前言
声明,本文用得是jdk1.8
前面章节回顾:
本篇主要讲解TreeMap~
看这篇文章之前最好是有点数据结构的基础:
当然了,如果讲得有错的地方还请大家多多包涵并不吝在评论去指正~
一、TreeMap剖析
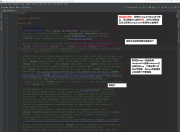
按照惯例,我简单翻译了一下顶部的注释(我英文水平渣,如果有错的地方请多多包涵~欢迎在评论区下指正)
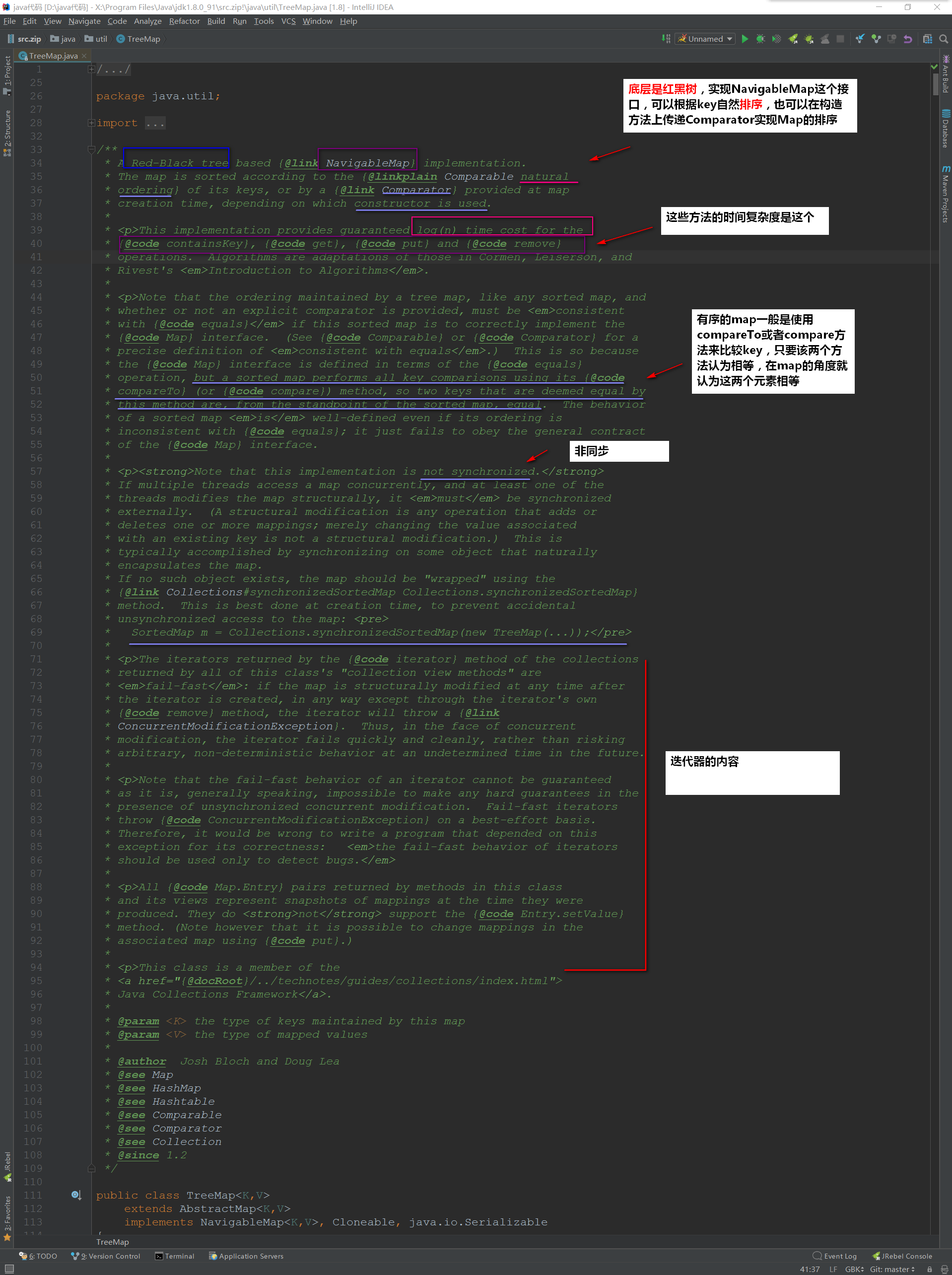
接着我们来看看类继承图:
在注释中提到的要点,我来总结一下:
- TreeMap实现了NavigableMap接口,而NavigableMap接口继承着SortedMap接口,致使我们的TreeMap是有序的!
