
Nebula Graph:一个开源的分布式图数据库。作为唯一能够存储万亿个带属性的节点和边的在线图数据库,Nebula Graph 不仅能够在高并发场景下满足毫秒级的低时延查询要求,还能够实现服务高可用且保障数据安全性。
本篇导读
H Con Asia2019 活动于 2019 年 7 月 20 日于北京金隅喜来登酒店举办,应主办方邀请,Nebula Graph 技术总监-陈恒在活动中发表演讲 “Nebula: A Graph DB d on H ” 。本篇文章是根据此次演讲所整理出的技术干货,全文阅读需要 30 分钟。
大家下午好,我是陈恒,来自 VESoft,是开源图数据库 Nebula Graph 的开发者。同时,我也是 H 的 Commiter(刚才在后面和各位大佬谈笑风生),今天和大家分享的,是我们最近刚开源的分布式图数据库 Nebula Graph。
Nebula Graph 简要介绍
首先,介绍一下我们公司:欧若数网科技有限公司(英文名:VESoft),是 2018 年 10 月份成立的。我们的核心产品是分布式图数据库 Nebula Graph,这个项目从开始到现在,大概做了半年多时间。目前已经 release alpha 版本,还有可以试用的 docker,正式的 release 预计会在 10 月份。
NebulaGraph 是完全开源的,可以在 GitHub 上访问 github.com/vesoft-inc/Nebula Graph

NoSQL 类数据库的发展趋势
下面我们看一张图,是 DB-Engine 的统计,反映了从 2013 年到今年所有的 NoSQL 类数据库的发展趋势。横轴代表的是时间,纵轴可以认为是受众程度,或者社区里的讨论热烈程度。大家可以看到绿色的线就是图数据库。这些年一共翻了十倍,增长还是非常迅猛的。
图数据库的简要介绍
在座的同事是 H 专家,部分可能对于图数据库有些不太了解,我这里简单介绍一下图数据库。它的主要应用场景其实是针对于各种各样的点和边组成的数据集合。

图数据库典型应用场景
举几个例子来讲,典型图数据库的应用场景有以下几个。
社交场景
社交场景是一个我们常见的社交场景,就是好友之间的关系。这个自然而然构成了一张图。比如说:在社交场景里面,做推荐算法。为某个人推荐他的好友。现在典型的方法都是去找好友的好友,然后看好友的好友有没有可能成为新的好友。这里面可能会有各种亲密度关系,以及各种各样的排序。传统来讲,我们可能会利用 MySQL 或者是 H 存各种各样的好友关系,然后通过多个串行的 Key Value 访问来查。但是真正在线上场景里面的话,是很难满足性能要求的。所以,另外一种做法是利用离线计算。把可能的好友关联和推荐都离线计算好。然后,查的时候直接去读已经准备好的数据,但这个问题就在于时效性比较差。对于有一些对于时效性要求比较高的场景,这样是不可以接受的。后面我有一些 case 可以来谈这个事情。
商业关系网络
