前言
我一直在使用Mybatis作为持久化框架,并且觉得Mybatis十分的不错,足够灵活,虽说需要自己手写sql,但是这也是我觉得的一个优点,直观并且优化方便.
但是我觉得JPA规范也有其优点,比如说简单,在一些基本的CRUD操作时,完全无需手写SQL.
因此趁着空闲,对Spring Data JPA做一个了解,并简单的写一个Demo来学习使用.
定义
在本文可能会涉及一下几个概念,这里统一讲一下定义.
JPA
JPA,即Java Persistence API.是Sun公司在Java EE 5规范中提出的Java持久化接口,即一种规范.
ORM
对象关系映射,即Object Relational Mapping,简称ORM.是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换.
Hibernate
Hibernate是一种ORM框架,Hibernate在3.2版本开始,已经完全兼容JPA标准.
Mybatis
Mybatis是另外一种ORM框架.使用它构建项目可以看Spring Boot Mybatis Web 开发环境搭建
Spring Data JPA
Spring Data JPA是Spring基于Hibernate开发的一个JPA框架,实现了JPA规范.
Spring Data JPA 实现原理
前文说过,JPA的一个优点就是不用写简单的CRUD的SQL语句,那么怎么做到的呢?
JPA可以通过如下两种方式指定查询语句:
- Spring Data JPA 可以访问 JPA 命名查询语句。开发者只需要在定义命名查询语句时,为其指定一个符合给定格式的名字,Spring Data JPA 便会在创建代理对象时,使用该命名查询语句来实现其功能。
- 开发者还可以直接在声明的方法上面使用 @Query 注解,并提供一个查询语句作为参数,Spring Data JPA 在创建代理对象时,便以提供的查询语句来实现其功能。
第一种功能基本可以满足日常所需,当需要连表查询或者一些更加复杂的操作室,可以使用@Query注解来使用自己编写的sql进行查询.
方法名和sql的对应关系在文末附录
环境搭建
首先使用Spring Boot 及Maven搭建一个项目,这部分不再赘述,有兴趣可以移步上面的链接.
添加依赖
在pox.xml中添加以下依赖,分别为:
- spring-data-jpa
- Hibernate-core
- Hibernate–annotations
- HikariCP
其中第四点为我使用的连接池,Spring Boot官方也比较推荐这个,当然,可以换成C3P0或者其他连接池.
<!-- spring-data-jpa -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.3.7.Final</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.hibernate/hibernate-annotations -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-annotations</artifactId>
<version>3.5.6-Final</version>
</dependency>
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.2.0</version>
</dependency>
配置文件
在application.yaml文件中加入以下内容,设置服务启动端口,使用配置为local以及数据源的一些配置,最后是JPA的配置.
server:
port: 9999
spring:
profiles:
active: local
datasource:
type: com.zaxxer.hikari.HikariDataSource
hikari:
minimum-idle: 0
initial-size: 5
maximum-pool-size: 15
auto-commit: true
pool-name: NezhaHikariCP
test-connection-on-checkout: true
jpa:
database: MYSQL
database-platform: org.hibernate.dialect.MySQL5InnoDBDialect
同时,新建application-local.yaml中加入以下内容,设置mysql数据源的相关信息.
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1/test?characterEncoding=utf8&useSSL=false
username: root
password: root
jpa:
show-sql: true
环境的搭建就是上面那么简单,第一步添加依赖,第二步添加一些配置就ok.
剩下的就是编写一些业务代码,而各种配置类什么的完全没有!!XML配置也没有!!
Demo创建
创建数据表
首先在数据库中创建表,本文测试表为(在test数据库中):
mysql> desc student;
+------------+-------------+------+-----+---------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------------------+-----------------------------+
| id | int(10) | NO | | NULL | |
| name | varchar(45) | NO | PRI | NULL | |
| class_num | int(12) | YES | | NULL | |
| age | int(3) | YES | | 18 | |
| created_at | timestamp | NO | | CURRENT_TIMESTAMP | |
| updated_at | timestamp | NO | | 2018-01-01 00:00:00 | on update CURRENT_TIMESTAMP |
+------------+-------------+------+-----+---------------------+-----------------------------+
6 rows in set (0.01 sec)
建表语句为:
CREATE TABLE `student` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT \'id\',
`name` varchar(45) NOT NULL COMMENT \'姓名\',
`class_num` int(12) DEFAULT NULL COMMENT \'班级\',
`age` int(3) DEFAULT \'18\' COMMENT \'年龄\',
`created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',
`updated_at` timestamp NOT NULL DEFAULT \'2018-01-01 00:00:00\' ON UPDATE CURRENT_TIMESTAMP COMMENT \'修改时间\',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
创建实体类
在model包下创建Student实体类:
package com.huyan.demo.model;
import java.util.Date;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
import javax.persistence.Temporal;
import javax.persistence.TemporalType;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* created by huyanshi on 2018/12/21
*/
@AllArgsConstructor
@Builder
@Data
@NoArgsConstructor
@Entity
@Table(name = \"student\")
public class Student {
@Id
private int id;
private String name;
private int classNum;
private int age;
@Temporal(TemporalType.TIMESTAMP)
private Date createdAt;
@Temporal(TemporalType.TIMESTAMP)
private Date updatedAt;
}
其中,@Entity标识此类是一个实体类,@Table指定关联的数据表.
