
需求缘起
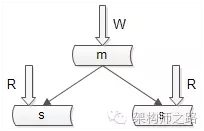
大部分互联网的业务都是“读多写少”的场景,数据库层面,读性能往往成为瓶颈。如下图:业界通常采用“一主多从,读写分离,冗余多个读库”的数据库架构来提升数据库的读性能。
这种架构的一个潜在缺点是,业务方有可能读取到并不是最新的旧数据: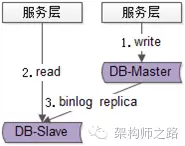
(1)系统先对DB-master进行了一个写操作,写主库
(2)很短的时间内并发进行了一个读操作,读从库,此时主从同步没有完成,故读取到了一个旧数据
(3)主从同步完成
有没有办法解决或者缓解这类“由于主从延时导致读取到旧数据”的问题呢,这是本文要集中讨论的问题。
方案一(半同步复制)
不一致是因为写完成后,主从同步有一个时间差,假设是500ms,这个时间差有读请求落到从库上产生的。有没有办法做到,等主从同步完成之后,主库上的写请求再返回呢?答案是肯定的,就是大家常说的“半同步复制”semi-sync: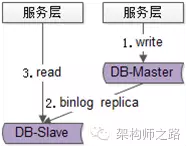
(1)
继续阅读与本文标签相同的文章
上一篇 :
创业公司快速搭建立体化监控之路(WOT2016)
下一篇 :
单点系统架构的可用性与性能优化
-
互联网架构,如何进行容量设计?
2026-05-20栏目: 教程
-
微服务架构多“微”才合适?
2026-05-20栏目: 教程
-
Java内存区域与Java内存模型
2026-05-20栏目: 教程
-
互联网架构为什么要做服务化?
2026-05-20栏目: 教程
-
如何实现超高并发的无锁缓存?
2026-05-20栏目: 教程