
本文主要介绍 Apache F 在同程艺龙的应用实践,从当前同程艺龙实时计算平台现状、建设过程、易用性提升、稳定性优化四方面分享了同城艺龙实时计算平台的建设经验,供大家参考。
1.背景介绍
在 2015 年初,为了能够采集到用户在 PC,APP 等平台上的行为轨迹,我们开始开发实时应用。那时可选的技术架构还是比较少的,实时计算框架这块,当时比较主流的有 Storm 和 Spark-streaming。综合考虑实时性,接入难度,我们最终选择使用基于 Storm 构建了第一个版本的用户行为轨迹采集框架。后续随着实时业务的增多,我们发现 Storm 已经远远不能满足我们对数据端到端处理准确一次(Exactly-Once)语义的需求,并且对于流量高峰来临时也不能平滑的背压(BackPressure),在大规模集群的支持上 Storm 也存在问题。经过充分的调研后,我们在 2018 年初选择基于 F 开发同程艺龙新一代实时计算平台。
目前实时计算平台已支撑近千个实时任务运行,服务公司的市场、机票、火车票、酒店、金服、国旅、研发等各个业务条线。下面主要结合实时计算平台来分享下我们在 F 落地过程中的一些实践经验及思考。
2.平台建设
在开发实时计算平台前,我们有过大量实时应用业务的经验,我们发现使用实时计算的业务方主要有两类:
- 一类的大数据业务是基于 Lambda 架构开发的,这部分业务是需要有一个实时计算的组件来帮他们把以前离线的一套数据同步清洗(如:sqoop、hive)转换成实时任务。有时在这个过程中也需要组件来支持实时的过滤聚合。这部分业务方大多是数仓&分析,他们对 SQL 比较熟悉,更倾向于用 SQL 解决一切问题;
另一部分业务方主要是数据开发&挖掘,他们的业务场景更复杂,业务需求变化及应用迭代很频繁,更关注实时应用的性能,他们喜欢用编程语言如:Java,scala 来开发实时应用。
为了更好的为两类用户提供支持,实时计算平台同时支持两种类型的任务:F SQL 和 F Stream。平台整体架构如图所示:

2.1 F SQL
2.1.1 概述
上图的后端 RTC-F SQL 模块即是用来执行提交 F SQL 任务的服务,SQL 属于声明式语言,经过 30、40 年的发展,具有很高的易用性、灵活性和表达性。虽然 F 提供了 Table & SQL API,但是我们当时基于的 F 1.4 及 1.6 版本本身语法也不支持像 Create Table 这样的 DDL 语法,并且在需要关联到外部数据源的时候 F 也没有提供 SQL 相关的实现方式。
此外根据其提供的 API 接口编写 TableSource 和 TableSink 异常繁琐,不仅要了解 F 各种 Operator 的 API,还要对各个组件的相关接入和调用方式有一定了解(比如 Kafka、RocketMQ、Elasticsearch、H 、HDFS 等),因此对于只熟悉 SQL 进行数据分析的人员直接编写 F SQL 任务需要较大的学习成本。
鉴于以上原因,我们构建了实时计算平台的 RTC-F SQL 开发模块并对 F SQL 进行扩展,让这部分用户在使用 F SQL 的时候只需要关心做什么,而不需要关心怎么做。不需要过多的关心程序的实现,而是专注于业务逻辑。
