
一、神经网络简单介绍
在计算机科学中,所讲的神经网络都是人工神经网络,它是计算机科学家们受到生物神经网络的启发而建立的。
人工神经网络由大量的人工神经元联结构成,神经元的示意图如下所示:
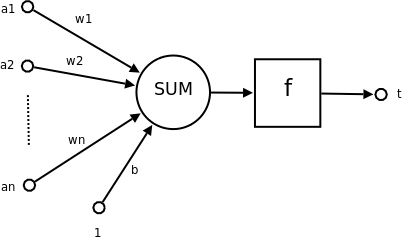
- a1~an为输入向量的各个分量
- w1~wn为神经元各个突触的权值
- b为偏置
- f为传递函数,通常为非线性函数。一般有traingd(),tansig(),hardlim()。
- t为神经元输出
数学表示:

可见一个神经元的功能就是,将它接收的多个输入通过某种方式(就是上面的数学表达式)转换成一个值然后再将其传递给后面的神经元。
神经网络由神经元联结构成,一个单层神经网络的结构如下所示:

单层神经网络是最基本的神经元网络形式,由有限个神经元构成,所有神经元的输入向量都是同一个向量。由于每一个神经元都会产生一个标量结果,所以单层神经元的输出是一个向量,向量的维数等于神经元的数目。
所以多层神经网络的结构示意图:
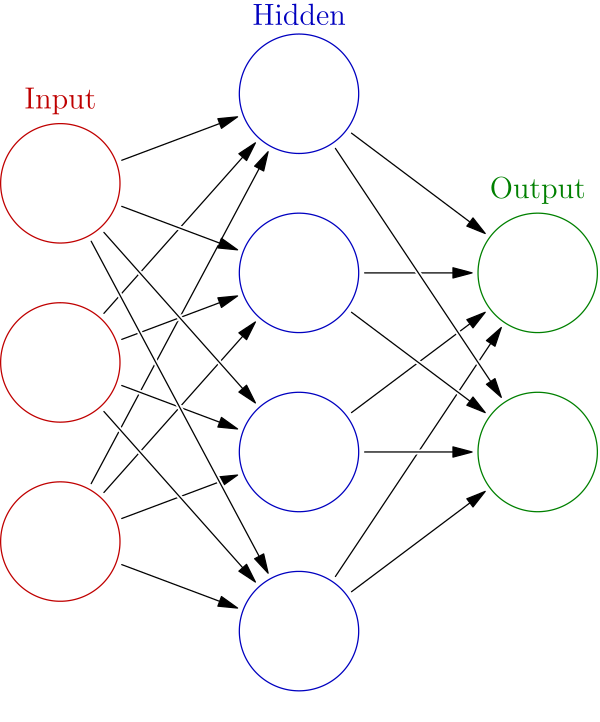
注:关于人工和生物神经网络的具体介绍,已在上文中给出了Wikipedia的链接,请参阅。
二、TensorFlow简介
TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理。Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow为张量从流图的一端流动到另一端计算过程。TensorFlow是将复杂的数据结构传输至人工智能神经网中进行分析和处理过程的系统。
TensorFlow可被用于语音识别或图像识别等多项机器学习和深度学习领域,对2011年开发的深度学习基础架构DistBelief进行了各方面的改进,它可在小到一部智能手机、大到数千台数据中心服务器的各种设备上运行。TensorFlow将完全开源,任何人都可以用。
三、TensorFlow基本使用
使用TensorFlow对于变量与常量的定义与平常在Python中编程不同,在TensorFlow中操作和传递的主要对象是tf.Tensor,这个Tensor是一个张量,所以定义一个变量或者常量的代码如下:
import tensorflow as tf# 定义常量matrix1 = tf.constant([2,2]) # 包含两个维度的向量,也即1阶张量matrix2 = tf.constant([[3, 1], [1, 3]]) # 2 × 2的矩阵,也即2阶张量 #定一一个普通变量,可以为这个变量传递一个name state = tf.Variable(0, name='counter') #标量,也即0阶张量注:上例中无论是tf.constant还是tf.Variable在tensorflow中都是的特殊张量。
在TensorFlow中另一个非常充要的API就是tf.Session,tf.Session拥有物理资源(例如 GPU 和网络连接),在TensorFlow中有很多的操作都需要用到tf.Session,比如:
import tensorflow as tf"""将两个矩阵相乘并打印结果"""matrix1 = tf.constant([[2,2]])matrix2 = tf.constant([[3], [3]])product = tf.matmul(matrix1, matrix2) #定义matrix1和matrix2的乘操作with tf.Session() as sess: result = sess.run(product) print(result)注:关于tf.Session的具体用法
例、使用TensorFlow完成一个简单的回归任务
1)先使用numpy生成数据(一个二次函数上的一些点,也就是需要学习一条抛物线)。
import tensorflow as tfimport numpy as np# create datax_data = np.random.rand(100).astype(np.float32)y_data = 0.1 * x_data ** 2 + 0.32)建立起要用于进行机器学习的结构(主要就是定义损失函数和优化器)。
"""create tensorflow structure start"""Weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))biases = tf.Variable(tf.zeros([1]))y = Weights * x_data + biasesloss = tf.reduce_mean(tf.square(y - y_data)) # 定义损失函数optimizer = tf.train.GradientDescentOptimizer(0.5) # 定义优化器train = optimizer.minimize(loss) # 训练的过程就是不断的减小loss最终取其最小值"""create tensorflow structure end"""3)创建session,并在session中run训练过程。