创建dao层接口
package com.huyan.demo.dao;
import com.huyan.demo.model.Student;
import java.util.List;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
/**
* created by huyanshi on 2018/12/21
*/
@Repository
public interface StudentDao extends JpaRepository<Student,String> {
List<Student> findAll();
}
在接口上打上@Repository注解并实现JpaRepository接口.该接口使用了泛型,需要为其提供两个类型:第一个为该接口处理的域对象类型,第二个为该域对象的主键类型
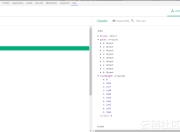
好,demo到此就结束了,service层和controller随意些,只要调用List<Student> findAll();这个方法,就会查找该表格中的所有数据.
我写了个很简单的接口,直接返回拿到的list,数据结果集为:

注意,在这个过程中,我们是没有手写SQL的,如果是在使用mybatis的过程中,我们需要编写select * from student的SQL语句.
更多方法示例
费劲搞了JPA,当然不可写一个方法就完事了.这样在实际应用中没有多少帮助.因此,我将一些常用的方法类型在这里测试一遍使用方法,最后,将其整合输出.
实际测试我才发现,许多的方法在继承的接口中早已定义,比如查询全量,根据主键嗯增删改查,排序,分页等,可谓十分强大,因此简单测试了大于小于及多参数的查询.
以下代码实际运行通过.
@Repository
public interface StudentDao extends JpaRepository<Student, Integer> {
//查询所有
List<Student> findAll();
//查询年龄大于传入值得
List<Student> findByAgeAfter(int age);
//查询年龄和班级等于入参的
List<Student> findByAgeAndClassNum(int age, int classNum);
//查询年龄为入参的学生,且结果按照创建时间排序
List<Student> findByAgeOrderByCreatedAt(int age);
//根据主键更新实体的名字年龄及班级
@Modifying(clearAutomatically = true)
@Transactional
@Query(value = \"UPDATE Student SET name = :name, classNum = :classNum, \"
+ \"age = :age WHERE id = :id \")
int updateNameAndAgeAndClassNumById(@Param(\"name\") String name, @Param(\"age\") int age,
@Param(\"classNum\") int classNum, @Param(\"id\") int id);
}
继承哪个接口
在上文中创建dao层接口中,我们要继承Repository接口,但是在Spring Data JPA中,提供了4个接口,到底该继承哪个呢?
- Repository接口,没有定义方法.
- CrudRepository接口,继承自Repository接口,定义了基本的增删改查.
- PagingAndSortingRepository接口,继承自CrudRepository接口,定义了排序及分页方法.
- JpaRepository接口,继承自PagingAndSortingRepository接口,提供了 flush(),saveAndFlush(),deleteInBatch() 等方法.
但是要说继承哪个接口呢?这个就见仁见智了,我是在不影响业务(主要是Crudrepository接口会提供删除方法,有时候你并不想提供删除)的情况下,我一般使用JPARepository,毕竟功能比较全嘛.
后话
在今天的学习后,对Jpa也算是有一点了解,在我看来,他和Mysql是两种不同的思路,但是都可以完成同一个任务.
在业务逻辑较为简单的时候,使用JPA可以提高开发效率,因为基本的增删改查你连方法定义都不需要写…然后大部分较简单的查询你都可以通过定义方法名来完成,实在不行还有@Query手写sql兜底.
附录:方法关键字和使用方式及生成的SQL列表
| Keyword | Sample | JPQL snippet |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age ⇐ ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection<Age> ages)</Age> | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection<Age> age)</Age> | … where x.age not in ?1 |
| TRUE | findByActiveTrue() | … where x.active = true |
| FALSE | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
参考链接
https://www.ibm.com/developerworks/cn/opensource/os-cn-spring-jpa/index.html
https://segmentfault.com/a/1190000009866465
完。
ChangeLog
2018-12-22 完成以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
联系邮箱:huyanshi2580@gmail.com
更多学习笔记见个人博客------>呼延十
版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。