- TreeMap底层是红黑树,它方法的时间复杂度都不会太高:log(n)~
- 非同步
- 使用Comparator或者Comparable来比较key是否相等与排序的问题~
对我而言,Comparator和Comparable我都忘得差不多了~~~下面就开始看TreeMap的源码来看看它是怎么实现的,并且回顾一下Comparator和Comparable的用法吧!
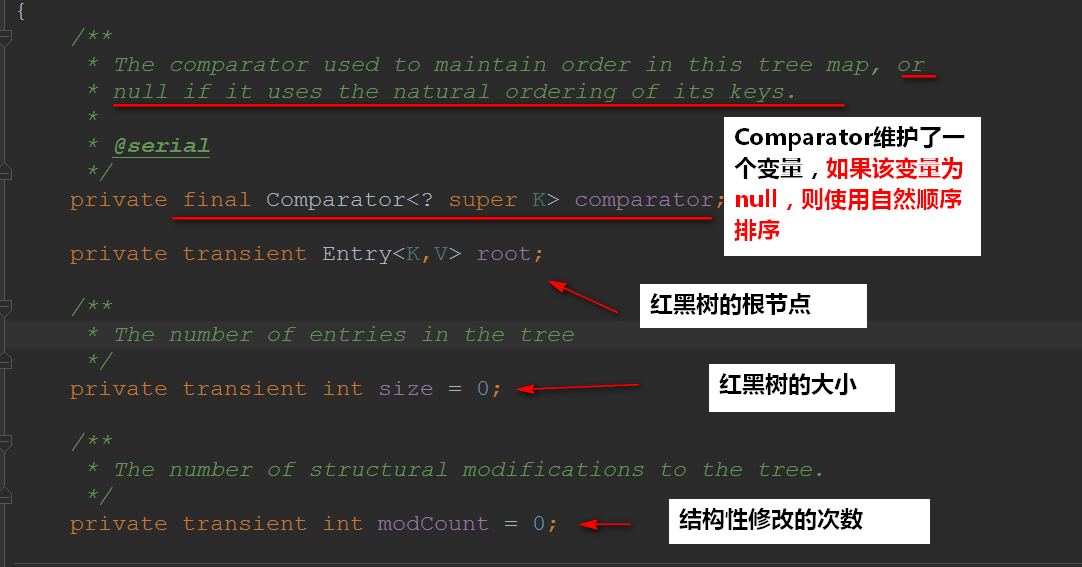
1.1TreeMap的域
1.2TreeMap构造方法
TreeMap的构造方法有4个:
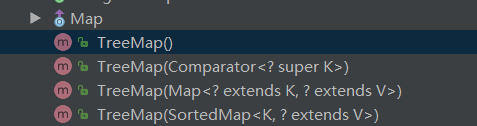
可以发现,TreeMap的构造方法大多数与comparator有关:
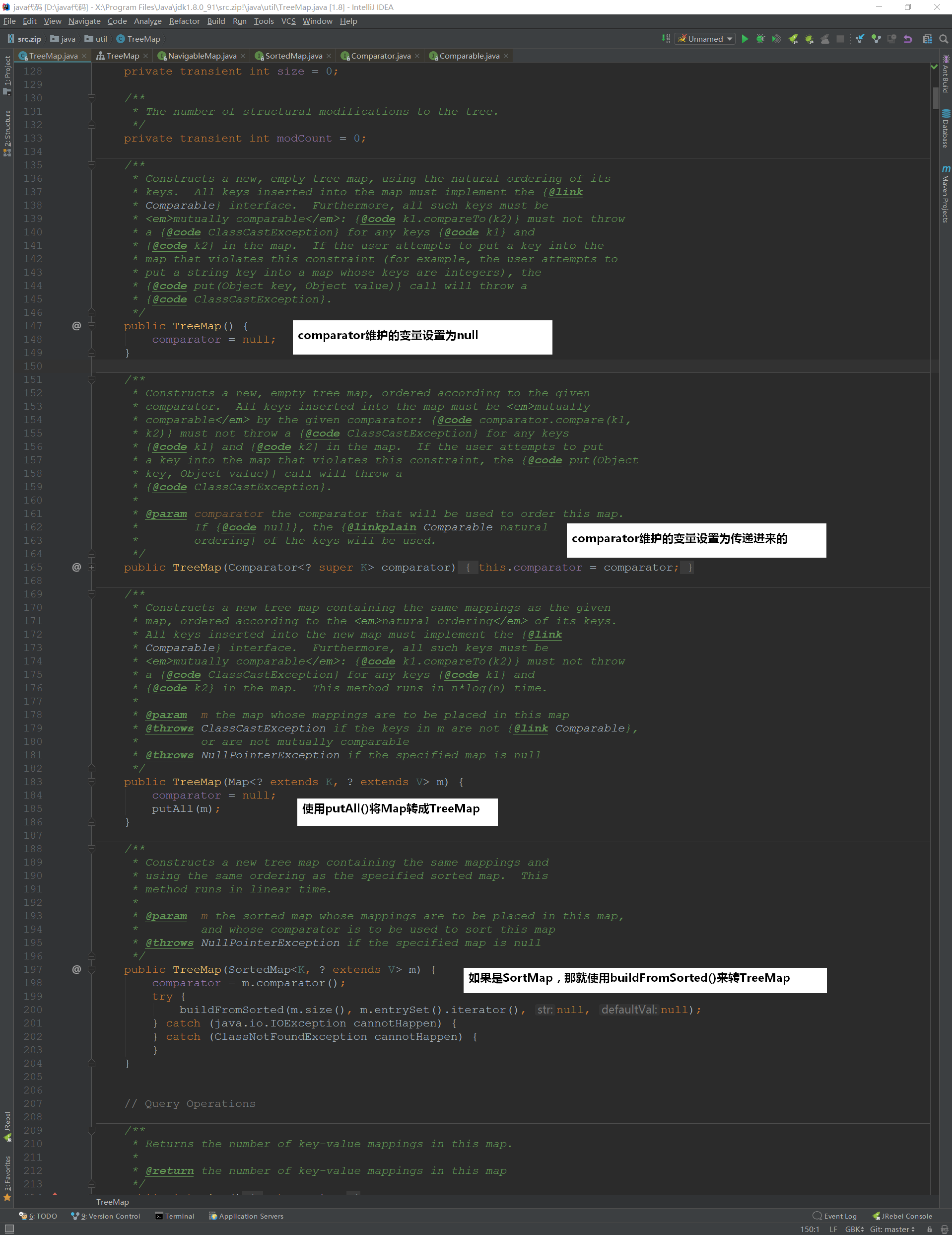
也就是顶部注释说的:TreeMap有序是通过Comparator来进行比较的,如果comparator为null,那么就使用自然顺序~
打个比方:
- 如果value是整数,自然顺序指的就是我们平常排序的顺序(1,2,3,4,5..)~
