import socketimport reimport osimport sys# 由于前面太...
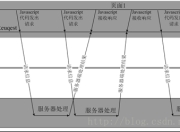
import socketimport reimport osimport sys# 由于前面太繁琐,可以用类封装一下,也可以分几个模块class HttpServer(object): def __init__(self,port): # 1、服务器创建负责监听的socket self.socket_watch = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 2、设置地址重用 self.socket_watch.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 3、绑定监听的端口 self.socket_watch.bind(('', port)) # 4、设置监听队列 self.socket_watch.listen(128) def handle_client(self,socket_con): """ 接收来自客户端的请求,并接收请求报文,解析,返回 """ # 1、服务器接收客户端的请求报文 request = socket_con.recv(4096).decode() # 2、截取请求报文,获取请求行 request_lines = request.split("
") # 3、获取请求行 request_line = request_lines[0] # GET /a/ab/c.html HTTP/1.1 # 通过正则表达式 匹配出请求行中请求资源路径 res = re.match(r"w+s+(S+)",request_line) # 获取资源路径 path = res.group(1) # 将资源路径和我的web文件夹的绝对路径拼接(自己填写) path ="# 本地绝对路径" + path # 在判断是文件还是文件夹之前,首先要判断你这个路径在服务器中是否存在 if not os.path.exists(path): response_line = 'HTTP/1.1 404 Not Found
' response_head = 'Server:skylark 2.0
' response_head += 'Content-type:text/html;charset=utf-8
' response_body = '你请求'+ path +'不存在' response = response_line + response_head + '
' +response_body socket_con.send(response.encode()) socket_con.close() return else: # 判断用户请求的是文件还是文件夹 if os.path.isfile(path): # 如果文件存在 读取页面数据,然后返回 response_line = "HTTP/1.1 200 OK
" response_head = "Server:skylark 2.0
" # 注意请求图片需要使用"rb"的方式进行读取 file = open(path,"rb") # response_body 是二进制所以不用再次编码 response_body = file.read() response = response_line.encode() + response_head.encode() +"
".encode() +response_body socket_con.send(response) socket_con.close() return else: if path.endswith("/"): # 例如 www.baidu.com/images # 用户请求的文件夹 # 1、判断该文件夹下是否有默认的文件,如果有,则返回,如果没有 # index.html default.html default_document = False # 如果允许你访问我目录下的默认文档 if default_document: # 判断用户访问的文件夹下是否有index.html 或者 default.html if os.path.exists(path + '/index.html'): response_line = 'HTTP/1.1 200 OK
' response_head = 'Server:skylark 2.0
' file = open(path+'/index.html', 'rb') response_body = file.read() response = response_line.encode() + response_head.encode() +'
'.encode()+response_body socket_con.send(response) socket_con.close() return elif os.path.exists(path + '/default.html'): response_line = 'HTTP/1.1 200 OK
' response_head = 'Server:skylark 2.0
' file = open(path + '/default.html', 'rb') response_body = file.read() response = response_line.encode() + response_head.encode() + '
'.encode() + response_body socket_con.send(response) socket_con.close() return else: # 访问的目录下,既没有index.html 也没有default.html response_line = 'HTTP/1.1 404 Not Found
' response_head = 'Server:skylark 2.0
' response_head += 'Content-Type:text/html;charset=utf-8
' response_body = 'index.html 或者 default.html 不存在' response = response_line +response_head +'
' +response_body socket_con.send(response.encode()) socket_con.close() # 2、判断服务器是否开启了目录浏览 else: # 判断你是否开启了目录浏览 dir_browsing = True if dir_browsing: # 把用户请求的文件夹中所有的文件和文件夹以目录的形式返回到页面中 # 获取用户请求的文件夹 list_names = os.listdir(path) response_line = 'HTTP/1.1 200 OK
' response_head = 'Server:skylark 2.0
' # 动态的拼接页面,将目录中的文件或者文件夹的名称以HTML页面的方式返回给浏览器 response_body = '<html><head><body><ul>' for item in list_names: response_body +="<li><a href = '#'>"+item+"</a></li>" response_body+='</ul></body></head></html>' response =response_line + response_head +'
' +response_body socket_con.send(response.encode()) socket_con.close() return else: # 用户请求的路径没有斜线 # 重定向到+斜线的目录下 response_line = 'HTTP/1.1 302 Found
' response_head = 'Server:skylark 2.0
' response_body = 'redirect'+ path +'/' response = response_line +response_head +'
' +response_body socket_con.send(response.encode()) socket_con.close() def run_server(self): # 5、通过循环,不停的接收来自客户端的连接请求 while True: socket_con, con_adds = self.socket_watch.accept() # 注意将con_adds转成字符串 print('客户端:%s连接成功!!!' % str(con_adds)) # 接收来自客户端的请求,并接收请求报文,解析,返回 self.handle_client(socket_con)def main(): # sys.argv方法的用法如下: # 在终端输入 python3 面向对象封装的web服务器.py 8888 # 在使用解释器执行任意py文件的时候,可以传入不止一个参数,会以字符串的形式用列表保存起来 # 但是列表的第一个参数[0]位是它自己。所以传入的参数是从[1]第二位开始的 # 所以在上面输入8888以后,调取这个列表的[1]下标就会传入这个8888作为进到下面的代码 # 再转换一下类型为int就相当于用户指定端口了 port = int(sys.argv[1]) http_server = HttpServer(port) http_server.run_server()if __name__ == '__main__': main()
------- 知识无价,汗水有情,如需搬运请注明出处,谢谢!
版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。