商业关系网络:数据库的使用场景除了社交网络外,还有商业关系网络也很常见。在金融和风控领域,商业关系其实是很典型的一张图,多个公司之间有贸易往来,公司和银行之间也有往来。比如说一个公司去银行申请贷null款的时候,银行在审查这家公司可能本身没有什么问题,但是这家公司可能控制或者被控制的其他公司,或者整个集团的其他子公司,早已经进入了黑名单,甚至要控制一组相互担保的公司之间的总体贷款额度。这个时候就需要构成一些风控的功能来拒掉这笔贷款。商业关系里面还有人与人之间的转账关系,比如去查一个信用卡反套null现的网络。很典型的一个网络社群就是:A 转账到 B,B 转账到 C,C 又转让回 A 就是一个很典型的一个环。更多的黑产可能会是一个很大的黑产社区。对于这样的闭环,这类查询在图数据库大规模应用之前,大部分都是采用离线计算的方式去找。但是离线场景很难去控制当前发生的这笔交易。例如一个信用卡交易或者在线贷null款,整个作业流程很长,在反套null现这块的审核时间可能只有秒级。这也是图数据库非常大的一个应用场景。
知识图谱
知识图谱:除了商业关系还有一个就是知识图谱。知识图谱这个概念提出来已经很早了,大概是在 2004,2005 年的时候,Google 把自己的 search engine 慢慢的从倒排转到知识图谱上。这样在 search 的时候可以回答一些问题,比如说今天的天气怎么样?比如说现在谁的老婆的外甥的二大爷是谁。根据一些类似于问题式的知识,而不是基于关键字进行 search。知识图谱这几年非常的火,主要的原因就是一些垂直领域,慢慢的发现知识图谱非常的有价值。比如说:在金融领域上会有自己金融领域的知识图谱,结合一些 NLP 技术做大量的财报自动分析,或者像 Kensho 这样的新闻事件驱动自动生成分析报表和投资建议;还可以做一些投资组合,发现一二级市场公司内的关联关系,财务造假或者地方债暴雷造成的风险传播。再比如很多做在线教育的同事可能知道,在线教育的领域里面也有不少知识图谱。比如说有哪些考点,这个题是属于哪些考点,考点之间是怎么关联起来的,做错的考点附近的知识点都需要加强,这样也是一张关系网络。也是图数据库一个广泛应用的场景。
IoT 物联网(Internet of Things)
IoT 物联网(Internet of Things)是目前非常火的。以前,每一个设备都是单纯的 Device,设备和设备之间是没有关系的。但是,物联网的出现打通了这些设备之间的关系。比如:账号和设备都是有绑定关系的,账号和账号之间又有一定的关系,通过这样设备之间也可以建立出一张网络来。
一般来说,图数据库并不是简单的关联关系查询,在图遍历的过程,通常要根据属性做一些计算。所以一个单单的图关联是完全不能满足要求的。举个例子,这是一个股票新闻实时推荐的场景。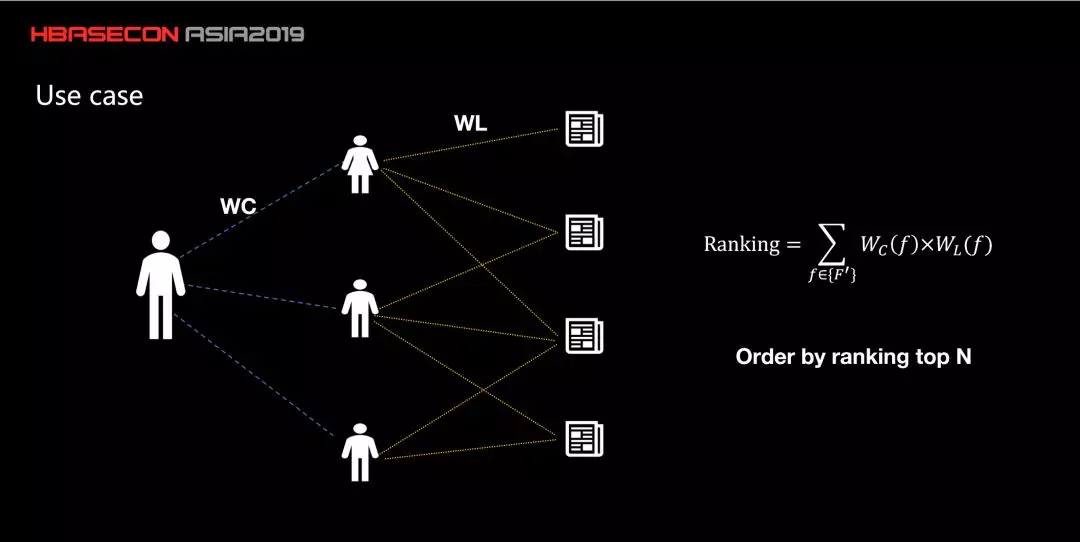
大家知道一般散户炒股并不是高频这样事件驱动的,但是他们也会边看新闻边盯着 K线。所以在这个时候要给他们推荐一些什么新闻呢。一般常见的办法是爬虫获得新闻,清洗完毕后,NLP 分词,提取出关键词后,然后跟股票代码关联上。一般根据监管,可能还要加上一些编辑审核和推送。但大家知道中国股市好的时候,是线下口口相传的。所以有个思路是通过好友圈来推荐新闻:首先会去找用户的好友,然后这些好友可能浏览过一些文章,那么根据驻留时间等,好友对这个文章可能会有一个评分,这个评分用 WL 来表示。好友和好友之间也有一定的亲密度,用 WC 表示。这个亲密度可以来源于之前的聊天次数、转账次数等。同一个人到一篇文章之间可能会有多条路径。比如说到第二篇文章,可能会有几十条路径。所以说这么多条路径的权值之和代表了我和这篇文章的之间的评分。最终给用户推荐文章的时候,希望是把所有的计算结果做 Top N。从线上的结果来看,转化效率比其他几种都要高。
图数据库面临的挑战
再回到技术底层,图数据库面临的技术挑战。
低延时高吞吐
