
| 本文提供全流程,中文翻译。 Chinar坚持将简单的生活方式,带给世人! (拥有更好的阅读体验 —— 高分辨率用户请根据需求调整网页缩放比例) |
一
——数据格式的写法
节点的书写规范必须是 <Root>开头 </Root>结束,中间包含子节点
<Root> —— 根节点; ID 是根节点 <Root>的一个属性
<People > —— 一级节点
<Name> —— 二级节点
<Age> —— 二级节点
名字取自《魁拔》动画电影 —— 推荐观看,国产有诗意的作品

<? version="1.0" encoding="utf-8"?><!--这是一行注释,上边首行是一个固定格式--><!--version:版本,encoding:编码格式--><Root> <People ID="1"> <Name>我的小鱼你醒了</Name> <Age>11</Age> </People> <People ID="2"> <Name>还记得早晨吗</Name> <Age>22</Age> </People> <People ID="3"> <Name>昨夜你曾经说</Name> <Age>33</Age> </People> <People ID="4"> <Name>愿夜幕永不开启</Name> <Age>44</Age> </People></Root>二
Read Data —— 读取数据
1
- - First Method —— 层层读取(- -复杂)
Document —— 文档
Element —— 元素
Application.dataPath —— 数据文件夹所在路径
Attribute —— 属性
InnerText —— 元素文本
( Element) —— 强制转换
using UnityEngine;using System. ;//引用 命名空间/// <summary>/// 测试读取 脚本/// </summary>public class Test : MonoBehaviour{ /// <summary> /// 初始化函数 /// </summary> void Start() { FistMethod(); //调用第一种方法 } /// <summary> /// 第一种读取方法 /// </summary> void FistMethod() { Document doc = new Document(); //实例化一个 Document类对象 :创建一个 文档 doc.Load(Application.dataPath + "/Data/ . "); //读取 文档 Element rootEle = ( Element) doc.LastChild; //获得根节点 :由于根节点就是最后一个节点,所以用Lastchild foreach ( Element childNodeEle in rootEle.ChildNodes) //遍历根节点中的子节点:rootEle.ChildNodes —— 返回的是所有子节点 { print(childNodeEle.GetAttribute("ID")); //打印子节点的属性 Element nameEle = ( Element) childNodeEle.ChildNodes[0]; //打印子节点<People>中的:子节点的第一个节点 <Name> Element ageEle = ( Element) childNodeEle.ChildNodes[1]; //打印子节点<People>中的:子节点的第二个节点 <Age> print(nameEle.InnerText + " " + ageEle.InnerText); //打印Name 和 Age } //rootEle.GetElementsByTagName("Name") 通过名字标签来获取元素 NodeList list = rootEle.GetElementsByTagName("Name"); //找到节点<Root>中,名叫<Name>的子节点. (系统会自动找<People>下的所有<Name>节点) foreach ( Element ele in list) //遍历集合中元素 { print(ele.InnerText); //打印元素文本Name } }}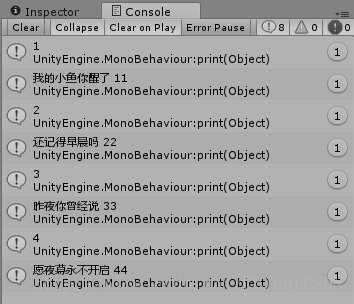
2
- - Second Method —— XPath表达式读取(- -简单)
1
- - XPath —— 绝对路径
Document —— 文档
Element —— 元素
Application.dataPath —— 数据文件夹所在路径
InnerText —— 元素文本
doc.SelectNodes("/Root/People/Name"); 函数中传入的参数为:绝对路径
“/根节点 Root /第一节点 People /第二节点 Name ”
函数会根据XPath表达式,找到 文档中,一个绝对路径下的所有 Name 子节点,并返回一个 List 集合
using UnityEngine;using System. ;//引用 命名空间/// <summary>/// 测试读取 脚本/// </summary>public class Test : MonoBehaviour{ /// <summary> /// 初始化函数 /// </summary> void Start() { SecondMethod(); //调用第二种方法 } /// <summary> /// 第二种读取方法 /// </summary> void SecondMethod() { Document doc = new Document(); //实例化一个 Document类对象 :创建一个 文档 doc.Load(Application.dataPath + " " + "/Data/ . "); //读取 文档 //XPath表达式来解析 :一个路径语法 //doc.SelectSingleNode(""); 查找单个节点 //doc.SelectNodes(""); 查找多个节点 //doc.SelectNodes("")返回值 :一个 nodeList 集合 NodeList list = doc.SelectNodes("/Root/People/Name");//“/根节点Root/第一节点People/第二节点Name” foreach ( Element ele in list)//遍历集合中的元素 { print(ele.InnerText); //打印元素文本 } }}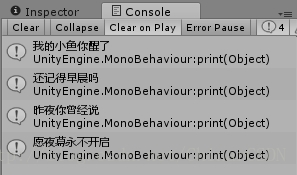
