
近几篇文章聊CAS被骂得较多,今天还是聊CAS,谈谈CAS在一种“分布式ID生成方案”上的应用。
所谓“分布式ID生成方案”,是指在分布式环境下,生成全局唯一ID的方法。
可以利用DB自增键(auto inc id)来生成全局唯一ID,插入一条记录,生成一个ID:
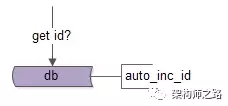
这个方案利用了数据库的单点特性,其优点为:
无需写额外代码
全局唯一
绝对递增
递增ID的步长确定
其不足为:
需要做数据库HA,保证生成ID的高可用
数据库中记录数较多
生成ID的性能,取决于数据库插入性能
优化方案为:
利用双主保证高可用
定期删除数据
增加一层服务,采用批量生成的方式降低数据库的写压力,提升整体性能
增加服务后,DB中只需保存当前最大的ID即可,在服务启动初始化的过程中,首先拉取当前的max-id:
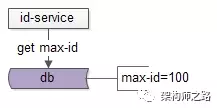
select max_id from T;
然后批量获取一批ID,放到id-serv
继续阅读与本文标签相同的文章
上一篇 :
mysql并行复制降低主从同步延时的思路与启示
下一篇 :
CAS下ABA问题及优化方案 | 架构师之路
-
C++这么难,为什么还要学习C++呢?如何学?
2026-05-20栏目: 教程
-
1对多业务,数据库水平切分架构一次搞定 | 架构师之路
2026-05-20栏目: 教程
-
工作线程数究竟要设置为多少 | 架构师之路
2026-05-20栏目: 教程
-
MySQL冗余数据的三种方案 | 架构师之路
2026-05-20栏目: 教程
-
Unity工程无代码化
2026-05-20栏目: 教程