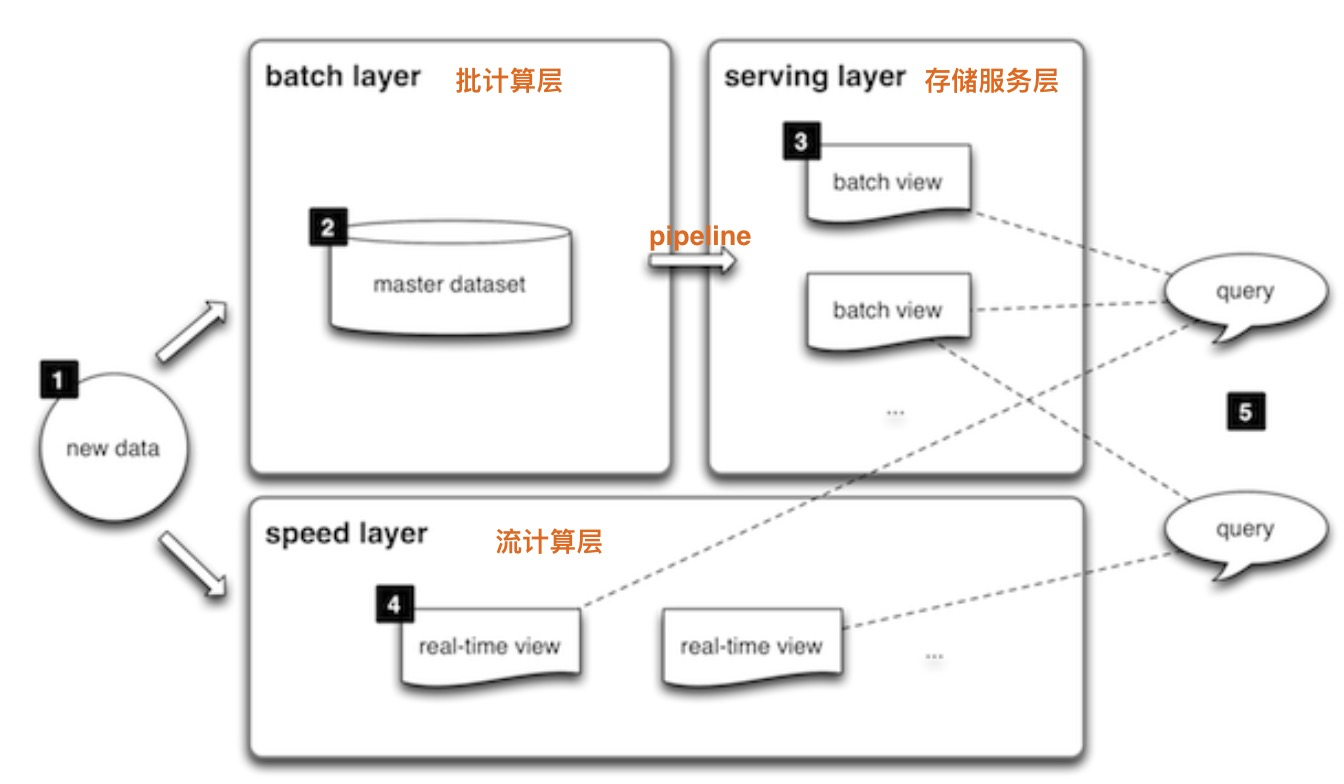
大数据Lambda架构比较复杂,流、批、在线存储需要独立建设,同时需要构建数据pipline来做数据交换流动。
- 数据写入:批处理、流处理、在线存储需要分别写入数据。一方面流及批两层需要独立写入数据,同时很多大数据业务数据也会直接写入mongoDB、Cassandra、H 、Redis等NoSQL系统这样的在线存储系统。
- 数据交换:批处理、在线存储之间交换需要构建大量ETL批作业
- 数据质量:批处理、流处理、在线存储需要分别写入数据,会导致数据维护繁琐,
继续阅读与本文标签相同的文章
-
1元包月,阿里云HBase Serverless开启大数据学习与测试的新时代
2026-05-18栏目: 教程
-
太难了!我耗费心力终于规划出了一张云栖大会日程表
2026-05-18栏目: 教程
-
如何在阿里云容器服务ACK上部署应用管理/发布系统Spinnaker
2026-05-18栏目: 教程
-
公告 | 支付宝小程序相关的审核暂停公告
2026-05-18栏目: 教程
-
深入解析 Kubebuilder:让编写 CRD 变得更简单
2026-05-18栏目: 教程