
一.集群配置
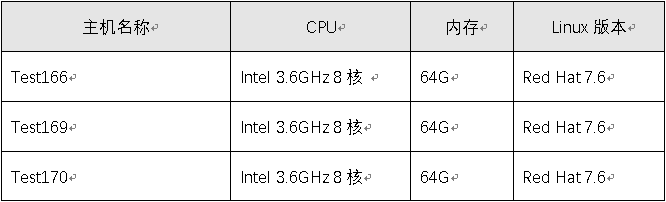
二.角色分布

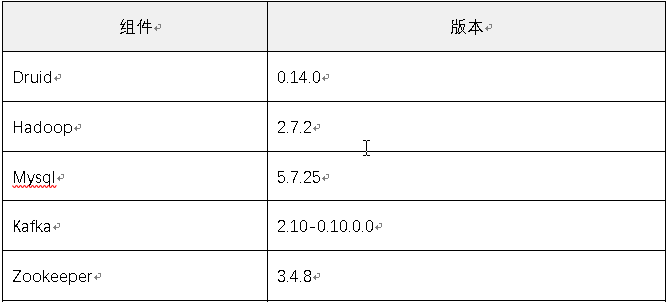
三.集群版本
四.性能测试
Ⅰ).数据时效性测试
a).测试案例
模拟生产由5000个agent、5000个URL和2类请求方式做为聚合字段的1亿条明细数据,来测试Druid集群在配置不同TaksCount数时,Druid聚合任务的执行时长
- 明细数据:1亿条
- 聚合组合:5000个agent 5000个URL 2类Method Type = 5千万
- 创建Topic的partition等于配置TaksCount的个数
- 执行任务,统计kafka磁盘占用和druid任务执行时长

b).测试数据
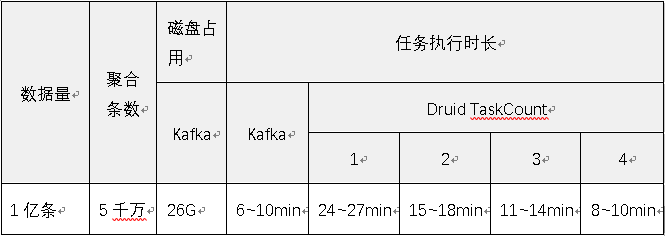
c).测试结果
- 在相同数据量的情况下,增加TaksCount可以提高druid聚合任务的处理速度
- 同时增加TaksCount会带来系统内存的线性增加
Ⅱ).Druid生成segment合理性测试
a).测试案例
模拟生产由5000个agent、5000个URL和2类请求方式做为聚合字段的1亿条明细数据,来测试Druid集群在配置不同TaksCount数和不同MaxRowsPerSegment时,Druid聚合任务生成segment大小的合理配置
- 明细数据:1亿条
- 聚合组合:5000个agent 5000个URL 2类Method Type = 5千万
