PipeLine
- 查看页面结构
- 提取文章以及url
- 构造完整流程感受 yield 的强大
查看页面结构

提取文章以及url
大致思路:
1. 本页所有文章的链接
2. 下一页或下几页文章链接
3. 进入文章页面后提取文章内容
4. 构成一个循环,拿到网站所有文章内容
有了思路之后 Do it !
解析页面
-
神器 scrapy shell
使用方法上次已经说明,细节可以看一下其他博客,我们直接看效果
In [9]: response.xpath(\'//div[@class=\"grid-8\"]//div[@class=\"post-meta\"]//a[@class=\"archive-title\"]\').extract()

-
获取下一页的url (其实,只要得到下一页的url 就可以了,当然也可以一次得到10页,但是,何必呢?)
In [11]: response.xpath(\'//div[@class=\"navigation margin-20\"]//a[@class=\"next page-numbers\"]/@href\').extract() Out[11]: [\'http://blog.jobbole.com/all-posts/page/2/\']
OK, got it !
-
进入文章页面解析文章继续用熟悉的方式解析
response.xpath(’//div[@class=“entry”]/p/text()’).extract()
Out[18]:
[‘Linux 管理员一天都不能离开搜索文件,因为这是他们的日常活动。了解一些搜索的东西是不错的,因为这能帮助你在命令行服务器中工作。这些命令记忆起来不复杂,因为它们使用的是标准语法。’,
‘可以通过四个 Linux 命令啦执行此操作,每个命令都有自己独特的功能。’,
’ 命令被广泛使用,并且是在 Linux 中搜索文件和文件夹的著名命令。它搜索当前目录中的给定文件,并根据搜索条件递归遍历其子目录。’,
‘它允许用户根据大小、名称、所有者、组、类型、权限、日期和其他条件执行所有类型的文件搜索。’,
‘运行以下命令以在系统中查找给定文件。’,
\'运行以下命令以查找系统中的给定文件夹。要在 Linux 中搜索文件夹,我们需要使用 ‘,
’ 参数。’,
\'使用通配符搜索系统上的所有文件。我们将搜索系统中所有以 ‘,
’ 为扩展名的文件。’,
‘使用以下命令格式在系统中查找空文件和文件夹。’,
‘使用以下命令组合查找 Linux 上包含特定文本的所有文件。’,
’ 命令比 \',
’ 命令运行得更快,因为它使用 ‘,
’ 数据库,而 ‘,
’ 命令在真实系统中搜索。’,
‘它使用数据库而不是搜索单个目录路径来获取给定文件。’,
’ 命令未在大多数发行版中预安装,因此,请使用你的包管理器进行安装。’,
‘数据库通过 cron 任务定期更新,但我们可以通过运行以下命令手动更新它。’,
\'只需运行以下命令即可列出给定的文件或文件夹。在 ‘,
’ 命令中不需要指定特定选项来打印文件或文件夹。’,
\'在系统中搜索 ‘,
’ 文件夹。’,
‘在系统中搜索 ‘,
’ 文件。’,
’ 返回在终端输入命令时执行的可执行文件的完整路径。’,
‘当你想要为可执行文件创建桌面快捷方式或符号链接时,它非常有用。’,
’ 命令搜索当前用户而不是所有用户的 ‘,
’ 环境变量中列出的目录。我的意思是,当你登录自己的帐户时,你无法搜索 root 用户文件或目录。’,
‘运行以下命令以打印 ‘,
’ 可执行文件的完整路径。’,
‘或者,它允许用户一次执行多个文件搜索。’,
’ 命令用于搜索给定命令的二进制、源码和手册页文件。’,
‘\\xa0’]
4.解析完所有结构之后,写入文件
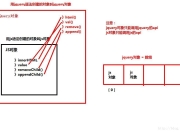
构造完整流程
上个帖子,已经构建了scrapy 框架,这里主要讲如何实现我们的思路,直接看代码
import scrapy
from scrapy.http import Request
from urllib import parse
class ArticlesSpider(scrapy.Spider):
name = \'articles\'
allowed_domains = [\'blog.jobbole.com\']
start_urls = [\'http://blog.jobbole.com/all-posts/\']
def parse(self, response):
\'\'\'
1.获取文章列表的 url , 然后解析
2. 获取下一页的url , 给scrapy 下载
:param response:
:return:
\'\'\'
article_list = response.xpath(\'//div[@class=\"grid-8\"]//div[@class=\"post-meta\"]//a[@ class =\"archive-title\"]/@href\').extract()
for url in article_list:
# 提取文章
# 若@href 出来的只有 完整url 后半段
# url = parse.urljoin(response.url,url)
yield Request(url= url,callback=self.parse1) # 这里的 callback 是回调函数,让其他函数来处理URL
next_page = response.xpath(
\'//div[@class=\"navigation margin-20\"]//a[@class=\"next page-numbers\"]/@href\').extract_first()
if next_page:
# 进入下一页
yield Request(url = next_page, callback=self.parse)
def parse1(self,response):
\'\'\'
提取文章
:param response:
:return:
\'\'\'
# 文章题目
title = response.xpath(\'//div[@class=\"entry-header\"]/h1/text()\').extract_first()
# 解析网页,得到文章
arricle = response.xpath(\'//div[@class=\"entry\"]/p/text()\').extract()
print(title)
大致流程是这样

是不是很神奇,才几行代码,就已经拿到了所有文章。这里想要保存的话,就自己想办法啦,下一次加入scrapy 的Item(),会更方便一些。先到这里啦,快下载代码爽一把吧!!!
注意:
- 现在很多是markdown 文章格式,也有其他文本格式,这个可能会专门解析,思路不会变,仅仅是稍微多了判定
版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。