一个挑战就是极低的 latency 和极高的 throughput。比如说查寻好友的好友这样的两跳场景,我们的 Nebula Graph 能在十毫秒以内返回,同时能做到单机 10 万的 pps。
大数据量
另外一个挑战就是数据量。一个典型的银行金融图谱,数据量已经可以达到百 T 规模,大概是几十亿个点和千亿条边的规模。当然,如果图本身只是存点 ID 和点 ID 之间的关联关系,这样的数据量千亿级别其实单机也能存储。但是实际上就像刚才说的,光纯点和边是不够的,还需要有很多图属性做分析,这样单机是肯定不够的。另外就是数据量增长的速度相当快,即使今天单机做个 POC 能存下,可能几个月之后又要扩容了。
复杂的商业逻辑
还有一个挑战就是现在越来越复杂的商业逻辑,用传统的数据库去分析,基本上每一个逻辑都要写 Java 代码来完成查询数据。我们希望不要那么依赖于开发人员,分析人员可以像写 SQL 一样,自己可以搞定。
高可用
最后一个挑战就是关于高可用要求。图数据库刚开始出现的时候,基本上就是一个二级索引。相当于只缓存了点和边之间的关系,真正的属性可能是在别的地方(比如 H 或者 MySQL 里面)。Data 本身的正确性和高可用都是都是依赖于这些组件的。但随着使用场景越来越多,这样分离的存储方式性能跟不上,自然就希望数据直接放在图数据库里面。那么各种传统数据库和分布式系统要面临的技术问题也要解决。比如数据多副本的强一致性问题,ACID。对于图数据库的要求越来越多,客户更希望作为一个数据库,而不是作为一个索引或者关系 cache。
Nebula Graph 的特点

存储计算分离
对于 Nebula Graph 来讲,有这么几个技术特点:第一个就是采用了存储计算分离的架构。这样架构主要的考虑其实前面几个 Talk大家都已经讨论了很多,主要好处就是为了上云或者说 弹性 , 方便单独扩容 。上午的 Talk:H on Cloud 也有提到,业务水位总是很难预测的,一段时间存储不够了,有些时候计算不够了。在云上或者使用容器技术,计算存储分离的架构运维起来会比较方便,成本也更好控制。大家使用 H 那么久,这方面的感触肯定很多。
查询语言 nGQL
Nebula Graph 的第二个技术特点是它的查询语言,我们称为 nGQL,比较接近 SQL。唯一大一点的语法差异就是 不用嵌套 ( ding)。大家都知道嵌套的 SQL,读起来是非常痛苦的,要从里向外读。
支持多种后端存储
第三个特点就是 Nebula Graph 支持多种后端存储,除了原生的引擎外,也支持 H 。因为很多用户,对 H 已经相当熟悉了,并不希望多一套存储架构。从架构上来说,Nebula Graph 是完全对等的分布式系统。
计算下推
和 H 的 CoProcessor 一样,Nebula Graph 支持数据计算下推。数据过滤,包括一些简单的聚合运算,能够在存储层就做掉,这样对于性能来讲能提升会非常大。
多租户
多租户,Nebula Graph是通过多 Space 来实现的。Space 是物理隔离。
索引
除了图查询外,还有很常见的一种场景是全局的属性查询。这个和 MySQL 一样,要提升性能的主要办法是为 属性建立索引 ,这个也是 Nebula Graph 原生支持的功能。
图算法
