
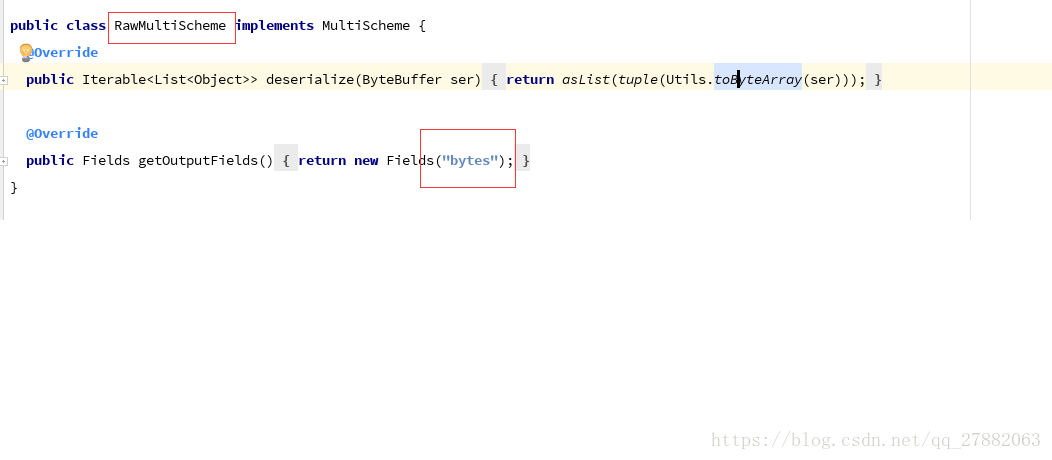
坑一:pom文件主要内容:注意里面 需要 使用 “exclusion”排除相关的依赖
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.7</maven.compiler.source> <maven.compiler.target>1.7</maven.compiler.target> <storm.version>1.1.1</storm.version> <kafka.version>0.9.0.0</kafka.version></properties><dependencies> <!--storm-core依赖--> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>${storm.version}</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>log4j-over-slf4j</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> </exclusion> </exclusions> </dependency> <!--storm-kafka 依赖--> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-kafka</artifactId> <version>${storm.version}</version> </dependency> <!-- kafka 依赖--> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>${kafka.version}</version> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.4</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>${kafka.version}</version> </dependency></dependencies>坑二: input.getBinaryByField(“bytes”); 里面一定要写成bytes,这是上游kafkaSpout 传递过来,源码中也可以看到。
对应位置如下图
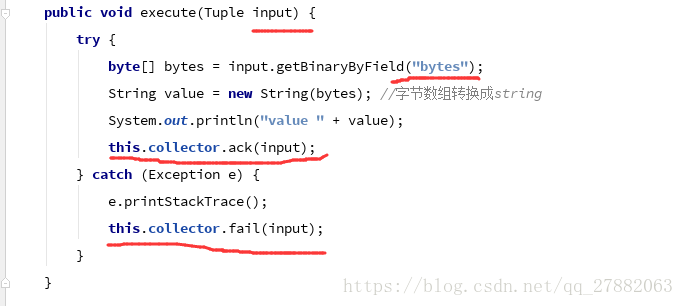
业务代码体现:
public void execute(Tuple input) {
try {
byte[] bytes = input.getBinaryByField(“bytes”);
String value = new String(bytes);
System.out.println(“value ” + value);
this.collector.ack(input);
} catch (Exception e) {
e.printStackTrace();
this.collector.fail(input);
}
}
坑三:本地测试是,一直接收不到kafkaSpout发送过来的消息:
1)问题是已经连接上了kafka,也读到了对应的分区
2)推断可能是上游的数据发送不过来—》 可能原因shuffleGrouping时 的参数传递错误。
3)最终发现 原来就是SPOUT_ID 获取错了
应该将下面代码中的
String SPOUT_ID = kafkaSpout.getClass().getSimpleName() 替换成 String SPOUT_ID = KafkaSpout.class.getSimpleName(); 即可。 // kafka 使用的zk hosts BrokerHosts hosts = new ZkHosts("hadoop000:2181");// 指定的kafak的一个根目录,存储的是kafkaSpout读取数据的位置信息(offset) SpoutConfig spoutConfig = new SpoutConfig(hosts, topicName, "/" + topicName, UUID.randomUUID().toString()); spoutConfig.startOffsetTime = kafka.api.OffsetRequest.LatestTime(); // 设置从最近的消息开始消费 KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig); String SPOUT_ID = kafkaSpout.getClass().getSimpleName(); builder.setSpout(SPOUT_ID, kafkaSpout); String BOLD_ID = LogProcessBolt.class.getSimpleName(); builder.setBolt(BOLD_ID, new LogProcessBolt()).shuffleGrouping(SPOUT_ID); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("StormToKafkaTopology", new Config(), builder.createTopology());坑四: storm重复消费kafak数据:
官网解释如下: 
代码中配置为如下即可 SpoutConfig spoutConfig = new SpoutConfig(hosts, topicName, "/" + topicName, UUID.randomUUID().toString()); spoutConfig.startOffsetTime = kafka.api.OffsetRequest.LatestTime(); // 设置从最近的消息开始消费坑五: storm消费数据,ack,fail这些比配,如果出现问题还可以重试
继续阅读与本文标签相同的文章
Cassandra 安装部署
scala 二分法查找
-
AI+视频云平台“智影”获数千万元Pre-A轮融资,投资方头头是道基金
2026-05-25栏目: 教程
-
excel导出工具
2026-05-25栏目: 教程
-
运动康复和慢病管理平台“术康”获4000万元B轮融资,某药企领投,IDG跟投
2026-05-25栏目: 教程
-
生物医药公司Apexigen完成共计7300万美元B轮、C轮融资,德联资本等投资
2026-05-25栏目: 教程
-
“校企合作共推实践型大数据师资培养”2018阿里云全国高校师资高级研修班成功举办
2026-05-25栏目: 教程