with tf.Session() as sess: #先将定义的所有variables进行init init = tf.global_variables_initializer() sess.run(init) # 非常非常重要 for step in range(201): sess.run(train) if step % 20 == 0: print(step, sess.run(Weights), sess.run(biases)) # 对某个值的输出也需要sess四、使用TensorFlow构建基本的神经网络
TensorFlow是一个深度学习框架,所以如何使用它构建神经网络并完成学习任务才是学习这个框架的重点,下面,将通过一个例子来介绍使用TensorFlow构建最简单的神经网络系统完成分类任务。
首先让我们来了解一下使用TensorFlow进行编码的大概过程:
- 导入和解析数据集。
- 创建特征列以描述数据。
- 选择模型类型。
- 训练模型。
- 评估模型的效果。
- 让经过训练的模型进行预测。
接下来,我们将使用TensorFlow来完成一个经典的分类问题(鸢尾花分类问题)。
(1)导入和解析数据集。
# 定义训练数据集和测试数据集的urlTRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"# csv文件各列的列名(最后一列是鸢尾花的种类,也即label)CSV_COLUMN_NAMES = ['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Species']...def load_data(label_name='Species'): """在这个函数中,我们将加载和解析在两个url中的csv文件""" # 将远程的csv文件拷贝的本地,返回的是这个文件在本地的路径 train_path = tf.keras.utils.get_file(fname=TRAIN_URL.split('/')[-1], origin=TRAIN_URL) # train_path为本地路径,通常为: ~/.keras/datasets/iris_training.csv # 使用pandas将csv文件读入 train = pd.read_csv(filepath_or_buffer=train_path, names=CSV_COLUMN_NAMES, # list of column names header=0 # ignore the first row of the CSV file. ) # train是一个pandas中的Data 数据结构 # 这种数据结构类似于一张表 # 1. 将train中的最后一列数据(也即Species列)分配给train_label # 2. 从train中删除Species列 # 3. 将其train中余数据分配给train_features train_features, train_label = train, train.pop(label_name) # 使用与训练集相同的方法解析测试集 test_path = tf.keras.utils.get_file(TEST_URL.split('/')[-1], TEST_URL) test = pd.read_csv(test_path, names=CSV_COLUMN_NAMES, header=0) test_features, test_label = test, test.pop(label_name) # 将解析结构返回(注意,解析后的这四份数据还是Data 结构). return (train_features, train_label), (test_features, test_label)(2)创建特征列以描述数据。
特征列是一种数据结构,告知模型如何解读每个特征中的数据。(特征列文档)
# 要构建一个feature_column 对象列表# my_feature_columns = [# tf.feature_column.numeric_column(key='SepalLength'),# tf.feature_column.numeric_column(key='SepalWidth'),# tf.feature_column.numeric_column(key='PetalLength'),# tf.feature_column.numeric_column(key='PetalWidth')# ]# 上面的写法不太优雅但是结构清晰,换种写法如下(两种写法效果相同)my_feature_columns = []for key in train_x.keys(): my_feature_columns.append(tf.feature_column.numeric_column(key=key))(3)选择模型类型。
神经网络是一个高度结构化的图,其中包含一个或多个隐藏层。每个隐藏层都包含一个或多个神经元。神经网络存在多个类别。我们将使用全连接神经网络,这意味着一个层中的神经元将从上一层中的每个神经元获取输入。