- 创建Topic的partition等于配置TaksCount的个数
- 配置不同TaksCount数和不同MaxRowsPerSegment组合

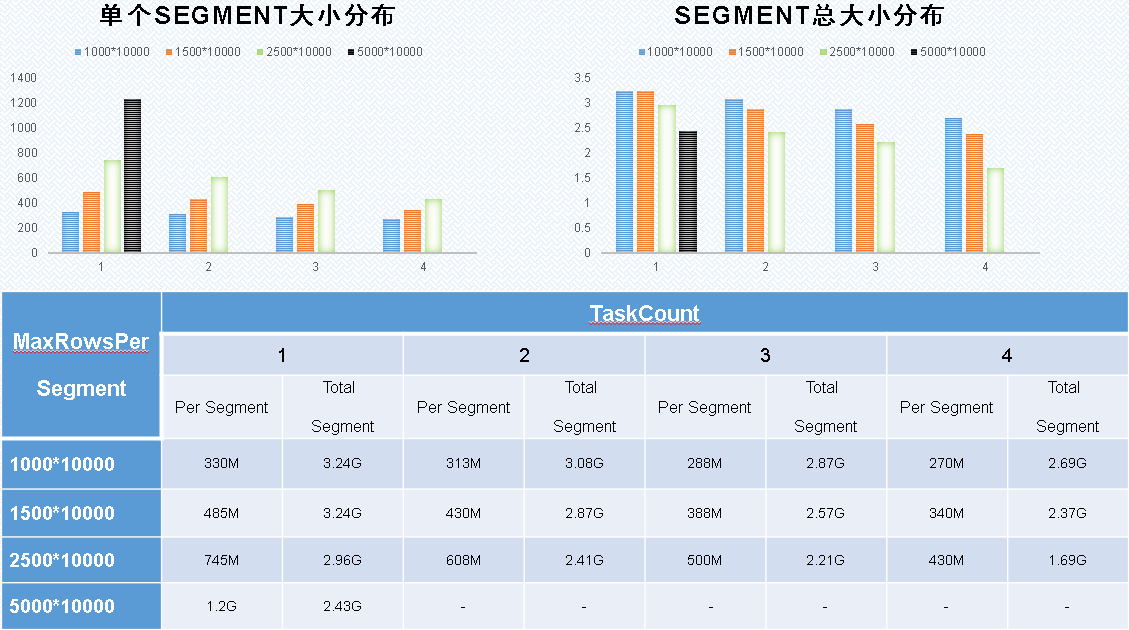
b).测试数据
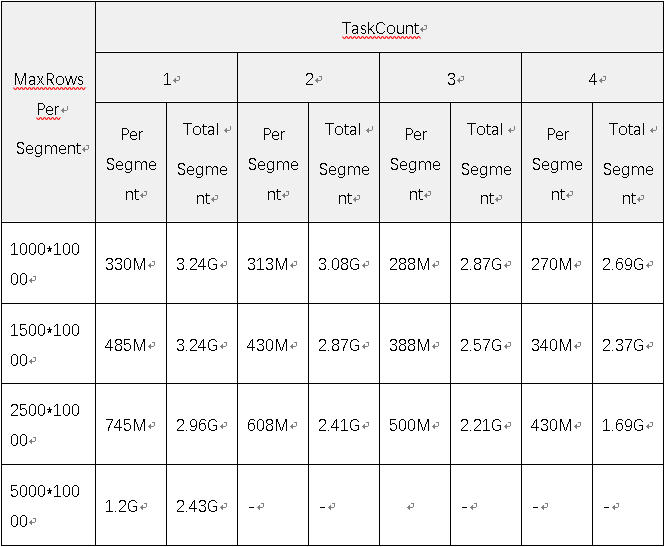
c).性能数据
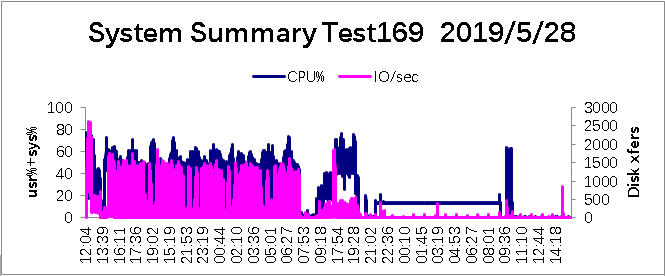
System Summary
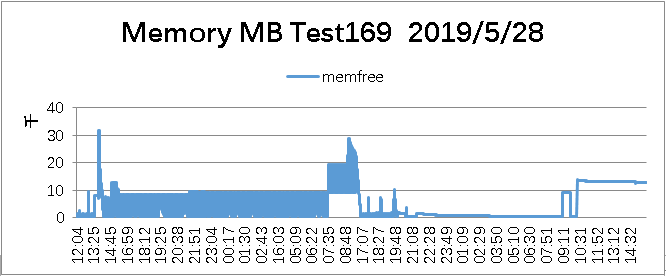
Memory
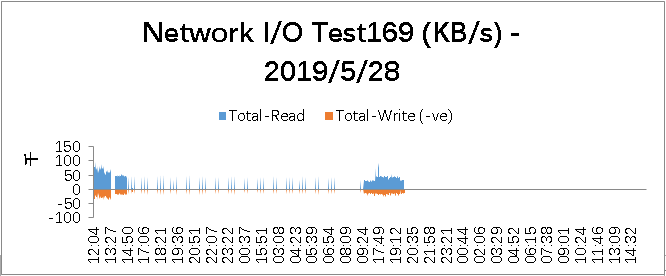
Network I/O
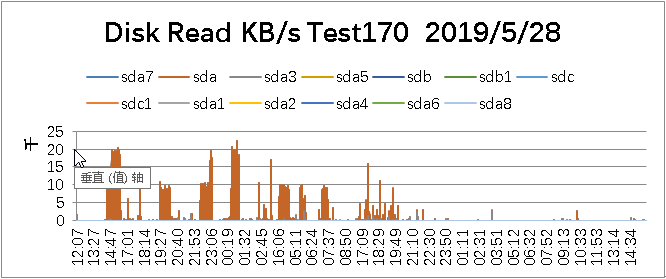
Disk Read
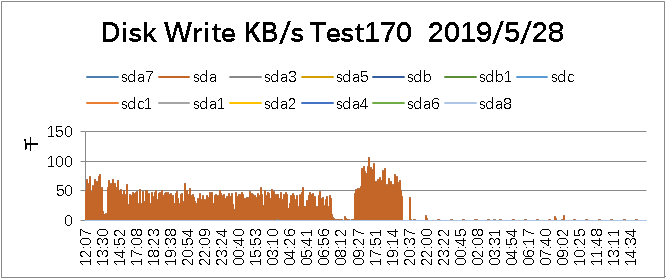
Disk Write
d).测试结果
- 为提高查询响应,建议segment在300M~700M之间
- 在源数据基础上需统计的dimensions字段一定的情况下,segment大小受MaxRowsPerSegment和TaksCount的共同影响
- 可根据实际测试数据的信息量来选择合理的MaxRowsPerSegment和TaksCount配置
Ⅲ).冷热数据隔离测试
a).测试案例
模拟生产由5000个agent、5000个URL和2类请求方式做为聚合字段的1亿条明细数据,来测试Druid集群在配置不同TaksCount数和不同MaxRowsPerSegment时,Druid聚合任务生成segment的冷热数据隔离测试
