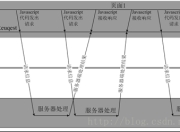
1.该模型是一个Seq2Seq的模型:
输入:(0,1)序列;例如x = (1,1,1,0,0,0,1,1)
标签:输出(0,1)序列右移若干位后的序列;例如将x右移2位后,y=(0,0,1...
1.该模型是一个Seq2Seq的模型:
输入:(0,1)序列;例如x = (1,1,1,0,0,0,1,1)
标签:输出(0,1)序列右移若干位后的序列;例如将x右移2位后,y=(0,0,1,1,1,0,0,0)
2.该模型的作用是给定一个(0,1)序列,预测其右移若干位后的序列。
3.该模型是一个深度的LSTM,其将3个LSTM堆叠到一起。
import numpy as np
import tensorflow as tf
参数
num_epochs = 100
total_series_length = 50000 # 生成数据的总长度
truncated_backprop_length = 15
state_size = 4 # cell state的尺寸
num_classes = 2
echo_step = 3
batch_size = 5
# total_series_length//batch_size==10000:表示每个样本的长度为10000
# num_batches:将10000以每15个为一个单位送入模型需要的次数
num_batches = total_series_length//batch_size//truncated_backprop_length
num_layers = 3
用于生成数据的函数
def generateData():
\'\'\'
随机生成长度为total_seires_length的0、1序列x;
将x循环右移echo_step步并将右移的数字清零生成y;
\'\'\'
# 0和1按照概率0.5,0.5进行随机抽样,抽样次数为total_series_length
x = np.array(np.random.choice(2,total_series_length,p=[0.5,0.5]))
y = np.roll(x,echo_step) # 将x循环右移echo_step步
y[0:echo_step] = 0
x = x.reshape((batch_size,-1))
y = y.reshape((batch_size,-1))
return x,y
定义计算图
# placeholder
X = tf.placeholder(tf.float32, [batch_size, truncated_backprop_length])
Y = tf.placeholder(tf.int32, [batch_size, truncated_backprop_length])
# 2:一个是output,一个是hidden state
init_state = tf.placeholder(tf.float32, [num_layers, 2, batch_size, state_size])
# state_per_layer_list是一个长度为num_layers的list
# state_per_layer_list中的元素shape为(2,batch_size,state_size)
state_per_layer_list = tf.unstack(init_state,axis=0)
# rnn_tuple_state用于stackedLSTM的初始状态
rnn_tuple_state = tuple([tf.nn.rnn_cell.LSTMStateTuple(state_per_layer_list[idx][0],state_per_layer_list[idx][1])
for idx in range(num_layers)])
# Variable
W = tf.Variable(np.random.rand(state_size,num_classes), dtype=tf.float32)
b = tf.Variable(np.zeros((1,num_classes)), dtype=tf.float32)
def get_lstm_cell():
return tf.nn.rnn_cell.LSTMCell(state_size,state_is_tuple=True)
# 为每一个layer创建一个cell
cells = [get_lstm_cell() for _ in range(num_layers)]
# 由cells创建一个stacked_cell
stacked_cell = tf.nn.rnn_cell.MultiRNNCell(cells,state_is_tuple=True)
# 将X和Y沿axis=1进行划分
inputs_series = tf.split(X, truncated_backprop_length, axis=1)
labels_series = tf.unstack(Y, axis=1)
outputs, current_state = tf.nn.static_rnn(stacked_cell, inputs_series, initial_state=rnn_tuple_state)
logits_series = [tf.matmul(output, W) + b for output in outputs] #Broadcasted addition
predictions_series = [tf.nn.softmax(logits) for logits in logits_series]
losses = [tf.nn.sparse_softmax_cross_entropy_with_logits(logits = logits, labels = labels) for logits, labels in zip(logits_series,labels_series)]
total_loss = tf.reduce_mean(losses)
train_step = tf.train.AdagradOptimizer(0.3).minimize(total_loss)
训练
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
loss_list = []
for epoch_idx in range(num_epochs):
x,y = generateData()
# 初始化stackedLSTM的状态
_current_state = np.zeros((num_layers, 2, batch_size, state_size))
print(\"New data, epoch\", epoch_idx)
for batch_idx in range(num_batches):
start_idx = batch_idx * truncated_backprop_length
end_idx = start_idx + truncated_backprop_length
batchX = x[:,start_idx:end_idx]
batchY = y[:,start_idx:end_idx]
# 将当前batch的current_state作为下一batch的初始状态
_total_loss, _train_step, _current_state, _predictions_series = sess.run(
[total_loss, train_step, current_state, predictions_series],
feed_dict={
X: batchX,
Y: batchY,
init_state: _current_state
})
loss_list.append(_total_loss)
if batch_idx%100 == 0:
print(\"Step\",batch_idx, \"Batch loss\", _total_loss)
New data, epoch 0
Step 0 Batch loss 0.6929052
Step 100 Batch loss 0.69577795
Step 200 Batch loss 0.6703381
Step 300 Batch loss 0.5743796
Step 400 Batch loss 0.46709153
Step 500 Batch loss 0.29781184
Step 600 Batch loss 0.13942471
New data, epoch 1
Step 0 Batch loss 0.38862282
Step 100 Batch loss 0.0061667175
Step 200 Batch loss 0.003976598
Step 300 Batch loss 0.002366404
Step 400 Batch loss 0.0024403462
Step 500 Batch loss 0.0022401384
Step 600 Batch loss 0.0013762511
New data, epoch 2
Step 0 Batch loss 0.43763518
Step 100 Batch loss 0.0046225637
Step 200 Batch loss 0.003416409
Step 300 Batch loss 0.0023665838
Step 400 Batch loss 0.002202603
Step 500 Batch loss 0.0018459581
Step 600 Batch loss 0.0012888594
......
New data, epoch 99
Step 0 Batch loss 0.11726279
Step 100 Batch loss 1.3494291e-05
Step 200 Batch loss 1.9135086e-05
Step 300 Batch loss 1.637907e-05
Step 400 Batch loss 2.0055128e-05
Step 500 Batch loss 1.4837313e-05
Step 600 Batch loss 1.6665135e-05
版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。