
一.Dremio架构
Dremio是基于Apache calcite、Apache arrow和Apache parquet3个开源框架构建,结构其核心引擎Sabot,形成这款DaaS(Data-as-a-Service)数据即服务平台;整体体验风格与其公司开源的Apache Drill非常接近。
Ⅰ).架构图
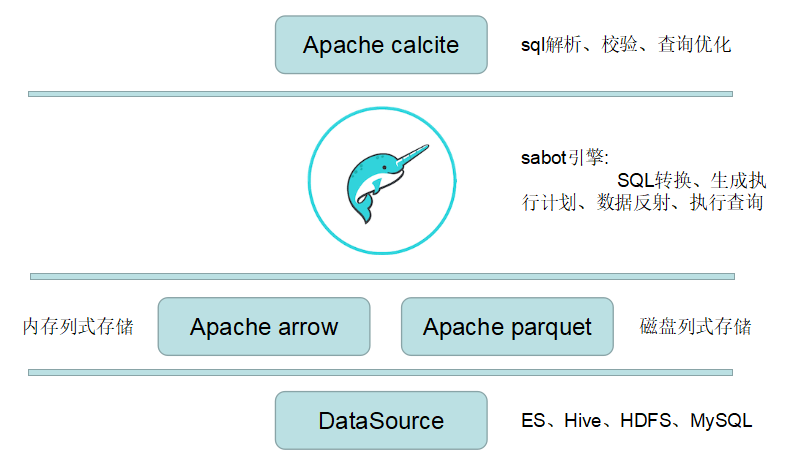

Ⅱ).参考API

Ⅲ).参考SQL

二.Apache Arrow
Apache Arrow是基于Apache Drill中的Value Vector来实现的,而使用Value Vector可以减少运算时重复访问数据带来的成本,其特点:
- 零拷贝共享内存和基于RPC的数据移动
- 读写文件格式(如CSV,Apache ORC和Apache Parquet)
- 内存分析和查询处理
Ⅰ).公共数据层
Apache Arrow的功能设计思路有点类似于适配器模式,将不同系统的数据源进行统一适配。
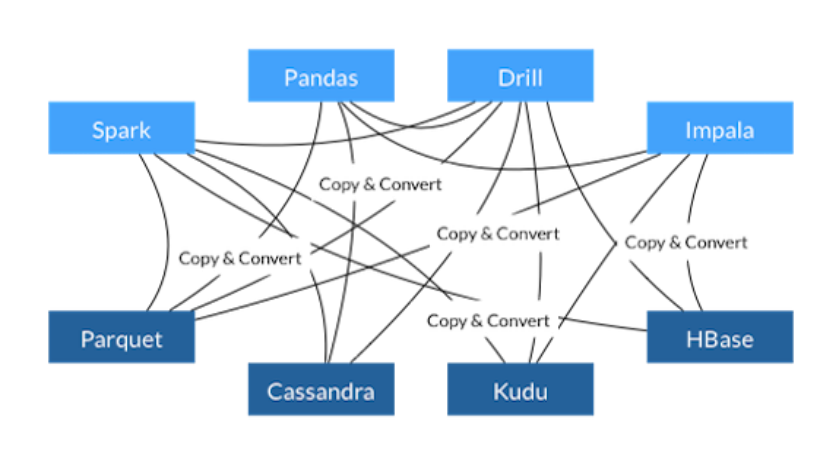
a).不使用Arrow
- 每个系统都有自己的内部存储器格式
- 在序列化和反序列化上浪费了70-80%的计算量
- 在多个项目中实现的类似功能
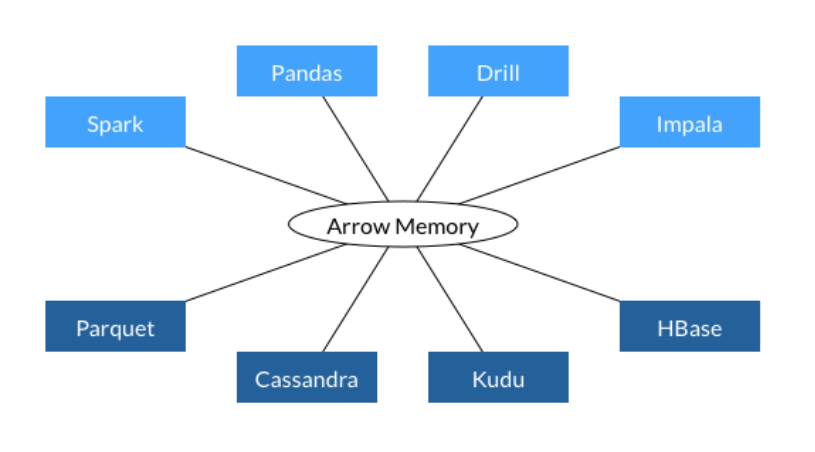
b).使用Arrow
- 所有系统都使用相同的内存格式
- 没有跨系统通信的开销
- 项目可以共享功能
Ⅱ).列式存储
传统的内存数据格式是以每一行作为各个字段的分布,相同字段没有被集中在一起,造成了计算时的不必要浪费;Apache Arrow通过列式存储格式约束,将相同字段集中排列在一起,提高了过滤查询的响应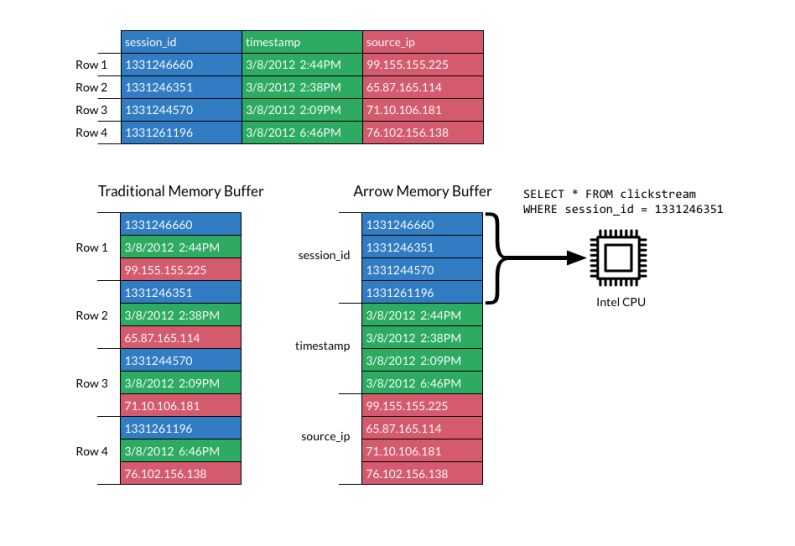
如下例子:
a).数据