2.1.2 四步实现 F SQL 提交模块
- 构建于 Apache Calcite、Apache F 之上
- 将 SQL 映射成 F JobGraph
※ parser:通过 Calcite api 实现解析,最终得到 SqlNode 集合
※ validator:从 SqlNode 中提取执行的 SQL 和 Source、Sink、维表对应的配置信息
※ executor:利用 validator 获取的信息借助 - F 的 API 得到对应的JobGraph
通过 Yarn Client 提交构建好的 F 任务,提交成功返回 ApplicationID
- 利用 YARN 返回的 ApplicationID 获取 JobId 之后通过 F RESTful API 监控程序的运行状况
2.1.3 在原有 F SQL 的基础上做了很多扩展
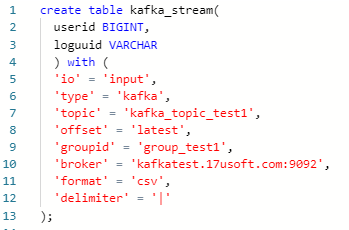
- 支持创建源表语句
这里主要是根据上述 validator 阶段获取的 Source 配置信息,根据指定参数实例化出该对象,然后调用 registerTableSource 方法将 TableSource 注册到 environment,从而完成了源表的注册。
- 支持创建输出表语句
F Table 输出 Operator 基类是 TableSink,我们这里继承的是 AppendStreamTableSink,根据上述 validator 阶段获取的 Sink 配置信息,根据指定参数实例化出该对象,然后调用 registerTableSink 方法将 TableSink 注册到 environment。

- 支持创建自定义函数
继承 ScalarFunction 或者继承 TableFunction,需要从用户提交的 SQL 中获取要使用的自定义函数类名, 之后通过反射获取实例,判断自定义 Function 属于上述哪种类型,然后调用 TableEnvironment.registerFunction 即可完成了 UDF 的注册,最后用户就可以在 SQL中使用自定义的 UDF。

支持维表关联
使用 Calcite 对上述 validator 阶段获取的可执行 SQL 进行解析,将 SQL 解析出一个语法树,通过迭代的方式,搜索到对应的维表,并结合上述 validator 阶段获取的维表信息实例化对应的 SideOperator 对象,之后通过 RichAsyncFunction 算子生成新的 DataStream,最后重新注册表并执行其他 SQL,我们同时支持账号密码直连和公司研发提供的 DAL 方式。

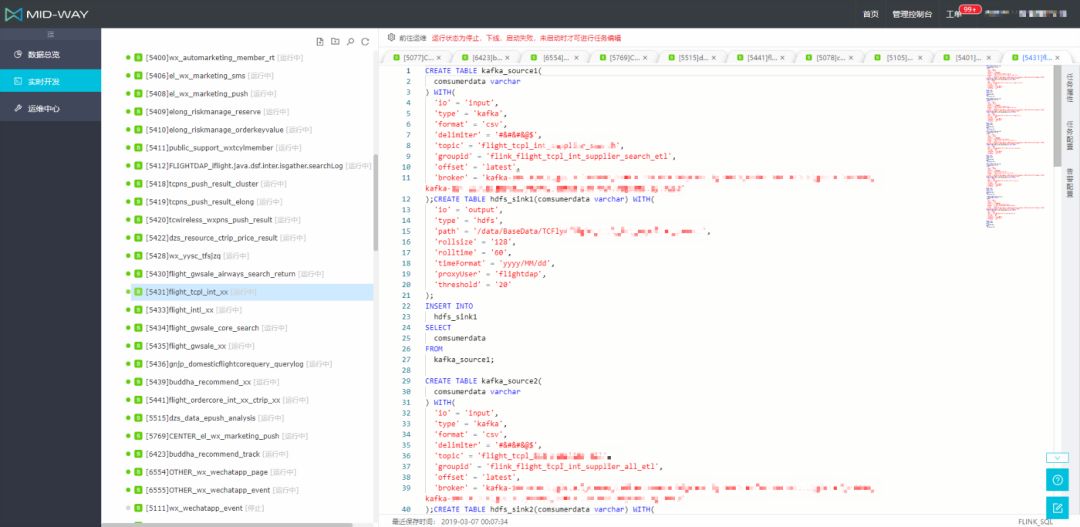
如下图所示,可以方便地在实时计算平台上 F SQL 编辑器内完成 F SQL 任务的开发,目前线上运行有 500+ 的 F SQL 任务在运行。
2.2 F Stream