最后的技术特点就是关于图算法方面。这里的算法和全图计算不太一样,更多是一个子图的计算,比如最短路径。大家知道数据库通常有 OLTP 和 OLAP 两种差异很大的场景,当然现在有很多 HTAP 方面的努力。那对于图数据库来说也是类似,我们在设计 Nebula Graph 的时候,做了一些权衡。我们认为全图的计算,比如 Page Rank,LPA,它的技术挑战和 OLTP 的挑战和对应的设计相差很大。我们希望 Nebula Graph 能够在 OLTP 这块提供最好的表现。
Nebula Graph 的架构图
下面为大家介绍 Nebula Graph 的架构图:下图(图1)是基于原生存储的,图3 是基于 H 的,有一些不同。
基于原生存储的架构图
这条虚线上面是计算层,下面是存储层。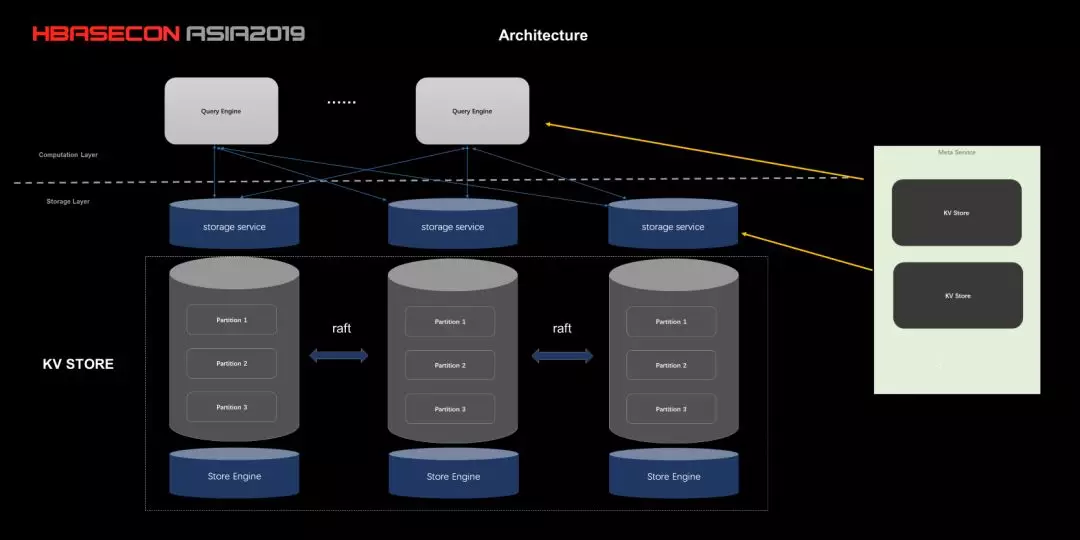
图 1:基于原生存储的架构图
我们先看下计算层,计算层可以理解为把一个 query 翻译成真正需要的执行计划,产生执行计划之后,到下面存储层拿需要的数据。这和传统数据库非常类似,查询语言也很类似。这里面比较重要的事情是查询优化,除了前面提到的计算下推到存储层外,目前一个主要的实现是并发执行。
查询服务架构图

图 2:Query Service
举个例子,查好友的大于 18 岁的好友,可能好友有很多,没有必要等一度好友都返回后,再去查二度好友。当然应该异步来做,一度好友部分返回后,就立刻开始二度查询。有点类似图计算里面的 BSP 和 ASP。这个优化对提升性能有非常大作用。对于 Storage 层来说,又分为上面的 Storage Engine 和 KV Store。因为 Nebula Graph 是分布式系统,数据是分片的。目前的分片方法是静态哈希,和 H 不一样。主要是因为图查询基本都是特定 Prefix 的 Scan,Get 很少。比如一个人的好友这样,就是同一个 prefix 的 scan。每一个数据分片会通过 RAFT 协议来保证数据的强一致。这和 H 写到底层 HDFS 也不一样。3 台机器上的 Partition1 组成一个 Raft Group。Storage Engine 做的事情比较简单,就是把图语义的查询请求翻译成 KV 的查询请求。关于图右边的 Service,它的主要作用是 schema 管理和集群管理。Nebula Graph 中的点和边都是有属性和版本的,那每个属性的类型和版本在 Service 中统一管理。集群管理主要用于运维和鉴权目的,负责机器上下线和对用户做 ACL。
Nebula Graph 基于 H 的架构图
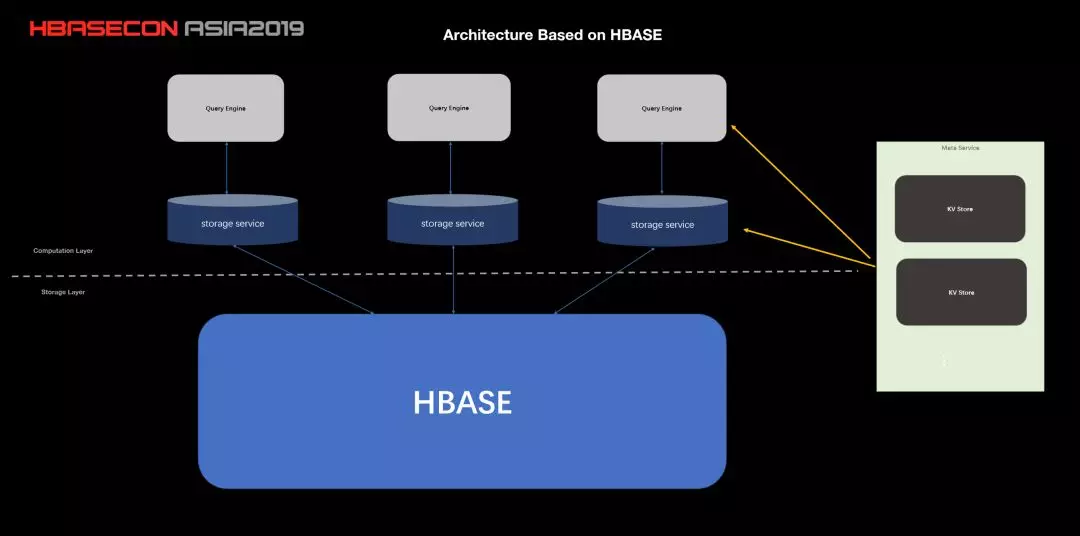
图 3:基于 H 的架构图
Nebula Graph 的 H 版本略微有些不一样,可以看到虚线往下挪了,Storage Service 嵌入到 Query Engine 里面,这是因为 H 是独立的服务,Storage Service 进程可以和 Query Engine 放同一台机器上,直接一对一服务了。另外,因为 H 自己有 partition,就没必要再分一次了。
Nebula Graph 的数据模型和 Schema
下面介绍下 Nebula Graph 的数据模型和 Schema(每种标签有一组相对应的属性,我们称之为 schema)。前面说到 Nebula Graph 是有向属性图,点和边都有各自属性。点有点属性,Nebula Graph 里面称为 Tag(类型),点可以有多种类型,或者叫多种 Tag。比如一个点既可以是 Tag Person,有属性姓名、年龄;也是 Tag developer,属性是擅长的语言。Tag 是可以像类一样继承的,一个 Tag 继承自另外一个 Tag。边和点略微有点不一样,一条边只能有一种类型。但是两个点之间可以有多种类型的边。另外,像 TTL 这种功能,Nebula Graph 也是支持的。 Nebula Graph 的数据模型和 Schema