people=[ { "name": "mary", "age": 30, "placed_lived": [ { "city": "Akron", "state": "OH" }, { "city": "Bath", "state": "OH" } ] }, { "name": "mary", "age": 31, "placed_lived": [ { "city": "Lodi", "state": "OH" }, { "city": "Ada", "state": "OH" }, { "city": "Akron", "state": "OH" } ] }]b).存储结构
placed_lived offsets: 存储的起始位置是0,其中第一个人有2个city,所以为0~2;第二个人有3个city,所以为3~5
city offsets: 存储的起始位置是0,其中第一个人的第一个city是Akron,所以为0~5,以此类推,即可知offsets位置
city Data: 即为实际数据存储位置

三.Apache Parquet
Apache Parquet是一种面向分析的、通用的列式存储格式,兼容各种数据处理框架比如 Spark、Hive、Impala 等,同时支持 Avro、Thrift、Protocol Buffers 等数据模型。
Ⅰ).Parquet主要模块
- parquet-format:定义了所有格式规范,以及由 Thrift 序列化的元数据信息
- parquet-mr:实现读写 Parquet 文件的功能模块,与其他组件的适配工具,如Hadoop Input/Output Formats、Pig loaders 、Hive Serde 等
- parquet-cpp:用于读写Parquet文件的C ++库
- parquet-rs:用于读写Parquet文件的Rust 库
- parquet-compatibility:验证不同语言之间读写 Parquet 文件的兼容性测试
Ⅱ).数据存储格式
Parquet文件结构
- File:一个 Parquet 文件,包括数据和元数据
- Row group:数据在水平方向上按行拆分为的单元