除了 F SQL 外,平台上还有一半的实时任务是一些业务场景更复杂,通过代码来编写开发的任务。对此我们提供了 RTC-F Stream 模块来让用户上传自己本地打包后的 FAT-JAR,通过资源管理平台来让用户对 JAR 做版本管理控制,方便用户选择运行指定的任务版本,F Stream 任务开发界面如图所示。
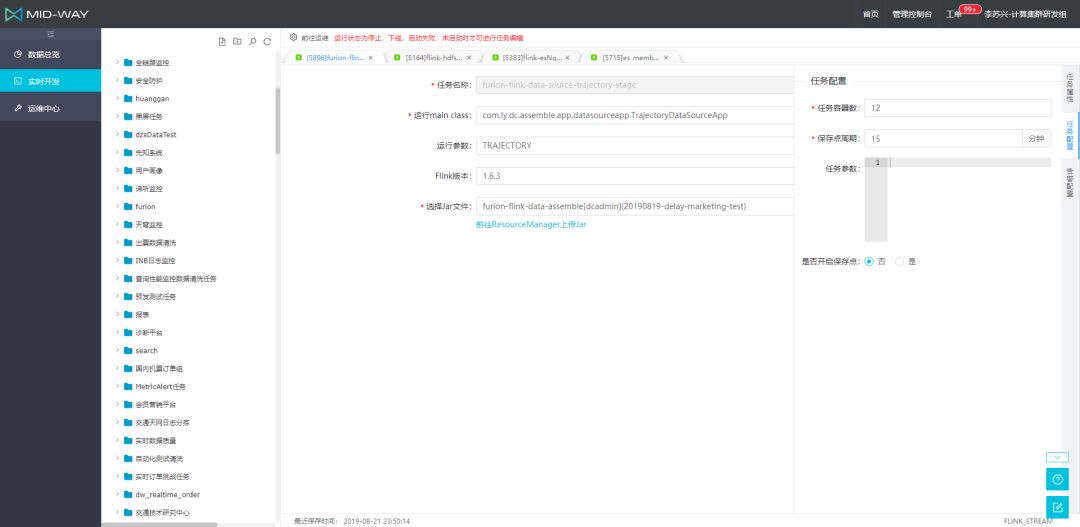
这部分任务有些对资源使用需求比较大,我们提供了任务容器配置的参数来让用户灵活的配置其 Task 并发,并且提供了自定义时间周期触发保存点(savepoint)的功能。
3.易用性提升
平台开发难度相对低,难的是如何提升平台的易用性,因为开源组件如 Apache F 核心关注数据的处理流程,对于易用性这部分稍显不足,所以在实时平台功能开发过程中要修改 F 组件的源码来提升其易用性。
3.1 指标(Metrics)监控
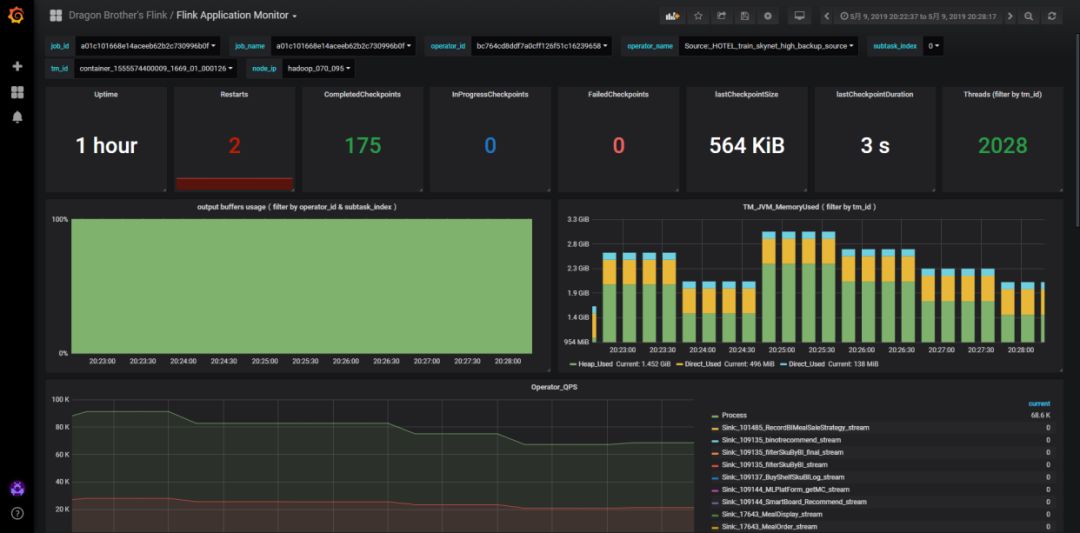
以 F 任务运行的指标(Metrics)监控来说,当 F 程序提交至集群之后,我们需要的是收集任务的实时运行 Metrics 数据,通过这些数据可以实时监控任务的运行状况,例如,算子的 CPU 耗时、JVM 内存、线程数等。这些实时 Metrics 指标对任务的运维、调优等有着至关重要的作用,方便及时发现报警,进行调整。
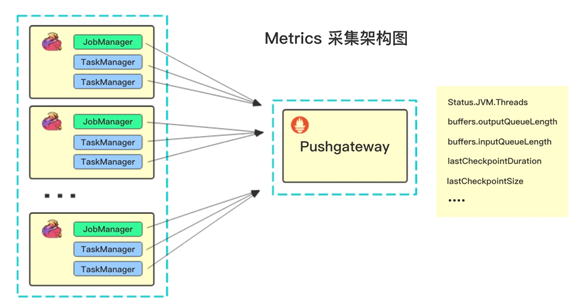
通过对比现有的指标采集系统,包括 InfluxDB、StatsD、Datadog 等系统再结合公司的指标收集系统,我们最终决定采用 Prometheus 作为指标系统。但是在开发过程中我们发现 F 只支持 Prometheus 的拉模式收集数据,此模式需要提前知道集群的运行主机以及端口等信息,适合于单集群模式。
而作为企业用户,更多的是将 F 任务部署在 YARN 等集群上,此时,F 的 JobManager、TaskManager 的运行是由 YARN 统一调度,主机以及是端口都是动态的,而 F 只支持的拉模式难以满足我们需求。所以我们通过增加 Prometheus 的 Pushgateway 来进行指标的收集,此模式属于推模式,架构如图所示。同时,我们也积极的向社区贡献了这个新特性[4] ,目前 PR 已经被合并,详情见 F -9187。
3.2 配置监控页面
在完成 F Pushgateway 的相关工作后,为了方便用户查看自己 F 任务的吞吐量,处理延迟等重要监控信息,我们为用户配置了监控页面,方便用户在实时计算平台上快速定位出任务性能问题,如通过我们实时平台监控页面提供的图表,具体指标为 f _taskmanager_job_task_buffers_outPoolUsage 来快速判断实时任务的 Operator 是否存在反压情况[2]。
在使用过程中我们也发现了 F Metrics 中衡量端到端的 Opertor Latency 的指标存在漂移,导致监控不准确问题。我们也修复了该问题[5]并反馈给了社区,详情见F -11887。
3.3 日志
