
前言
你将收获
Apify框架介绍和基本使用 如何创建父子进程以及父子进程通信 使用 手动实现控制爬虫最大并发数 截取整个网页图片的实现方案 nodejs第三方库和模块的使用 使用umi3 + antd4.0搭建爬虫前台界面
上图所示的就是我们要实现的爬虫平台, 我们可以输入指定网址来抓取该网站下的数据,并生成整个网页的快照.在抓取完之后我们可以下载数据和图片.网页右边是用户抓取的记录,方便二次利用或者备份.
正文
在开始文章之前,我们有必要了解爬虫的一些应用. 我们一般了解的爬虫, 多用来爬取网页数据, 捕获请求信息, 网页截图等,如下图:
当然爬虫的应用远远不止如此,我们还可以利用爬虫库做自动化测试,服务端渲染,自动化表单提交,测试谷歌扩展程序,性能诊断等. 任何语言实现的爬虫框架原理往往也大同小异, 接下来笔者将介绍基于nodejs实现的爬虫框架Apify以及用法,并通过一个实际的案例方便大家快速上手爬虫开发.
Apify框架介绍和基本使用
apify是一款用于 的可伸缩的web爬虫库。能通过无头(headless)Chrome和Puppeteer实现数据提取和** Web** 自动化作业的开发。它提供了管理和自动扩展无头Chrome / Puppeteer实例池的工具,支持维护目标URL的请求队列,并可将爬取结果存储到本地文件系统或云端。
我们安装和使用它非常简单, 官网上也有非常多的实例案例可以参考, 具体安装使用步骤如下:
安装
npm install apify --save 复制代码
使用Apify开始第一个案例
constApify =require('apify');
Apify.main(async() => {constrequestQueue =awaitApify.openRequestQueue();awaitrequestQueue.addRequest({ url:'https://www.iana.org/'});constpseudoUrls = [newApify.PseudoUrl('https://www.iana.org/[.*]')];constcrawler =newApify.PuppeteerCrawler({
requestQueue,
handlePageFunction:async({ request, page }) => {const =awaitpage. ();console.log(` of${request.url}:${ }`);awaitApify.utils.enqueue s({
page,
selector:'a',
pseudoUrls,
requestQueue,
});
},
maxRequestsPerCrawl:100,
maxConcurrency:10,
});awaitcrawler.run();
});复制代码
程序会自动打开浏览器并打开满足条件的url页面. 我们还可以使用它提供的cli工具实现更加便捷的爬虫服务管理等功能,感兴趣的朋友可以尝试一下.apify提供了很多有用的api供开发者使用, 如果想实现更加复杂的能力,可以研究一下,下图是官网api截图:
笔者要实现的爬虫主要使用了Apify集成的Puppeteer能力, 如果对Puppeteer不熟悉的可以去官网学习了解, 本文模块会一一列出项目使用的技术框架的文档地址.
如何创建父子进程以及父子进程通信
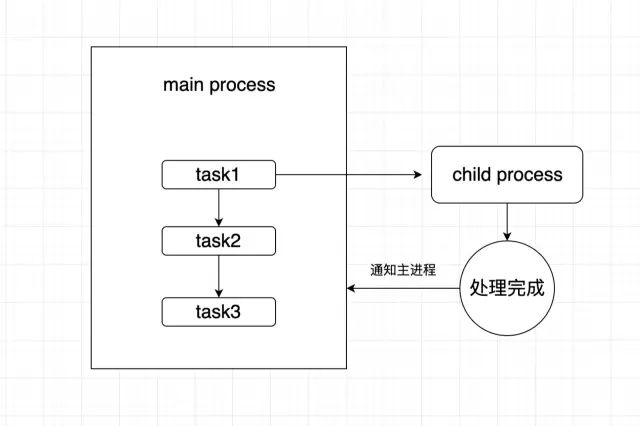
我们要想实现一个爬虫平台, 要考虑的一个关键问题就是爬虫任务的执行时机以及以何种方式执行. 因为爬取网页和截图需要等网页全部加载完成之后再处理, 这样才能保证数据的完整性, 所以我们可以认定它为一个耗时任务.