- Column:一个行组中的每一列对应的保存在一个列块中
- Page:每一个列块划分为多个数据页,同一个列块的不同页可能使用不同的编码格式
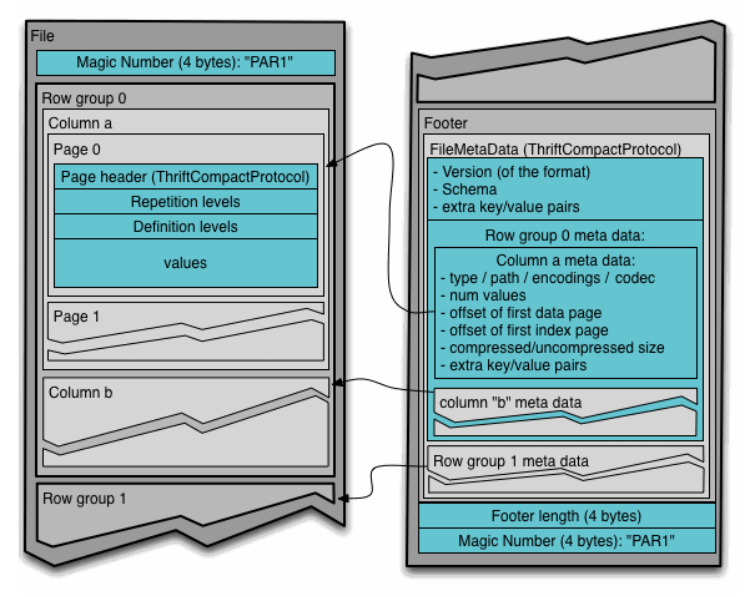
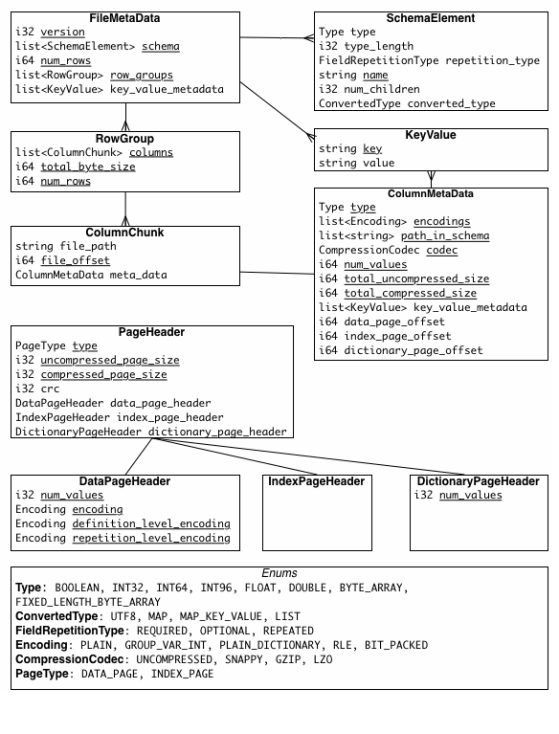
Ⅲ).元数据
元数据包括如下3部分
- file data
- column (chunk) data
- page header data
四.Apache Calcite
Apache Calcite 是一款开源SQL解析工具, 可以将各种SQL语句解析成抽象语法术AST(Abstract Syntax Tree), 之后通过操作AST就可以把SQL中所要表达的算法与关系体现在具体代码之中
Ⅰ).Calcite 主要组件
- Catelog: *定义SQL语义相关的元数据与命名空间
- SQL parser: 主要是把SQL转化成AST
- SQL validator: 通过Catalog来校证AST
- Query optimizer: 将AST转化成物理执行计划、优化物理执行计划
- SQL generator: 反向将物理执行计划转化成SQL语句
Ⅱ).Calcite 主要功能
- SQL 解析
- SQL 校验
- 查询优化
- SQL 生成器
- 数据连接
五.Apache Drill
Apache Drill是用于大规模数据集的低延迟分布式SQL查询引擎,包括结构化和半结构化/嵌套数据
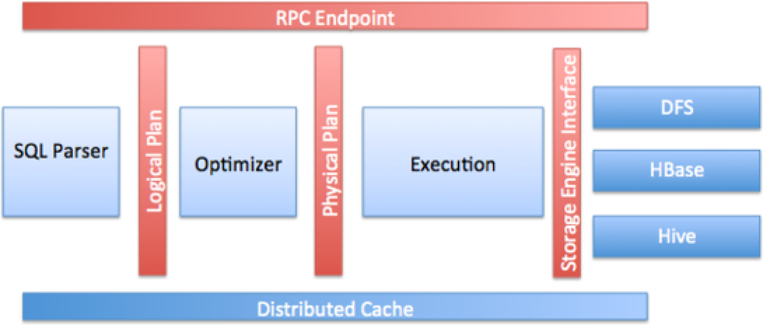
Ⅰ).Drill核心模块
- RPC端点: Drill公开了一个低开销的基于protobuf的RPC协议,以与客户端进行通信
- SQL解析器: Drill使用开源SQL解析器框架Calcite来解析传入的查询
- 存储插件界面: Drill充当多个数据源之上的查询层,存储插件为Drill提供以下信息
- a).数据源的的元数据