Nebula Graph 的数据模型和 Schema!这里需要提一下,对于 H 和 Nebula Graph 原生存储来说,Schema Version 处理上是不一样的。H 是没有 Schema 的。强 Schema 最大的好处,是知道这条数据什么时候结束的,一行有多少属性是知道的。所以在根据某个版本号取数据的时候,从某一行跳到下一行,不需要对每个属性都扫描一遍。但如果像 H 这样弱 Schema 系统,性能消耗是非常大。但相应的,问题就来了,如果要支持强 Schema,要变更 Schema 怎么办?更改 Schema 在 MySQL 里面,往往要锁表的。对于 Nebula Graph 来说,当更改 Schema 时,并不是在原来的数据上进行更改,而是先插入一个新的 Schema,当然这要求写入数据的时候就要记录版本号。这样的话在读的时候,才能知道要用版本。

再解释一下关于 Key 的设计,点和边的 Key 设计是像上面两行这样,一个点是一个 Key,一条边是两个 Key,这样的目的是把起点和出边存在一起,对端的终点和入边存储在一起。这样在查询的时候,可以减少一次网络。另外,对于 Nebula Graph 原生存储和 H 存储,属性采用的存储方式也是不一样的。在 H 里面,一个属性放在一个 Column 里面。在原生存储里面,所有属性放在一个 Column 里面。这样设计的主要原因是,如果用户使用 H 作为底层存储,其实他更期望 H 这张表在别的系统里面也可以用,所以说我们考虑把它打散开了。
Nebula Graph 查询语言 nGQL
最后讲一下我们的 Query Language:nGQL
 我们说它比较类似 SQL,比如说看这个例子,从某一个点开始向外拓展,用 nGQL 来写就是,GO FROM $id,起始点,然后 OVER edge,沿着某条边,还可以设置一些过滤条件,比如说,从这个点出发,沿着我的好友边,然后去拿,里面年龄大于十八岁的。那要返回哪些属性?可以用 YIELD,比如说年龄,家庭住址。前面提到,不希望嵌套,嵌套太难读了,所以作为替代, Nebula Graph 用 PIPE 管道。前一条子查询的结果,PIPE 给第二条,然后第二条可以 PIPE 给第三条。这样从前往后读起来,和我们人的思考顺序是一样的。但是管道只解决了一个输入源的问题。多个输入源的时候怎么办?Nebula Graph 还支持定义某个变量,这个和存储过程有点像。像上面这样,把 $var 定义成一个子查询的结果,再把这个结果拿去给其他子查询使用。还有种很常见的查询是全局匹配,这个和 SQL 里面的 SELECT … FROM … WHERE 一样,它要找到所有满足条件的点或者边。我们这里暂时取名叫做 FIND。大家要是觉得其他名字好也可以在 GitHub 上给我们提 issue。最后就是一些 UDF,用户自己写的函数,有些复杂的逻辑用 SQL 可能不好描述,Nebula Graph 也希望支持让用户自己写一些代码。因为我们代码是 C++ 写的,再考虑到用户群体,做数据分析用 Python 比较多,我们考虑先支持 C++ 和 Python。
