
I/O 是最为基础重要的一门工程,它是数据信息交换的渠道方式。在爆炸性海量数据的互联网时代,I/O问题尤其重要,往往影响我们系统的性能祸首之一。
常常有网络I/O网络数据上传与下载能力, 磁盘I/O即是我们硬盘的读写能力。
而I/O类主要在JDK包java.io下,类比较繁多,我们只需要挑一两个来study。根据数据流的格式和方式如下分类:
1)基于字节(抽象类):InputStream 和 OutputStream
2)基于字符(抽象类):Writer 和 Reader
3)基于磁盘文件(类):File
4)基于网络传输(类):Socket
基于字节的I/O操作
InputStream类的相关层级关系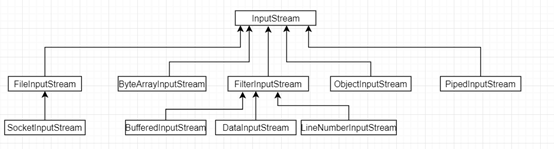
代码1
private static void inputStreamForFile(File file) throws IOException { InputStream fis = null; try { fis = new FileInputStream(file);/* int result; while ((result = fis.read()) != -1) { System.out.print((char)result); }*/ byte[] buffer = new byte[(fis.available())]; // 缓存大小跟文件字节数一致 fis.read(buffer); System.out.println(new String(buffer)); } finally { fis.close(); } }与InputStream输入字节流相对应的是OutputStream输出字节流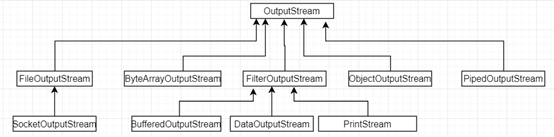
代码2
public static void outputStreamToFile(File file) { String bufferStr = new String("
hello from outStream!"); byte buffer[] = bufferStr.getBytes(); OutputStream out = null; try { // 以追加的方式写入文件 out = new FileOutputStream(file, true); out.write(buffer); } catch (Exception ex) { ex.printStackTrace(); } finally { try { out.close(); } catch (IOException ioEx) { System.out.println(ioEx.toString()); } }}其中,FileOutputStream(File file, boolean append)
以追加的方式,添加入文件的末尾。
通过类层次可以知道,FileOutputStream 的子类有SocketOutputStream, 即网络输出字节流其实也是以文件流形式进行传输。
基于字符的I/O操作
最小的存储单元是字节而不是字符,所以I/O操作都是针对字节进行存储。那为啥需要引入字符呢?那是因为在我们的程序中,通常操作的数据都是以字符形式,为了操作方便需要提供一个直接写字符的 I/O 接口。
Reader 字符流,它的类层次结构如下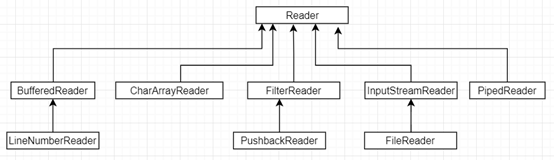
代码3
private static void readForFile(File file) throws IOException { StringBuffer sb; FileReader fileReader = null; try { sb = new StringBuffer(); char[] buf = new char[1024]; fileReader = new FileReader(file); while (fileReader.read(buf) > 0) { sb.append(buf); } } finally { fileReader.close(); } System.out.println("readForFile, " + sb.toString());}Writer的类层次结构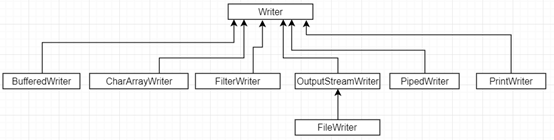
代码4
private static void writeForFile(File file) throws IOException { FileWriter fw = null; try { fw = new FileWriter(file, true); fw.write("this is from write"); } finally { fw.close(); }}刚才说了,底层是以最小单元为字节进行存储,而程序中经常以字符来进行操作,所以存在字节与字符的转化,拿InputStream 输入字节流举例,类结构如下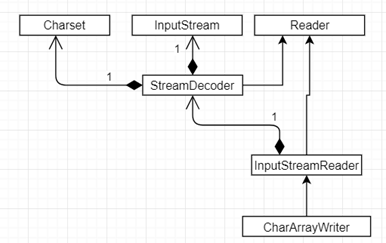
如果转换时,没有指定编码,会以默认的字符编码进行转义,默认的是“UTF-8”
public static Charset defaultCharset() { if (defaultCharset == null) { synchronized (Charset.class) { String csn = AccessController.doPrivileged( new GetPropertyAction("file.encoding")); Charset cs = lookup(csn); if (cs != null) defaultCharset = cs; else defaultCharset = forName("UTF-8"); } } return defaultCharset;}java 访问磁盘文件
在 java 中通常的 File 并不代表一个真实存在的文件对象,当你指定一个路径描述符时,他就会返回代表这个路径的虚拟对象,它可能是一个真实存在的文件或者一个包含多个文件的文件夹。多数情况下,我们并不关心这是文件是否存在,只关心这个文件到底如何操作。那么什么时候会检查这个文件是否真实存在呢?
只有在真正需要读取文件的时候,才会去检查这个文件是否存在
前文已经提到,文件存盘的最小单位是字节,所以直接和硬盘打交道的是字节流,针对于输入文件字节流FileInputStream,在它实例化时会创建一个 FileDescritor 对象,其实FileDescritor就是代表一个存在的文件对象的描述。当我们在操作一个FileInputStream文件对象时,可以通过其 getFD() 方法来获取FileDe or对象。而FileDe or是与底层操作系统相关联文件的行为描述。
具体的行为包括如下:
/** * Force all system buffers to synchronize with the underlying * device. This method returns after all modified data and * attributes of this FileDe or have been written to the * relevant device(s)…**/FileDe or.sync() 方法将操作系统缓存中的数据强制刷新到物理磁盘中。/** * Tests if this file de or is valid. */FileDe or.valid() 方法将检测描述对象是否有效。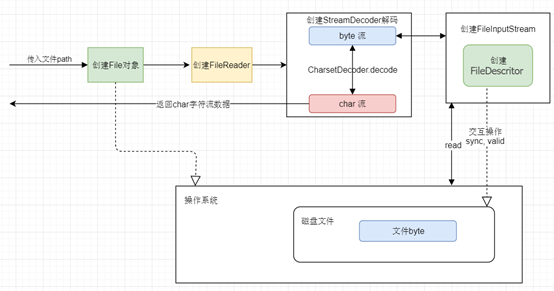
当传入一个文件路径时,将会根据这个路径创建一个 File 对象,然后创建StreamDecoder进行编码解码,最后将会真正创建一个关联真实存在的磁盘文件的文件描述符 FileDe or,这个对象可以用来操作磁盘文件。
继续阅读与本文标签相同的文章
网易云音乐的消息队列改造之路
40G数据中心交换机如何选择合适的光模块?
-
HashMap 源码解析(二)
2026-05-23栏目: 教程
-
一个25岁女生做运营以后的发展,做运营死路一条!
2026-05-23栏目: 教程
-
MongoDB-SQL优化
2026-05-23栏目: 教程
-
QSFP28 LR4单模光模块与其它100G光模块有什么区别
2026-05-23栏目: 教程
-
阿里云王广芳:5G时代,我们需要怎样的边缘计算?
2026-05-23栏目: 教程