TreeMap<Integer, Integer> treeMap = new TreeMap<>(); treeMap.put(1, 5); treeMap.put(2, 4); treeMap.put(3, 3); treeMap.put(4, 2); treeMap.put(5, 1); for (Entry<Integer, Integer> entry : treeMap.entrySet()) { String s = entry.getKey() +"关注公众号:Java3y---->" + entry.getValue(); System.out.println(s); }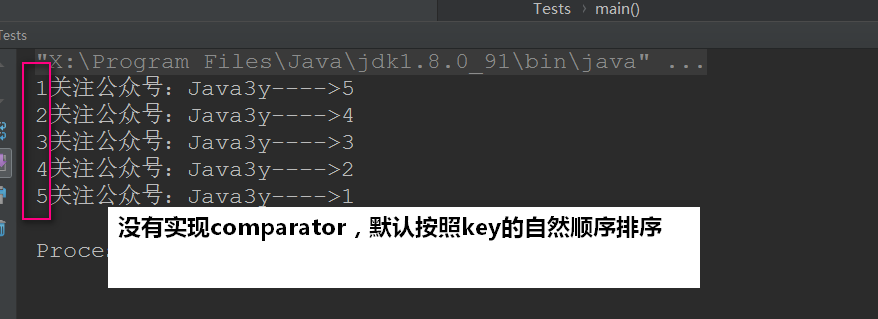
1.3put方法
我们来看看TreeMap的核心put方法,阅读它就可以获取不少关于TreeMap特性的东西了~
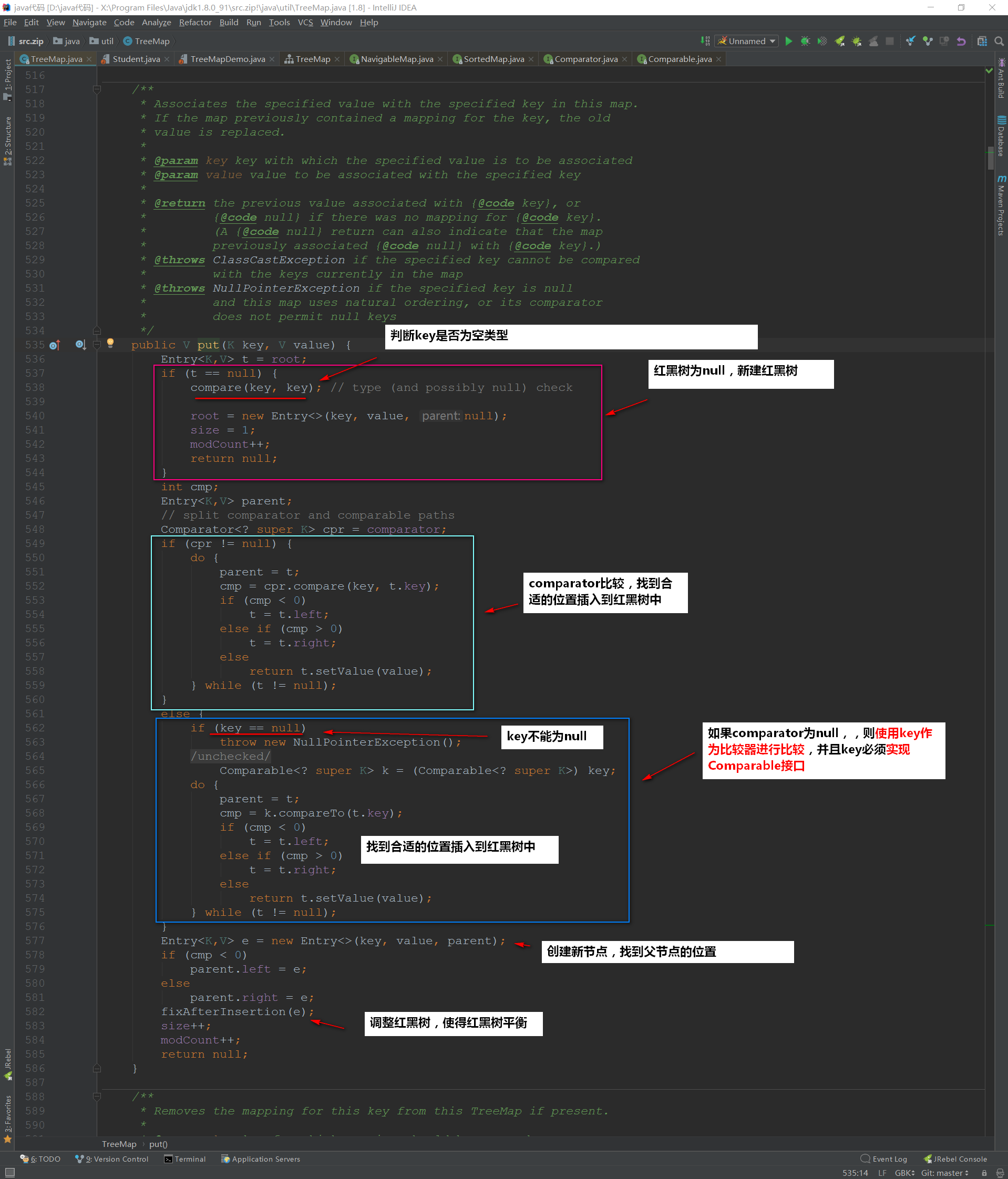
下面是compare(Object k1, Object k2)方法
/** * Compares two keys using the correct comparison method for this TreeMap. */ @SuppressWarnings("unchecked") final int compare(Object