1
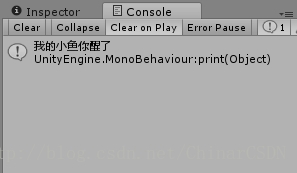
- - First Element —— 取得第一个元素
doc.SelectNodes("/Root/People[1]/Name");
取得第二个节点 <People> 中的第一节点 <Name>
2
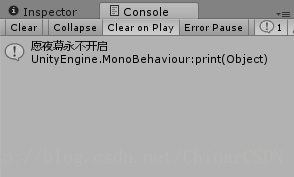
- - Last Element —— 取得最后一个元素
doc.SelectNodes("/Root/People[last()]/Name");
取得第二个节点 <People> 中的最后一个节点 <Name>
3
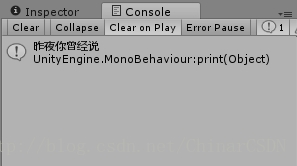
- - Penult Element —— 取得倒数第二个元素
doc.SelectNodes("/Root/People[last()-1]/Name");
取得第二个节点 <People> 中的倒数第二个节点 <Name>
4
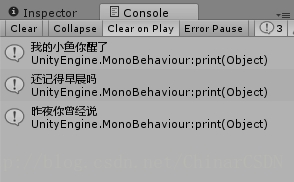
- - the top several Element —— 取得前几个元素
doc.SelectNodes("/Root/People[position()<4]/Name");
position() 小于4,就是前三个
取得第二个节点 <People> 中的前三个节点 <Name>
5
- - Select Attribute Element —— 根据属性值ID找节点
doc.SelectNodes("/Root/People[@ID]/Name");
取得第二个节点 <People> 中属性为 ID 的节点 <Name>
6
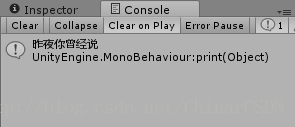
- - Reject Attribute Element —— 根据属性值ID剔除节点
doc.SelectNodes("/Root/People[@ID=3]/Name");
取得第二个节点 <People> 中属性为 ID = 3的节点 <Name>
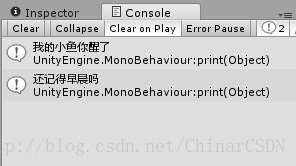
doc.SelectNodes("/Root/People[@ID<3]/Name");
取得第二个节点 <People> 中属性为 ID < 3的节点 <Name>
2
- - XPath ——相对路径(- - 极其简单)
Document —— 文档
Element —— 元素
Application.dataPath —— 数据文件夹所在路径
InnerText —— 元素文本
doc.SelectNodes("//Age"); 函数中传入的参数为:相对路径
“//第二节点 Age ”
函数会根据XPath表达式,找到 文档中,一个绝对路径下的所有 Age 子节点,并返回一个 List 集合
注意:数据量庞大的时候 —— 性能上没有绝对路径好
using UnityEngine;using System. ;//引用 命名空间/// <summary>/// 测试读取 脚本/// </summary>public class Test : MonoBehaviour{ /// <summary> /// 初始化函数 /// </summary> void Start() { thirdMethod(); //调用第三种XPath相对路径 读取方法 } /// <summary> /// 第三种XPath相对路径 读取方法 /// </summary> void thirdMethod() { Document doc = new Document(); //实例化一个 Document类对象 :创建一个 文档 doc.Load(Application.dataPath + " " + "/Data/ . "); //读取 文档 //XPath表达式来解析 :一个路径语法 //doc.SelectSingleNode(""); 查找单个节点 //doc.SelectNodes(""); 查找多个节点 //doc.SelectNodes("")返回值 :一个 nodeList 集合 NodeList list = doc.SelectNodes("//Age"); //直接找“//第二节点Age” —— 性能上没有绝对路径好 foreach ( Element ele in list) //遍历集合中的元素 { print(ele.InnerText); //打印元素文本 } }}
END
本博客为非营利性个人原创,除部分有明确署名的作品外,所刊登的所有作品的著作权均为本人所拥有,本人保留所有法定权利。违者必究
对于需要复制、转载、链接和传播博客文章或内容的,请及时和本博主进行联系,留言,Email: ichinar@icloud.com
对于经本博主明确授权和许可使用文章及内容的,使用时请注明文章或内容出处并注明网址
继续阅读与本文标签相同的文章
DoTween用法教程
iTween的用法总结
-
MySQL 查询命令
2026-05-27栏目: 教程
-
Etcd源码分析:网络
2026-05-27栏目: 教程
-
专访杨开振:程序员除了敲代码还能做什么?
2026-05-27栏目: 教程
-
金蝶医疗完成数千万元A+轮融资,将用于产品研发以及服务的升级迭代
2026-05-27栏目: 教程
-
天天学农完成2500万元A轮融资,经纬中国持续加注
2026-05-27栏目: 教程