
模型架构
针对一个问题,文档集里有多答案的情况非常普遍,我们认为‘一边提高某个答案作为答案的概率,另一边又降低其它答案作为答案的概率’是不合理的。
因此我们的模型采用先从每篇文章中独立抽取候选答案,再从候选答案集中抽取最佳答案的结构,以解决多答案致使神经网络难以学习的问题。架构的具体实现中,我们通过BiDAF+ Passage Self-Matching从单篇文章中抽取答案,构成候选答案集,再使用em和xgboost决策树从候选答案集中抽取最佳答案。
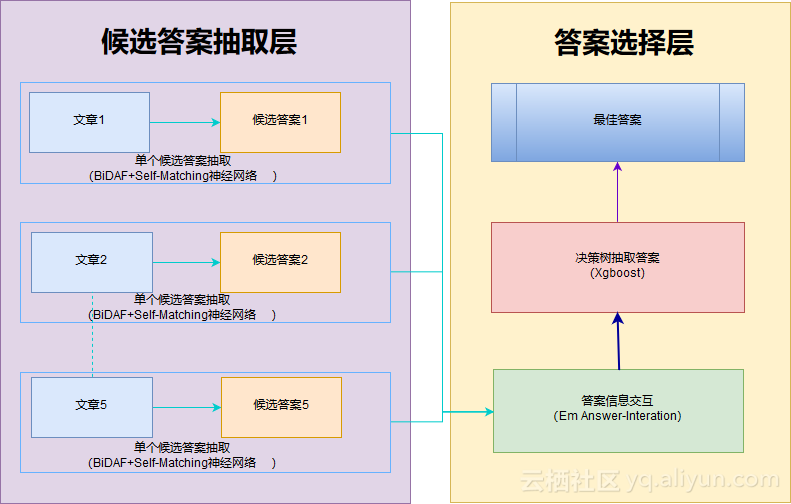
即模型分为以下两部分:
候选答案抽取层——BiDAF+Passage Self-Matching
答案选择层——em算法、xgboost
数据下载
数据移步比赛官网的数据下载页面,来自百度知道和搜索的真实场景数据集共包含30万问题,其中包括27万的训练集,1万开发集和2万测试集,分为4个部分供参赛用户下载。Em算法部分包含了百度知道集的tfidf模型文件,只需下载百度知道的数据文件便可用java运行,暂未做python实现。它在整个模型(Bidaf抽取答案、xgboost决策答案)作为特征扩充,交互答案之间的信息。
算法效果


原文发布时间为:2018-08-08
本文作者:huaiwen
本文来自云栖社区合作伙伴“专知”,了解相关信息可以关注“专知”
继续阅读与本文标签相同的文章
上一篇 :
记一次对DM数据库的优化过程
下一篇 :
数据库优化 - SQL优化
-
通过单元测试和 JaCoCo 提高 Java 代码覆盖率和质量
2026-05-26栏目: 教程
-
利用MySQL二进制包进行版本升级
2026-05-26栏目: 教程
-
MySQL源码目录
2026-05-26栏目: 教程
-
MySQL大表删除工具pt-osc
2026-05-26栏目: 教程
-
python里面的MySQLdb模块
2026-05-26栏目: 教程