
作者:ANKIT CHOUDHARY
翻译:张睿毅
校对:吴金笛
文章来源:微信公众号 数据派THU
本文4300字,建议阅读10+分钟。
本文作者通过实战介绍了Deep Q-Learning的概念。
导言
我一直对游戏着迷。在紧凑的时间线下执行一个动作似乎有无限的选择——这是一个令人兴奋的体验。没有什么比这更好的了。
所以当我读到DeepMind提出的不可思议的算法(如AlphaGo和AlphaStar)时,我被吸引了。我想学习如何在我自己的机器上制造这些系统。这让我进入了深度强化学习(Deep RL)的世界。
即使你不喜欢玩游戏,深度强化学习也很重要。只用看当前使用深度强化学习进行研究的各种功能就知道了:
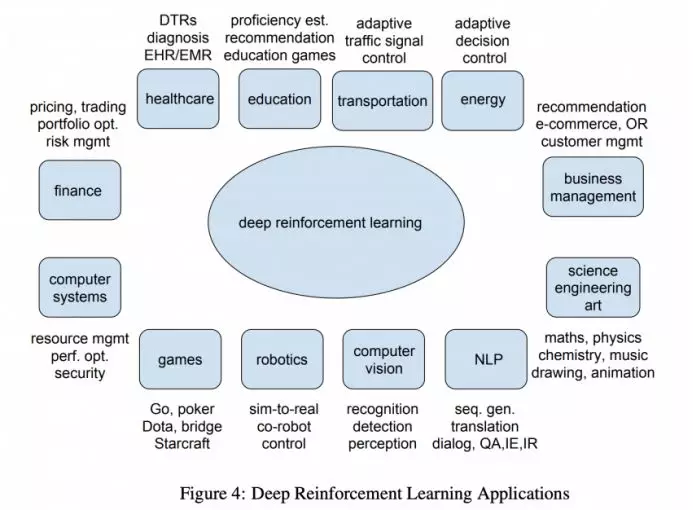
那工业级应用程序呢?这里有两个最常见的深度强化学习用例:
- 谷歌云自动机器学习(Google’s Cloud AutoML)
- 脸书Horizon平台
继续阅读与本文标签相同的文章
上一篇 :
独家 | 一文教你如何处理不平衡数据集(附代码)
-
独家 | kaggle季军新手笔记:利用fast.ai对油棕人工林图像进行快速分类(附代码)
2026-05-19栏目: 教程
-
GitHub火热!程序员小哥不得不知的所有定律法则(附项目链接)
2026-05-19栏目: 教程
-
独家 | 教你使用简单神经网络和LSTM进行时间序列预测(附代码)
2026-05-19栏目: 教程
-
独家 | 10个数据科学家常犯的编程错误(附解决方案)
2026-05-19栏目: 教程
-
JDK1.6 对 synchronized 的锁优化
2026-05-19栏目: 教程