Lucene 全文检索引擎的使用:
导入依赖jar包:
<?xml version=\"1.0\" encoding=\"UTF-8\"?>
<project xmlns...
Lucene 全文检索引擎的使用:
- 导入依赖jar包:
<?xml version=\"1.0\" encoding=\"UTF-8\"?>
<project xmlns=\"http://maven.apache.org/POM/4.0.0\"
xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\"
xsi:schemaLocation=\"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd\">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.mesmile</groupId>
<artifactId>hello-lucene</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<!--Lucene版本控制-->
<lucene-version>5.5.0</lucene-version>
</properties>
<dependencies>
<!--测试依赖包-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-core -->
<!--Lucene核心包-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene-version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common -->
<!--分词器依赖包-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lucene-version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser -->
<!--查询解析器依赖包-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>${lucene-version}</version>
</dependency>
</dependencies>
</project>
测试Lucene步骤:
-
一、创建索引
步骤:
1、 把文本内容转换为Document对象
文本是作为Document对象的一个字段而存在
2、准备IndexWriter(索引写入器)
3 、通过IndexWriter,把Document添加到缓冲区并提交
addDocument
commit
close -
二、搜索索引
步骤:
1 封装查询提交为查询对象
2 准备IndexSearcher
3 使用IndexSearcher传入查询对象做查询-----查询出来只是文档编号DocID
4 通过IndexSearcher传入DocID获取文档
5 把文档转换为前台需要的对象 Docment----> Article -
测试代码 :
package cn.mesmile;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.core.SimpleAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import java.nio.file.Paths;
/**
* @Created with IDEA
* @author: Super Zheng
* @Description: Lucene测试
* @Date:2018/12/23
* @Time:12:14
*/
public class TestLucene {
// 本地存储路径
private final static String PATH=\"D:\\\\javaEE\\\\crms-project\\\\hello-lucene\\\\lucene_repository\\\\hello\";
/**
* 1.测试创建索引
* @throws Exception
*/
@Test
public void testCreate () throws Exception{
// 准备的存入本地数据
String str1= \"hello world\";
String str2= \"hello java\";
String str3= \"hello lucene java\";
// 索引库的位置 FS fileSystem
Directory d = FSDirectory.open(Paths.get(PATH ));
// 分词器,注意这个分词器只能用于 分英文,若需分中文,请用导入包 Lucene-smartcn 然后用SmartChineseAnalyzer()替换SimpleAnalyzer()
Analyzer analyzer = new SimpleAnalyzer();
// 索引写入器的配置对象
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(d, conf);
// 将文本内容装换成Document
Document document1 = new Document();
document1.add(new TextField(\"title\",\"str1\", Field.Store.YES));
document1.add(new TextField(\"context\",str1, Field.Store.YES));
// 将文本内容装换成Document
Document document2 = new Document();
document2.add(new TextField(\"title\",\"str2\", Field.Store.YES));
document2.add(new TextField(\"context\",str2, Field.Store.YES));
// 将文本内容装换成Document
Document document3 = new Document();
document3.add(new TextField(\"title\",\"str3\", Field.Store.YES));
document3.add(new TextField(\"context\",str3, Field.Store.YES));
// 添加到缓存区
indexWriter.addDocument(document1);
indexWriter.addDocument(document2);
indexWriter.addDocument(document3);
// 提交
indexWriter.commit();
// 关闭
indexWriter.close();
}
/**
* 2.测试通过索引搜索
* @throws Exception
*/
@Test
public void testSearch () throws Exception{
// 测试查询的关键字
String keyWord = \"java\";
// 查询默认字段名
String f = \"context\";
// 查询所有关键词,分词器
Analyzer a = new SimpleAnalyzer();
QueryParser parser = new QueryParser(f, a);
// 获得查询条件 列名+查询的关键字
Query query = parser.parse(\"context:\" + keyWord);
// 准备IndexSearch
Directory directory = FSDirectory.open(Paths.get(PATH));
IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(indexReader);
// 查询记录的条数
int n = 10;
TopDocs topDocs =searcher.search(query, n);
// 命中所有的文档封装
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 索引的下标,从0开始
int doc = scoreDoc.doc;
// 将查询的数据封装成document
Document document = searcher.doc(doc);
// 打印输出查询结果
System.out.println(\"title:\"+document.get(\"title\")+\" context:\"+document.get(\"context\"));
}
}
}
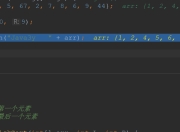
测试查询结果:



版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。
上一篇:Spring【DAO模块】就是这么简单 下一篇:Redis集群扩容