使用DNNClassifier(一个TensorFlow中预创建的Estimator,在后面的文章中我们将介绍其他的Estimator和自定义Estimator)构建一个简单的神经网络结构代码如下:
# 构建一个包含两个隐藏层的神经网络 classifier = tf.estimator.DNNClassifier( feature_columns=my_feature_columns, hidden_units=[10, 10], # 第一和第二个隐藏层都包含10个神经元,如果要添加更多层,只需在列表中加入一个整数即可,列表长度代表层数,每层神经元的个数有改位置的数值决定 n_classes=3) #整个数据集有几类这儿写几即可(4)训练模型。
在开始训练前,我们需要一个函数为模型提供训练数据,这个函数的代码如下:
def train_input_fn(features, labels, batch_size): """An input function for training""" # 要将输入转换成一个Dataset对象(有多少个样本这个对象就有多少个切片) dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels)) # 对dataset进行随机化洗牌,shuffle()传入的数据应大于样本的数量 # 进行训练时,常会多次处理样本,repeat()不传入任何参数可确保拥有无限量的训练集样本 # batch()的batch_size参数代表每次train时参与的样本数量,当样本数据量很大时,这通常很有用 dataset = dataset.shuffle(1000).repeat().batch(batch_size) # 返回Dataset对象 return dataset实例化 tf.Estimator.DNNClassifier 会创建一个用于学习模型的框架。调用 Estimator 对象的 train 方法即可开始训练
classifier.train( input_fn=lambda:train_input_fn(train_feature, train_label, args.batch_size), steps=args.train_steps)(5)评估模型的效果。
eval_input_fn 函数负责为模型提供来自测试集的样本。
def eval_input_fn(features, labels, batch_size): """An input function for evaluation or prediction""" features=dict(features) if labels is None: # 没有label,则inputs为features即可,此时inputs用于prediction inputs = features else: # label存在,则inputs为(features, labels),此时inputs用于evaluation inputs = (features, labels) # Convert the inputs to a Dataset. dataset = tf.data.Dataset.from_tensor_slices(inputs) # Batch the examples assert batch_size is not None, "batch_size must not be None" dataset = dataset.batch(batch_size) # Return the dataset. return datasettf.Estimator.DNNClassifier提供了evaluate,调用此方法即可。
# 评测模型eval_result = classifier.evaluate( input_fn=lambda:eval_input_fn(test_x, test_y, args.batch_size))print('
Test set accuracy: {accuracy:0.3f}
'.format(**eval_result))(6)让经过训练的模型进行预测。
同样的tf.Estimator.DNNClassifier提供了predict,调用此方法即可进行预测。
predictions = classifier.predict( input_fn=lambda:eval_input_fn(predict_x, labels=None, batch_size=args.batch_size))详细代码,请参阅该链接下的premade_estimator.py和iris_data.py文件。
(注:本人知识水平有限,如有不当,望批评指正。)
继续阅读与本文标签相同的文章
-
SQL审核工具发布
2026-05-26栏目: 教程
-
springboot与activemq的使用
2026-05-26栏目: 教程
-
利用quartz实现定时调度
2026-05-26栏目: 教程
-
一个线上问题引发的思考
2026-05-26栏目: 教程
-
Linux命令之telnet、head、tail
2026-05-26栏目: 教程