k1, Object k2) { return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2) : comparator.compare((K)k1, (K)k2); }如果我们设置key为null,会抛出异常的,就不执行下面的代码了。

1.4get方法
接下来我们来看看get方法的实现:
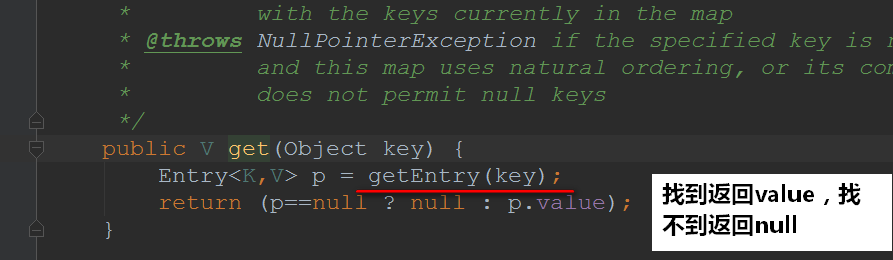
点进去getEntry()看看实现:
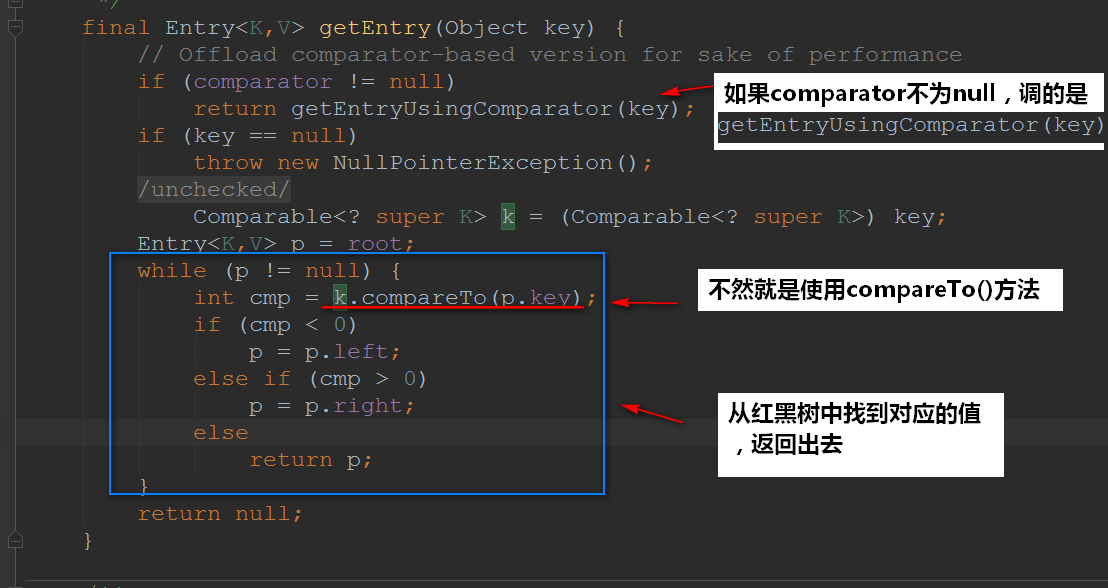
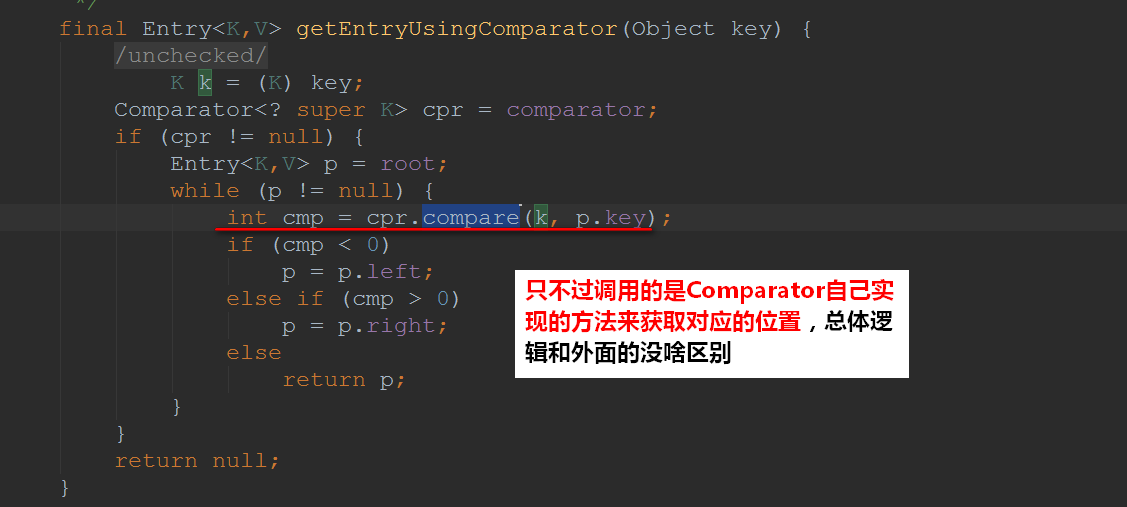
如果Comparator不为null,接下来我们进去看看getEntryUsingComparator(Object key),是怎么实现的
1.5remove方法
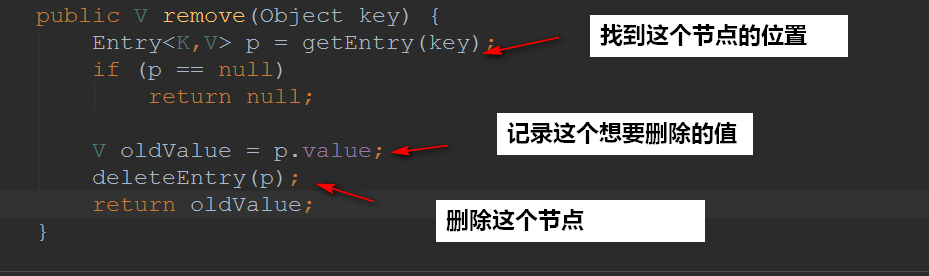
删除节点的时候调用的是deleteEntry(Entry<K,V> p)方法,这个方法主要是删除节点并且平衡红黑树
平衡红黑树的代码是比较复杂的,我就不说了,你们去看吧(反正我看不懂)....
1.6遍历方法