当我们使用nodejs作为后台服务器时, 由于nodejs本身是单线程的,所以当爬取请求传入nodejs时,nodejs不得不等待这个"耗时任务"完成才能进行其他请求的处理, 这样将会导致页面其他请求需要等待该任务执行结束才能继续进行, 所以为了更好的用户体验和流畅的响应,我们不得不考虑多进程处理. 好在nodejs设计支持子进程, 我们可以把爬虫这类耗时任务放入子进程中来处理,当子进程处理完成之后再通知主进程. 整个流程如下图所示:
// child.jsfunctioncomputedTotal(arr, cb) {// 耗时计算任务}// 与主进程通信// 监听主进程信号process.on('message', (msg) => {
computedTotal(bigDataArr, (flag) => {// 向主进程发送完成信号process.send(flag);
})
});// main.jsconst{ fork } =require('child_process');
app.use(async(ctx, next) => {if(ctx.url ==='/fetch') {constdata = ctx.request.body;// 通知子进程开始执行任务,并传入数据constres =awaitcreatePromisefork('./child.js', data)
}// 创建异步线程functioncreatePromisefork(childUrl, data) {// 加载子进程constres = fork(childUrl)// 通知子进程开始workdata && res.send(data)returnnewPromise(reslove => {
res.on('message', f => {
reslove(f)
})
})
}awaitnext()
})复制代码
使用 手动实现控制爬虫最大并发数
以上介绍的是要实现我们的爬虫应用需要考虑的技术问题, 接下来我们开始正式实现业务功能, 因为爬虫任务是在子进程中进行的,所以我们将在子进程代码中实现我们的爬虫功能.我们先来整理一下具体业务需求, 如下图:
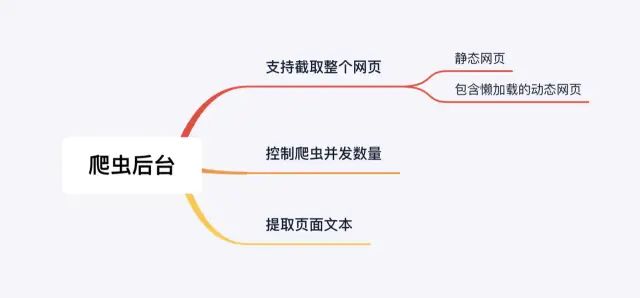
接下来我会先解决控制爬虫最大并发数这个问题, 之所以要解决这个问题, 是为了考虑爬虫性能问题, 我们不能一次性让爬虫爬取所有的网页,这样会开启很多并行进程来处理, 所以我们需要设计一个节流装置,来控制每次并发的数量, 当前一次的完成之后再进行下一批的页面抓取处理. 具体代码实现如下:
// 异步队列constqueue = []// 最大并发数constmax_parallel =6// 开始指针letstart =0for(leti =0; i < urls.length; i++) {// 添加异步队列queue.push(fetchPage(browser, i, urls[i]))if(i &&
(i+1) % max_parallel ===0|| i === (urls.length -1)) {// 每隔6条执行一次, 实现异步分流执行, 控制并发数awaitPromise.all(queue.slice(start, i+1))
start = i
}
}复制代码
以上代码即可实现每次同时抓取6个网页, 当第一次任务都结束之后才会执行下一批任务.代码中的urls指的是用户输入的url集合,fetchPage为抓取页面的爬虫逻辑, 笔者将其封装成了promise.
如何截取整个网页快照
我们都知道puppeteer截取网页图片只会截取加载完成的部分,对于一般的静态网站来说完全没有问题, 但是对于页面内容比较多的内容型或者电商网站, 基本上都采用了按需加载的模式, 所以一般手段截取下来的只是一部分页面, 或者截取的是图片还没加载出来的占位符,如下图所示:
// 滚动高度letscrollStep =1080;// 最大滚动高度, 防止无限加载的页面导致长效耗时任务letmax_height =30000;letm = {prevScroll:-1, curScroll:0}while(m.prevScroll !== m.curScroll && m.curScroll < max_height) {// 如果上一次滚动和本次滚动高度一样, 或者滚动高度大于设置的最高高度, 则停止截取m =awaitpage.evaluate((scrollStep) => {if(document.scrollingElement) {letprevScroll =document.scrollingElement.scrollTop;document.scrollingElement.scrollTop = prevScroll + scrollStep;letcurScroll =document.scrollingElement.scrollTopreturn{prevScroll, curScroll}
}
}, scrollStep);// 等待3秒后继续滚动页面, 为了让页面加载充分awaitsleep(3000);
}// 其他业务代码...// 截取网页快照,并设置图片质量和保存路径constscreenshot =awaitpage.screenshot({path:`static/${uid}.jpg`, fullPage:true, quality:70});复制代码
爬虫代码的其他部分因为不是核心重点,这里不一一举例, 我已经放到github上,大家可以交流研究.