- b).Drill用于读取和写入数据源的接口
- c).数据的位置和一组优化规则,以帮助在特定数据源上高效,快速地执行Drill查询
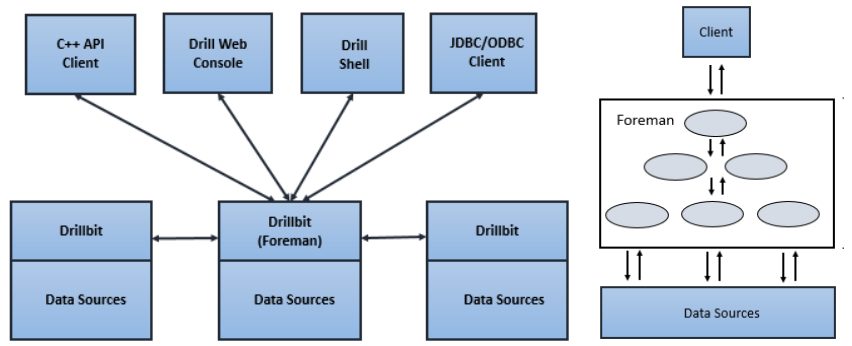
Ⅱ).Drill查询
- 客户端或应用程序会以SQL语句的形式将查询发送到Drill集群中的Drillbit,Drill无主从概念
- 接受查询的Drill节点成为Foreman,Foreman驱动整个查询
- Foreman解析器解析SQL,并根据SQL运算符形成逻辑计划
- Foreman优化器使用各种类型的规则把操作符和函数重新排列为最佳计划后,将逻辑计划转换为执行查询的物理计划
- Foreman中的并行化程序将物理计划转换为多个片段,片段创建了一个多级执行树
- 查询根据执行树在数据源并行执行,并将结果发送回客户端或应用程序
Ⅲ).Drill特点
- 低延迟SQL查询
- 动态查询文件(如JSON,Parquet,AVRO和NoSQL)和H 表中的自描述数据,无需Hive store中的元数据定义
- 嵌套数据支持
- 与Apache Hive集成(对Hive表和视图的查询,对所有Hive文件格式和Hive UDF的支持)
- 使用标准JDBC / ODBC驱动程序进行BI / SQL工具集成
六.使用案例
a).hive数据分析
b).hdfs数据分析
c).本地Json文件数据分析
d).Elasticserch数据分析
继续阅读与本文标签相同的文章
初探云原生应用管理之:聊聊 Tekton 项目
推荐一个单元测试库
-
阿里云CDN上线 WAF,一站式提供分发+安全能力
2026-05-20栏目: 教程
-
阿里云服务器优惠购买攻略:代金券+9折优惠码+云上爆款特惠活动
2026-05-20栏目: 教程
-
Java面试之Jvm内存泄漏
2026-05-20栏目: 教程
-
算法题之动态规划-01背包问题
2026-05-20栏目: 教程
-
《软件自动化测试开发》| 每日读本书
2026-05-20栏目: 教程