在看源码的时候可能不知道哪个是核心的遍历方法,因为Iterator有非常非常多~
此时,我们只需要debug一下看看,跟下去就好!


于是乎,我们可以找到:TreeMap遍历是使用EntryIterator这个内部类的
首先来看看EntryIterator的类结构图吧:
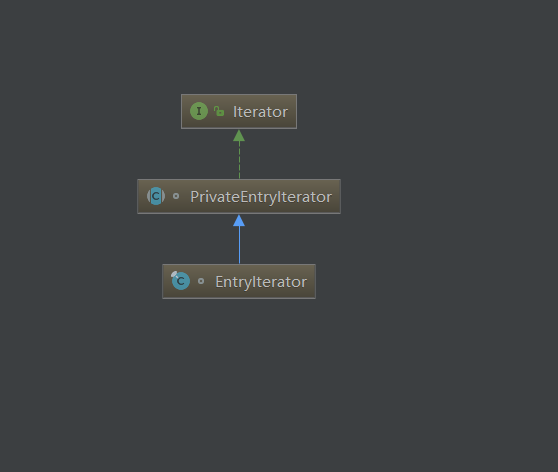
可以发现,EntryIterator大多的实现都是在父类中:
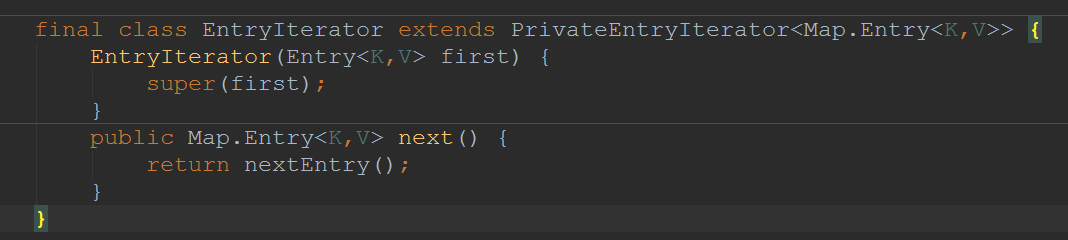
那接下来我们去看看PrivateEntryIterator比较重要的方法:
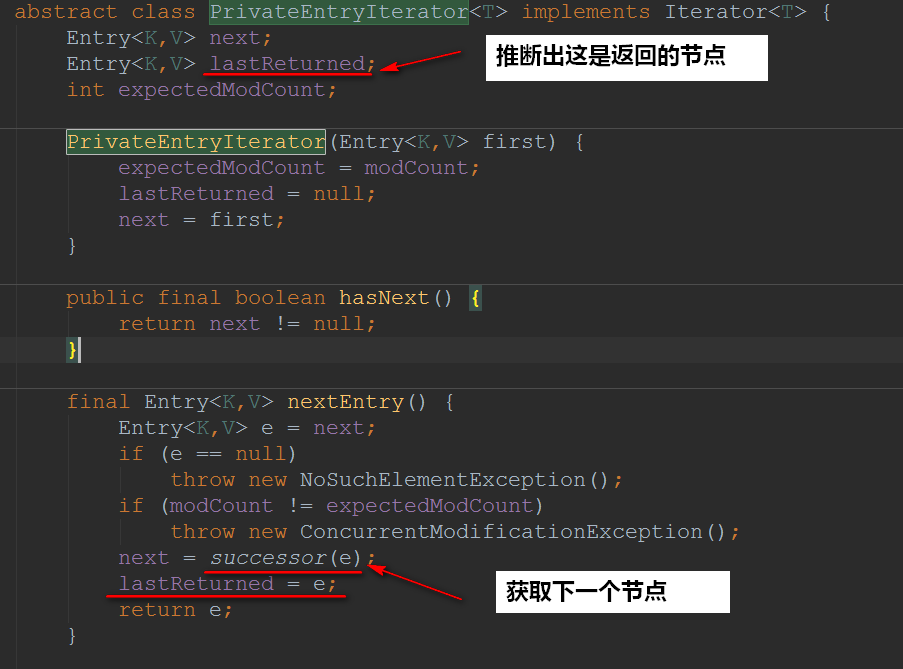
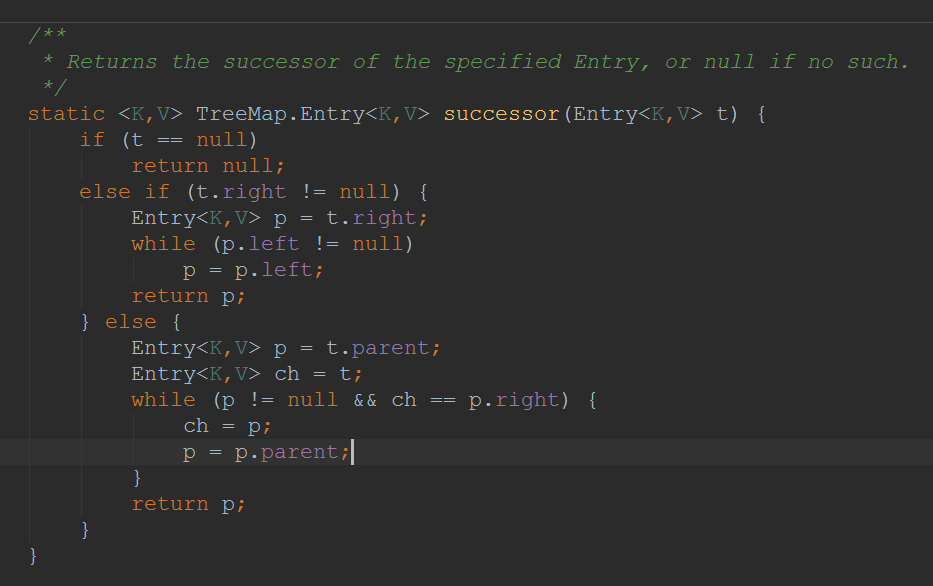
我们进去successor(e)方法看看实现:
successor 其实就是一个结点的 下一个结点,所谓 下一个,是按次序排序后的下一个结点。从代码中可以看出,如果右子树不为空,就返回右子树中最小结点。如果右子树为空,就要向上回溯了。在这种情况下,t 是以其为根的树的最后一个结点。如果它是其父结点的左孩子,那么父结点就是它的下一个结点,否则,t 就是以其父结点为根的树的最后一个结点,需要再次向上回溯。一直到 ch 是 p 的左孩子为止。