提升平台易用性还有一个重要的地方就是日志,日志分为操作日志,启动日志,业务日志,运行历史等日志信息。其中比较难处理的就是用户代码中打印的业务日志。因为 F 任务是分布式执行的,不同的 TaskManager 的处理节点都会有一份日志,业务看日志要分别打开多个 TaskManager 的日志页面。
并且F 任务是属于长运行的任务,用户代码中打印的日志是打印在 F WebUI 上。此时会面临一个问题,当任务运行的时间越长,日志量会越来越多,原生自带的日志页面将无法打开。为了方便用户查看日志,解决用户无法获取到实时任务的日志信息,同时也为了方便用户根据关键词进行历史日志的检索,我们在实时计算平台为用户提供了一套实时日志系统功能,开发人员可以实时地搜索任务的日志。
并且系统采用无侵入式架构,架构图见下图,在用户程序无感知的情况下,实时采集日志,并同步到 Elasticsearch 中,当业务需要检索日志时,可通过 Elasticsearch 语法进行检索。

3.4 计算组件
计算组件往往处于大数据的中间位置,上游承接 MQ 等实时数据源,下游对接 HDFS、H 等大数据存储,通过 F 这些实时组件将数据源和数据目标串联在一起。为了避免混乱,这个过程往往需要通过数据血缘来做管理。然而常见的数据血缘管理的开源项目如 Apache Atlas 等并未提供对 F 的支持,而 F 自身也没有提供相应的 Hook 来抽取用户代码的中的数据源等信息。
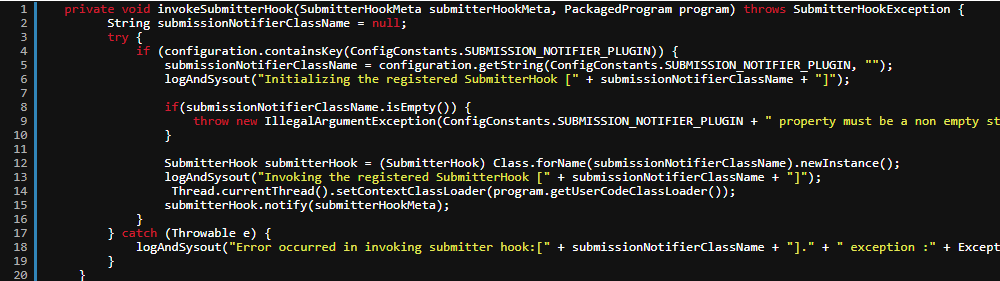
为了解决这个问题,我们修改了 F Client 提交过程,在 CliFrontend 中增加一个 notify 环节,通过 ContextClassLoader 和反射在 F 任务提交阶段将 F 生成的 StreamGraph 内的各个 StreamNode 抽取出来,这样就可以在提交时候获取出用户编写的 F 任务代码中关键数据源等配置信息,从而为后续的 F 数据血缘管理提供支持。其关键代码如下:
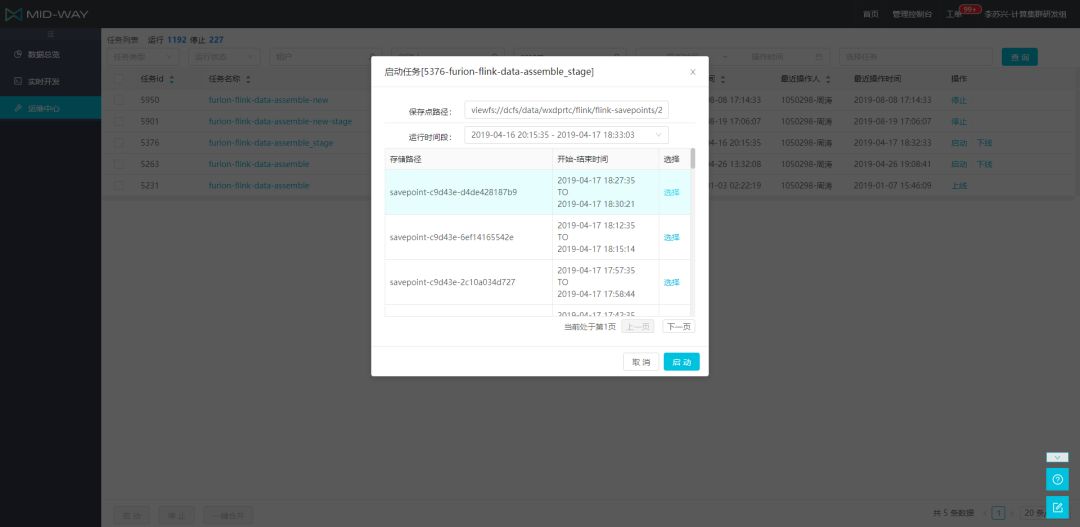
F 采用了 Chandy-Lamport 的快照算法来保证一致性和容错性,在实时任务的运行期间是通过 Checkpoint [1]机制来保障的。如果升级程序,重启程序,任务的运行周期结束,window 内的状态或使用 mapstate 的带状态算子(Operator)所保存的数据就会丢失了,为了解决这个问题,给用户提供平滑升级程序方案从而保障数据准确处理,我们实时计算平台提供了从外部触发 Savepoint 功能,在用户手动重启任务的时候,可以选择最近一段时间内执行成功的保存点来恢复自己的程序。平台从保存点恢复任务操作如图所示。
虽然我们提供了通用的实时计算平台,但是有些用户想使用 F ,除此之外还需要在平台上增加些更符合其业务特点的功能,对此我们也开放了我们实时计算平台的 API 接口给到业务方,让业务根据其自身场景特点来加速实时应用的变现和落地。
4.稳定性优化