- 明细数据:1亿条
- 聚合组合:5000个agent 5000个URL 2类Method Type = 5千万
- 创建Topic的partition等于配置TaksCount的个数
- 根据配置将数据存储分为冷热数据集群,然后依据数据查询场景,将数据加载至对应集群
b).测试数据
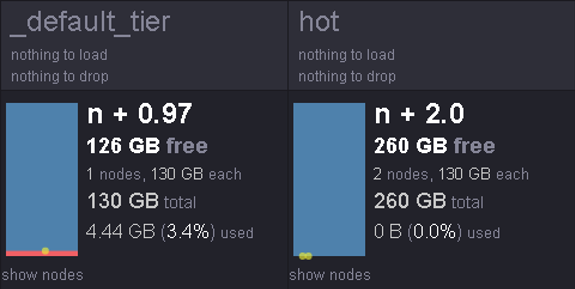
集群配置规则
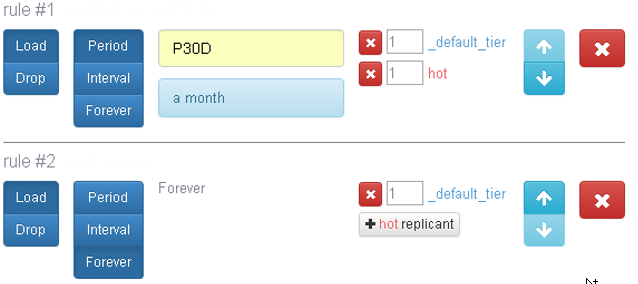
数据加载规则
d).测试结果
- 集群规模大于7个节点,使用冷热数据隔离可提高查询效率
- druid.server.priority=100d的节点,查询热数据时,查询不会路由至冷数据节点
e).备注热数据节点配置
druid.server.tier=hotdruid.server.priority=100继续阅读与本文标签相同的文章
上一篇 :
光通信的发展历程—从古至今
下一篇 :
浅谈lambda表达式<最通俗易懂的讲解>
-
RSA解密 优化 的原理详解 ,synchronized的使用
2026-05-21栏目: 教程
-
2019最新Java面试题——多线程
2026-05-21栏目: 教程
-
一遍记住Java常用的八种排序算法与代码实现
2026-05-21栏目: 教程
-
浅谈lambda表达式<最通俗易懂的讲解>
2026-05-21栏目: 教程
-
Apache Druid性能测评
2026-05-21栏目: 教程