来源:https://blog.csdn.net/on_1y/article/details/27231855
二、总结
TreeMap底层是红黑树,能够实现该Map集合有序~
如果在构造方法中传递了Comparator对象,那么就会以Comparator对象的方法进行比较。否则,则使用Comparable的compareTo(T o)方法来比较。
- 值得说明的是:如果使用的是
compareTo(T o)方法来比较,key一定是不能为null,并且得实现了Comparable接口的。 - 即使是传入了Comparator对象,不用
compareTo(T o)方法来比较,key也是不能为null的
public static void main(String[] args) { TreeMap<Student, String> map = new TreeMap<Student, String>((o1, o2) -> { //主要条件 int num = o1.getAge() - o2.getAge(); //次要条件 int num2 = num == 0 ? o1.getName().compareTo(o2.getName()) : num; return num2; }); //创建学生对象 Student s1 = new Student("潘安", 30); Student s2 = new Student("柳下惠", 35); //添加元素进集合 map.put(s1, "宋朝"); map.put(s2, "元朝"); map.put(null, "汉朝"); //获取key集合 Set<Student> set = map.keySet(); //遍历key集合 for (Student student : set) { String value = map.get(student); System.out.println(student + "---------" + value); } }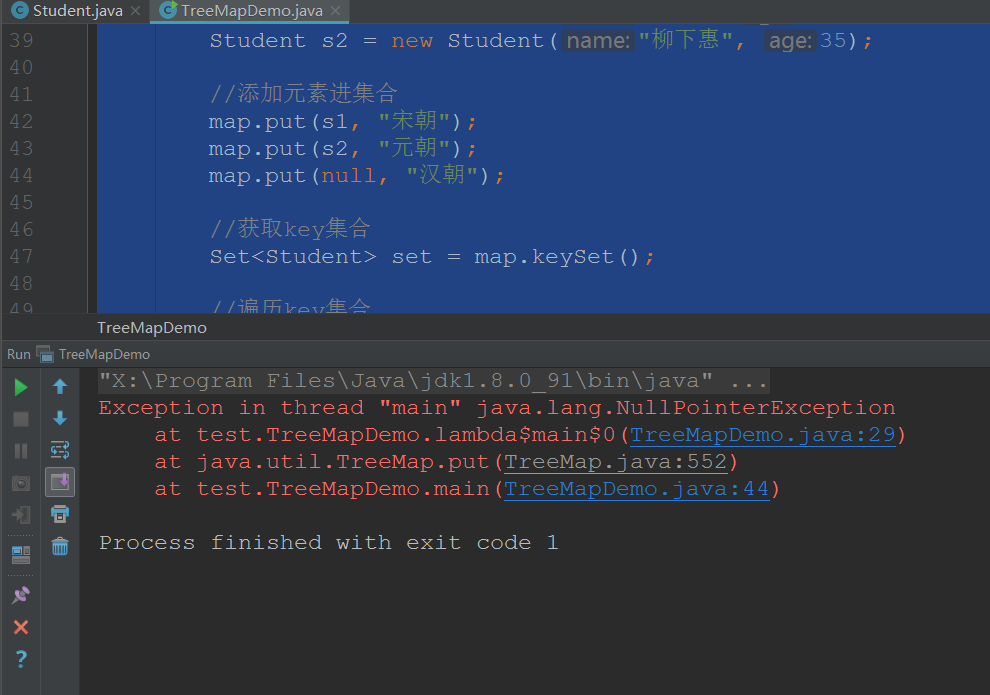
我们从源码中的很多地方中发现:Comparator和Comparable出现的频率是很高的,因为TreeMap实现有序要么就是外界传递进来Comparator对象,要么就使用默认key的Comparable接口(实现自然排序)
最后我就来总结一下TreeMap要点吧:
- 由于底层是红黑树,那么时间复杂度可以保证为log(n)
- key不能为null,为null为抛出NullPointException的
- 想要自定义比较,在构造方法中传入Comparator对象,否则使用key的自然排序来进行比较
- TreeMap非同步的,想要同步可以使用Collections来进行封装
参考资料:
- 《Core Java》
- https://blog.csdn.net/panweiwei1994/article/details/76555359
- https://www.cnblogs.com/chinajava/p/5808416.html

明天要是无意外的话,可能会写ConcurrentHashMap集合,敬请期待哦~~~~
文章的目录导航:https://zhongfucheng.bitcron.com/post/shou-ji/wen-zhang-dao-hang
更多的文章可往:文章的目录导航如果文章有错的地方欢迎指正,大家互相交流。习惯在微信看技术文章,想要获取更多的Java资源的同学,可以关注微信公众号:Java3y。为了大家方便,刚新建了一下qq群:742919422,大家也可以去交流交流。谢谢支持了!希望能多介绍给其他有需要的朋友
版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。