前面介绍了我们在实时计算平台易用性方面如:SQL,监控,日志,血缘,保存点等功能点上做的开发工作,其实除了平台功能开发之外还有更多的工作内容是用户没有感知到的。如保障实时应用运行稳定性,在这方面我们积累了很多实践经验,与此同时我们也在 Github 上建立了 Tongcheng-Elong 组织,并将修复后的源代码贡献到 Apache 社区。其中有十几个 patch 已经被社区接收合并。接下来分享一些我们遇到的稳定性问题和提供的解决方案。
4.1 F 的“ 空跑”问题
我们在集群运维过程中发现,在偶发的情况下,F 任务会在 YARN 集群上空跑。此时,在 YARN 层面的现象是任务处于 RUNNING 状态,但是进入到 F WebUI,会发现此时所有的 TaskManager 全部退出,并没有任务在运行。这个情况下,会造成的 YARN 资源的浪费,同时也给运维人员带来困扰,为什么 TaskManager 都退出了,JobManager 不退出呢?甚至给平台监控任务运行状态带来误判,认为任务还在运行,但实际任务早挂了。
这个问题比较难定位,首先发生这种情况不多,但是一旦出现影响很大。其次,没有异常堆栈信息,无法定位到具体的根本原因。我们的解决方法是通过修改源码,在多个可能的地方增加日志埋点,以观察并了解任务退出时 JobManager 所执行的处理逻辑。最终我们定位到当任务失败时,在默认的重试策略之后,会将信息归档到 HDFS 上。由于是串行执行,所以如果在归档过程中发生异常,则会中断正常处理逻辑从而导致通知 JobManager 的过程不能成功执行。具体的执行逻辑见下图。
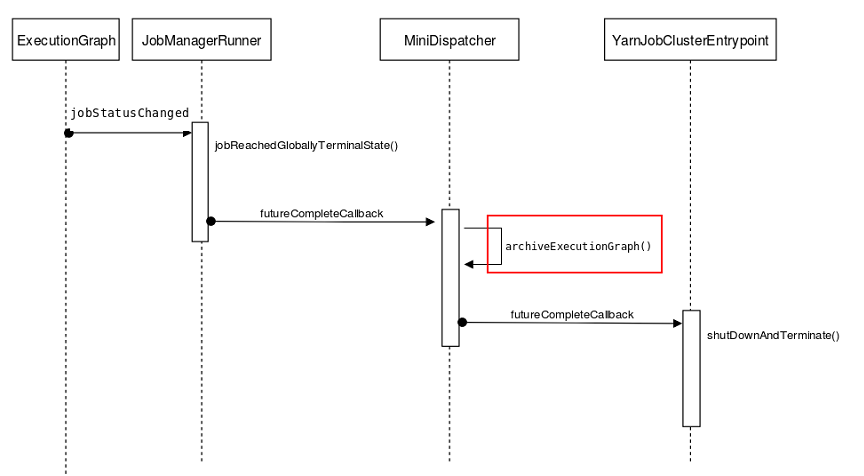
梳理清楚逻辑之后,我们发现社区也没有修复这个问题。同样,我们也积极向社区进行提交PR修复6[8]。修复这个问题,需要通过 3 个 PR,逐步进行完善,详情见 F -12246、F -12219、F -12247。
我们的存储组件比较多,在使用 F -Connector 来读写相关存储组件的如:RocketMQ、HDFS、Kudu、Elasticsearch 也发现过这些 Connector 的 Source/Sink 存在问题,我们在修复之后也提交了 PR 反馈到社区:
- RocketMQSource 的 connector 从 savepoint 恢复异常问题,及 RocketMQSource 不能严格保证数据不丢失问题。我们修复这些问题后为业务用户提供基于我们自己版本稳定的 connector SDK;
- BucketingSink 写入 HDFS 时出现的 client 无限续租导致的文件卡在 openforwrite 状态问题[3],我们也维护了自己的 filesystem connector SDK 提供给业务用户,在异常发生时主动释放租约;
- 对 F 写 Kudu 时提供的 KuduSink 性能过低问题,我们也提出通过异步刷新模式来提高 Sink 的写入性能[9];
