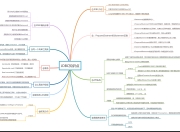
1.避免使用NULL字段
NULL字段很难查询优化,NULL字段的索引需要额外空间,NULL字段的复合索引无效,
NULL非常影响索引的查询效率 建议用0,特殊值或空串代替NULL值
age int NOT NULL DEFAULT 0; name varchar(30) NOT NULL DEFAULT \'\';
在对该字段进行COUNT()统计时,统计结果更准确或者执行WHERE column IS NULL检索时能快速返回结果。
2.拒绝3B
大sql,大事务,大查询.
避免在一个事务里有大查询存在这样会导致主从延迟。
3.存储ip
用int unsigned 而不是char(15)存储ip
select inet_aton(\'192.168.0.1\');
select inet_ntoa(3232235521);
4.禁止使用存储过程,触发器,视图,自定义函数等。
因为procedure trigger function views event 外键约束会降低集群扩展,用程序来实现。
5.索引添加
select,update,delete的where条件列
order by,group by,distinct字段,多表join字段。
like \'abc%\'可以用到索引 \'%abc%\'用不到
where条件里等号左右字段类型必须一致,否则无法利用索引
区分度最高而且使用比较频繁的列放在联合索引的最左侧,比如查询一个用户号码且支付状态,我们知道手机号码基数高,而状态基数低,但往往这两个常常组合使用,则建立idx_xxx(user_phone,user_status)
联合索引(a,b,c)相当于(a) (a,b) (a,b,c)
6.库名,表名,字段名禁止使用MySQL保留字。
例如status,name,names,number,month,hosts,year等
7.使用TINYINT来代替ENUM类型。
状态status,类型type等字段用tinyint类型节省存储空间
sex tinyint NOT NULL default 0 comment \'0:男 1:女\';
8.禁止在数据库中存储图片,文件等大数据。
9.没有预编译耗cpu,随着连接会话增多,性能降低
每个连接都是一个线程(非thread pool)
一个连接使用一个cpu,5.6最多能用到64核,所以严禁使用大查询语句会占用资源
10.数据库的校验字段
dba专有的校验字段,理论上业务不能用到,核心表(用户表,金钱相关)便于查问题
create_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',
update_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'更新时间\',
is_delete tinyint NOT NULL DEFAULT 0 COMMENT \'是否删除 0:有效 1:删除\',
11.计量单位精确值
金钱 decimal(N,2) 精确到分
费率 decimal(N,5) 精确到0.005%
里程 decima(N,2) 精确到公里
12.时间类型用int来存储时间
birthday_time int unsigned NOT NULL DEFAULT 0;
select unix_timestamp(\'2018-02-23 09:53:57\');
select from_unixtime(1519350837);
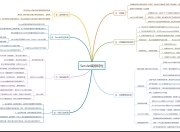
13.插入语句
insert语句指定具体字段名称,而且要批量插入insert into…values(XX),(XX),(XX)值不要超过5000个,值过多虽然上线很快,但会引起主从同步延迟。
14.字段类型避免浪费空间
int 4字节 -2^31 (-2,147,483,648) 到 2^31 - 1 (2,147,483,647)
bigint 8字节 -2^63 (-9223372036854775808) 到 2^63-1 (9223372036854775807)
tinyint 1字节 -128 - 127 unsigned无符号 0-255
smallint 2字节 -2^15 (-32,768) 到 2^15 - 1 (32,767) unsigned无符号0-65535
15.varchar与text区别
大于varchar(255)变为tinytext,大于varchar(500)变为text
对于text字段,MySQL不允许有默认值。varchar允许有默认值
尽量用varchar,超过255字节的只能用varchar或者text
一般建议用varchar类型,字符数不要超过2700
16.尽量选择数字类型来代替字符类型
能够用数字类型的字段尽量选择数字类型而不用字符串类型的(电话号码),这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接回逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
17.禁止在where条件列上使用函数
会导致索引失效,如lower(email),f_price%4,可放到右边的常量上计算
lower(f_name)=\'ruining\' 改为 f_name=lower(\'RuiNing\')
18.多表JOIN
要把过滤性最大的表选为驱动表,此外,如果JOIN之后有排序,排序字段一定要属于驱动表,才能利用驱动表上的索引完成排序。
先筛选然后join.尽量把结果集缩到最小然后join
19.默认使用InnoDB存储引擎,字符集选择utf-8,字段表名都需要注释,
数据库xxx_db表示,表以业务名区分,
标准的建表语句如下:
create database test_db default character set utf-8;
create table wms_user(
user_id int unsigned primary key auto_increment comment \'客户主键\',
user_name varchar(30) NOT NULL default \'\' comment \'客户姓名\',
user_phone int unsigned NOT NULL default 0 comment\'客户手机号码\',
user_age int NOT NULL default 0 comment \'客户年龄\',
user_sex tinyint NOT NULL default \'0\' comment \'客户性别 0:男 1:女\',
user_birthday date NOT NULL default \'1001-01-01\' comment \'客户出生日期\',
user_status tinyint NOT NULL default \'0\' comment \'客户状态 0:未激活 1:激活\',
create_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',
update_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'更新时间\',
is_delete tinyint NOT NULL DEFAULT 0 COMMENT \'是否删除 0:有效 1:删除\',
key idx_user_name(user_name),
key idx_phone_status(user_phone,user_status),
key idx_user_birthday(user_birthday)
)engine=innodb auto_increment=1 default charset=utf8 comment=\'仓库用户信息\';
20.mysql字段值不区分大小
使用varbinary存储大小写敏感的变长字符串
name varbinary(N) 这里的N指的是字节而不是长度,值会区分大小写
21.加前缀索引
长度超过50的varchar字段,最好创建前缀索引而非整列索引add index(f_name(20));
不过它的缺点是对这个列排序时用不到前缀索引
22.禁止在数据库中存储明文密码。
采用加密字符串存储密码,并保证密码不可解密
23.合并ddl语句
针对同一个表的结构变更,写为一个sql
属性,注释都要填写完整
alter table wms_good add column price decimal(9,2) NOT NULL DEFAULT \'0.00\' comment \'货物价格\';
alter table wms_good add column birthday int unsigned NOT NULL DEFAULT \'0\' comment \'生产日期\';
以上多个语句改写为一个:
alter table wms_good
add column price decimal(9,2) NOT NULL DEFAULT \'0.00\' comment \'货物价格\',
add column birthday int unsigned NOT NULL DEFAULT \'0\' comment \'生产日期\',
add index idx_birthday(birthday);
24.int(4)与int(11)的区别
这两个没区别,只是设置了zerofill属性有用,这两个都占用4个字节,在设置0填充时,如果存储100数字将会变成 0100 左侧填充
num1 int zerofill
25.or改为in,union
针对同一个字段
where province=\'河北\' or province=\'山东\' 改为 where province in (\'河北\',\'山东\');
针对索引合并
where province=\'河北\' or phone=\'137\' 改为
select id from t where province=\'河北\'
union
select id from t where phone=\'137\';
26.避免数据类型不一致
select * from t where id=\'19\'; 用不到索引
select * from t where id=19;
27.
日期的查询,建议用int型,不用DATE, 如20160909等
版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。