有关如何提取网页文本, 也有现成的api可以调用, 大家可以选择适合自己业务的api去应用,笔者这里拿puppeteer的page.$eval来举例:
consttxt =awaitpage.$eval('body', el => {// el即为dom节点, 可以对body的子节点进行提取,分析return{...}
})复制代码
nodejs第三方库和模块的使用
koa 一款轻量级可扩展node框架 glob 使用强大的正则匹配模式遍历文件 koa2-cors 处理访问跨域问题 koa-static 创建静态服务目录 koa-body 获取请求体数据 有关如何使用这些模块实现一个完整的服务端应用, 笔者在代码里做了详细的说明, 这里就不一一讨论了. 具体代码如下:
constKoa =require('koa');const{ resolve } =require('path');conststaticServer =require('koa-static');constkoaBody =require('koa-body');constcors =require('koa2-cors');constlogger =require('koa-logger');constglob =require('glob');const{ fork } =require('child_process');constapp =newKoa();// 创建静态目录app.use(staticServer(resolve(__dirname,'./static')));
app.use(staticServer(resolve(__dirname,'./db')));
app.use(koaBody());
app.use(logger());constconfig = {
imgPath: resolve('./','static'),
txtPath: resolve('./','db')
}// 设置跨域app.use(cors({
origin:function(ctx) {if(ctx.url.indexOf('fetch') >-1) {return'*';// 允许来自所有域名请求}return'';// 这样就能只允许 http://localhost 这个域名的请求了},
exposeHeaders: ['WWW-Authenticate','Server-Authorization'],
maxAge:5,// 该字段可选,用来指定本次预检请求的有效期,单位为秒credentials:true,
allowMethods: ['GET','POST','PUT','DELETE'],
allowHeaders: ['Content-Type','Authorization','Accept','x-requested-with'],
}))// 创建异步线程functioncreatePromisefork(childUrl, data) {constres = fork(childUrl)
data && res.send(data)returnnewPromise(reslove => {
res.on('message', f => {
reslove(f)
})
})
}
app.use(async(ctx, next) => {if(ctx.url ==='/fetch') {constdata = ctx.request.body;constres =awaitcreatePromisefork('./child.js', data)// 获取文件路径consttxtUrls = [];letreg =/.*?(\d+)\.\w*$/;
glob.sync(`${config.txtPath}/*.*`).forEach(item => {if(reg.test(item)) {
txtUrls.push(item.replace(reg,'$1'))
}
})
ctx.body = {
state: res,
data: txtUrls,
msg: res ?'抓取完成':'抓取失败,原因可能是非法的url或者请求超时或者服务器内部错误'}
}awaitnext()
})
app.listen(80)复制代码
使用umi3 + antd4.0搭建爬虫前台界面
该爬虫平台的前端界面笔者采用umi3+antd4.0开发, 因为antd4.0相比之前版本确实体积和性能都提高了不少, 对于组件来说也做了更合理的拆分. 因为前端页面实现比较简单,整个前端代码使用hooks写不到200行,这里就不一一介绍了.大家可以在笔者的github上学习研究.
github项目地址: 基于Apify+node+react搭建的有点意思的爬虫平台
项目使用的技术文档地址
apify一款用于 的可伸缩的web爬虫库
Puppeteer
koa-- 基于nodejs平台的下一代web开发框架
继续阅读与本文标签相同的文章
Python爬虫框架Scrapy实战教程
爬虫浅谈:C#爬虫程序
-
只有它让我打消了对电动车各种“焦虑”,试驾小鹏G3 2020款
2026-05-14栏目: 教程
-
小鹏P7售价28.3-39.6万元,何小鹏称Model 3毫无竞争力
2026-05-14栏目: 教程
-
Vision M NEXT 概念车,宝马面向“未来”的产品张什么样?
2026-05-14栏目: 教程
-
大反转!谷歌态度开始“服软”,华为即将获得GMS许可
2026-05-14栏目: 教程
-
Python 超简单实现9种图像风格迁移
2026-05-14栏目: 教程