- F - Elasticsearch6-connector 写入线程死锁问题。ES 是实时分析这边重要的存储组件,而在我们实际的实践过程中会发现本来运行正常的 F 程序会偶尔出现程序 hang 住,所有的数据处理都停止,消费 MQ 数据速度降为 0,除非重启任务否则无法恢复。这个问题一旦出现,严重影响线上实时应用的稳定性。F 和 ElasticSearch 社区也有多个 issue 讨论类似的问题。在经过分析后,我们发现问题主要原因是 Elasticsearch 6 的 core 模块在线程池重构后 Bulk Interval FlushTask 和 RetryHandler 共用相同线程池导致的,具体的执行逻辑见图。
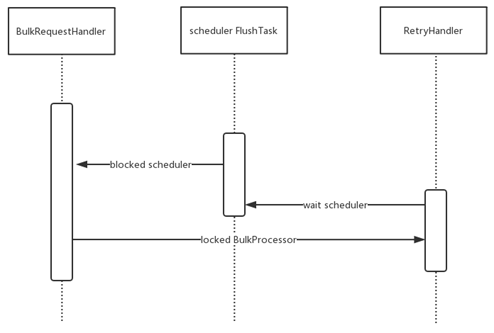
对于该问题的临时解决方案是在使用 Elasticsearch 6.x 的 RestHighLevelClient 的时候暂时停止使用 setBulkFlushInterval 配置, 而是通过 F 自身的 checkpoint 机制来触发数据定时 Flush 到 ElasticSearch Server 端。真正彻底解决办法是构建单独的线程池提供给 ReryHandler 来使用。随后我们也向 Elasticsearch 社区提交了 issue 及 PR 来修复这个问题 [10]。在这个过程中发现也顺便修复了 F 在任务重试时候 transport client 线程泄露[11]等问题详情见 F -11235。
4.2 F 与 ZK 网络问题
我们也遇到了 F 与 ZK 网络问题,当 Jobmanager 与 ZK 的连接中断之后,会将正在运行的任务立即停止。当集群中任务很多时,可能由于网络抖动等原因瞬断时,会导致任务的重启。而在我们集群上有上千的 F 应用,一旦出现网络抖动,会使得大量 F 任务重启,这个问题对集群和任务的稳定性影响比较大。
根本原因是 F 底层采用 Curator 的 LeaderLatch 做分布式锁服务,在 Curator-2.x 的版本中对于网络瞬断没有容忍性,当因为网络抖动、机器繁忙、zk集群短暂无响应都会导致 curator 将状态置为 suspended,正是这个 suspended 状态导致了所有任务的重启。
我们的解决办法是先升级 Curator 版本到 4.x[12],然后在提升版本后再用 Curator workFactory 来构造 Curator work 时,通过使用 ConnectionStateErrorPolicy 将 StandardConnectionStateErrorPolicy 替换为 SessionConnectionStateErrorPolicy,前者将 suspended 和 lost 都作为 error,后者只是将 lost 作为 error,而只有发生 error 的时候才会取消 leadership,所以在经过修改之后,在进入 suspended 状态时,不再发生 leadership 的取消和重新选举。我们把这个问题和我们的解决办法也反馈给了社区,详情见 F -10052。
5.总结
本文大致介绍了 F 在同程艺龙实时计算平台实践过程中的一些工作和踩过的坑。对于大数据基础设施来说平台是基础,除此之外还需要投入很多精力来提高 F 集群的易用性和稳定性,这个过程中要紧跟开源社区,因为随着同程艺龙在大数据这块应用场景越来越多,会遇到很多其它公司没有遇到甚至没有发现的问题,这个时候基础设施团队要有能力主动解决这些影响稳定性的风险点,而不是被动的等待社区来提供 patch。