我们说它比较类似 SQL,比如说看这个例子,从某一个点开始向外拓展,用 nGQL 来写就是,GO FROM $id,起始点,然后 OVER edge,沿着某条边,还可以设置一些过滤条件,比如说,从这个点出发,沿着我的好友边,然后去拿,里面年龄大于十八岁的。那要返回哪些属性?可以用 YIELD,比如说年龄,家庭住址。前面提到,不希望嵌套,嵌套太难读了,所以作为替代, Nebula Graph 用 PIPE 管道。前一条子查询的结果,PIPE 给第二条,然后第二条可以 PIPE 给第三条。这样从前往后读起来,和我们人的思考顺序是一样的。但是管道只解决了一个输入源的问题。多个输入源的时候怎么办?Nebula Graph 还支持定义某个变量,这个和存储过程有点像。像上面这样,把 $var 定义成一个子查询的结果,再把这个结果拿去给其他子查询使用。还有种很常见的查询是全局匹配,这个和 SQL 里面的 SELECT … FROM … WHERE 一样,它要找到所有满足条件的点或者边。我们这里暂时取名叫做 FIND。大家要是觉得其他名字好也可以在 GitHub 上给我们提 issue。最后就是一些 UDF,用户自己写的函数,有些复杂的逻辑用 SQL 可能不好描述,Nebula Graph 也希望支持让用户自己写一些代码。因为我们代码是 C++ 写的,再考虑到用户群体,做数据分析用 Python 比较多,我们考虑先支持 C++ 和 Python。
Q&A
现场参会者提问:你们这个架构是 TinkerPop 的实现嘛?区别在哪里?
陈恒的回复如下:
不是的。我们是完全自研的。
首先我们查询语法并不是 Gremlin 那样命令式的,而是更接近 SQL 这种描述式的。可以说下我们的思考,我们主要考虑了查询优化的问题。
你知道像 Gremlin 那样的命令式语言,query 是 .in() .out() 这样一步步组成的,所以查询引擎只能按照给定的命令一步步把数据捞上来,每次序列化速度都很慢的,像 Titan 那样。我们的测试结果应该有几十倍的性能差距。
另外既然用户每步指令是明确的,查询引擎要做优化很难,要非常智能推测出用户整一串指令的最终期望才能优化,这样难度比较高。这个有点像编译器的优化,优化错就很麻烦了。
我们希望像 SQL 这样描述式的,用户说明最终目的就行,怎么处理交给执行引擎来优化,这样做优化比较容易完善,可借鉴的算法也比较多。
当然也和我们以 C++ 做开发语言有关。我们也有想过做 Gremlin 和 nGQL 之间的 driver,主要看社区,欢迎给我们提 issue
上面就是本次 Nebula Graph 参会 H Con Asia2019 的全部内容。
Nebula Graph:一个开源的分布式图数据库。
GitHub:https://github.com/vesoft-inc/nebula
继续阅读与本文标签相同的文章
服装零售企业数字化升级要“落地有数”
-
大数据心法来了!一站式玩转MaxCompute,还有开发者资源等你领!
2026-05-23栏目: 教程
-
怎么购买注册阿里云邮箱企业版
2026-05-23栏目: 教程
-
数据库安全加固
2026-05-23栏目: 教程
-
图数据库 Nebula Graph 的数据模型和系统架构设计
2026-05-23栏目: 教程
-
阿里云发布国内首个全域边缘节点服务,成5G计算基础
2026-05-23栏目: 教程