由于在 F 在 1.8 版本之前社区方向主要集中在 F Stream 处理这块,我们也主要应用 F 的流计算来替换 storm 及 spark streaming。但是随着近期 F 1.9 的发布, 分支合并进入 F 主分支,我们也打算在 F Batch 这块尝试一些应用来落地。
作者:同城艺龙数据中心 F 小分队(谢磊、周生乾、李苏兴)
Reference:
[1]https://www.ververica.com/blog/differences-between-savepoints-and-checkpoints-in-f
[2]https://www.cnblogs.com/AloneAli/p/10840803.html
[3]https://www.cnblogs.com/AloneAli/p/10840956.html
[4]https://issues.apache.org/jira/browse/F -9187
[5]https://issues.apache.org/jira/browse/F -11887
[6]https://issues.apache.org/jira/browse/F -12246
[7]https://issues.apache.org/jira/browse/F -12219
[8]https://issues.apache.org/jira/browse/F -12247
[9]https://issues.apache.org/jira/browse/BAHIR-202
[10]https://github.com/elastic/elasticsearch/issues/44556
[11]https://issues.apache.org/jira/browse/F -11235
[12]https://issues.apache.org/jira/browse/F -10052
▼ Apache F 社区推荐 ▼
Apache F 及大数据领域顶级盛会 F Forward Asia 2019 重磅开启,目前正在征集议题,限量早鸟票优惠ing。了解 F Forward Asia 2019 的更多信息,请查看:
https://developer.aliyun.com/special/ffa2019
首届 Apache F 极客挑战赛重磅开启,聚焦机器学习与性能优化两大热门领域,40万奖金等你拿,加入挑战请点击:
继续阅读与本文标签相同的文章
-
“2019密码应用高峰论坛”,探讨国密证书全生态应用
2026-05-18栏目: 教程
-
阿里云ECS突发性能t6实例1年仅需148元 上车拼团即享1.5折优惠!
2026-05-18栏目: 教程
-
Linux初级知识
2026-05-18栏目: 教程
-
短视频开发、小视频源码制作需要这些技术手段
2026-05-18栏目: 教程
-
企业官网怎么选择合适的阿里云服务器ECS配置及价格(新手参考)
2026-05-18栏目: 教程